 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvocable APIs derived from NL2SQL datasets for LLM Tool-Calling Evaluation
Jun 12, 2025Large language models (LLMs) are routinely deployed as agentic systems, with access to tools that interact with live environments to accomplish tasks. In enterprise deployments these systems need to interact with API collections that can be extremely large and complex, often backed by databases. In order to create datasets with such characteristics, we explore how existing NL2SQL (Natural Language to SQL query) datasets can be used to automatically create NL2API datasets. Specifically, this work describes a novel data generation pipeline that exploits the syntax of SQL queries to construct a functionally equivalent sequence of API calls. We apply this pipeline to one of the largest NL2SQL datasets, BIRD-SQL to create a collection of over 2500 APIs that can be served as invocable tools or REST-endpoints. We pair natural language queries from BIRD-SQL to ground-truth API sequences based on this API pool. We use this collection to study the performance of 10 public LLMs and find that all models struggle to determine the right set of tools (consisting of tasks of intent detection, sequencing with nested function calls, and slot-filling). We find that models have extremely low task completion rates (7-47 percent - depending on the dataset) which marginally improves to 50 percent when models are employed as ReACT agents that interact with the live API environment. The best task completion rates are far below what may be required for effective general-use tool-calling agents, suggesting substantial scope for improvement in current state-of-the-art tool-calling LLMs. We also conduct detailed ablation studies, such as assessing the impact of the number of tools available as well as the impact of tool and slot-name obfuscation. We compare the performance of models on the original SQL generation tasks and find that current models are sometimes able to exploit SQL better than APIs.
NESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.
A Reliable Common-Sense Reasoning Socialbot Built Using LLMs and Goal-Directed ASP
Jul 26, 2024The development of large language models (LLMs), such as GPT, has enabled the construction of several socialbots, like ChatGPT, that are receiving a lot of attention for their ability to simulate a human conversation. However, the conversation is not guided by a goal and is hard to control. In addition, because LLMs rely more on pattern recognition than deductive reasoning, they can give confusing answers and have difficulty integrating multiple topics into a cohesive response. These limitations often lead the LLM to deviate from the main topic to keep the conversation interesting. We propose AutoCompanion, a socialbot that uses an LLM model to translate natural language into predicates (and vice versa) and employs commonsense reasoning based on Answer Set Programming (ASP) to hold a social conversation with a human. In particular, we rely on s(CASP), a goal-directed implementation of ASP as the backend. This paper presents the framework design and how an LLM is used to parse user messages and generate a response from the s(CASP) engine output. To validate our proposal, we describe (real) conversations in which the chatbot's goal is to keep the user entertained by talking about movies and books, and s(CASP) ensures (i) correctness of answers, (ii) coherence (and precision) during the conversation, which it dynamically regulates to achieve its specific purpose, and (iii) no deviation from the main topic.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
EXPLORER: Exploration-guided Reasoning for Textual Reinforcement Learning
Mar 15, 2024Text-based games (TBGs) have emerged as an important collection of NLP tasks, requiring reinforcement learning (RL) agents to combine natural language understanding with reasoning. A key challenge for agents attempting to solve such tasks is to generalize across multiple games and demonstrate good performance on both seen and unseen objects. Purely deep-RL-based approaches may perform well on seen objects; however, they fail to showcase the same performance on unseen objects. Commonsense-infused deep-RL agents may work better on unseen data; unfortunately, their policies are often not interpretable or easily transferable. To tackle these issues, in this paper, we present EXPLORER which is an exploration-guided reasoning agent for textual reinforcement learning. EXPLORER is neurosymbolic in nature, as it relies on a neural module for exploration and a symbolic module for exploitation. It can also learn generalized symbolic policies and perform well over unseen data. Our experiments show that EXPLORER outperforms the baseline agents on Text-World cooking (TW-Cooking) and Text-World Commonsense (TWC) games.
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Feb 23, 2024There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
Formally Specifying the High-Level Behavior of LLM-Based Agents
Oct 12, 2023
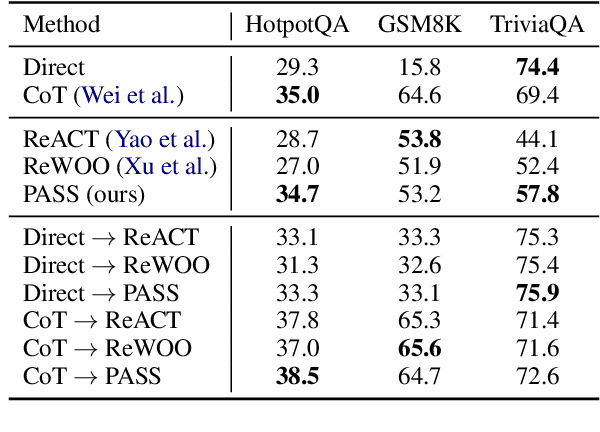
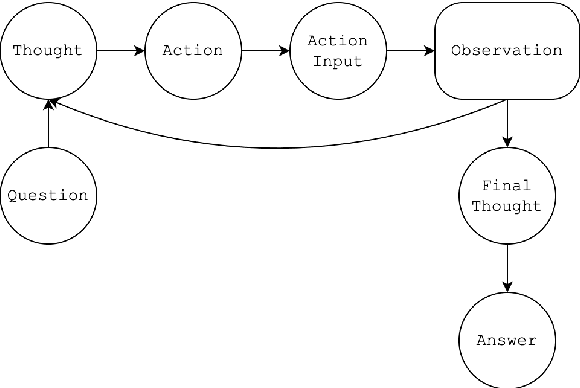
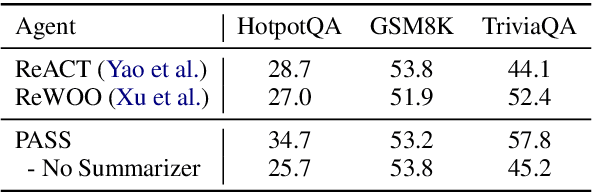
LLM-based agents have recently emerged as promising tools for solving challenging problems without the need for task-specific finetuned models that can be expensive to procure. Currently, the design and implementation of such agents is ad hoc, as the wide variety of tasks that LLM-based agents may be applied to naturally means there can be no one-size-fits-all approach to agent design. In this work we aim to alleviate the difficulty of designing and implementing new agents by proposing a minimalistic, high-level generation framework that simplifies the process of building agents. The framework we introduce allows the user to specify desired agent behaviors in Linear Temporal Logic (LTL). The declarative LTL specification is then used to construct a constrained decoder that guarantees the LLM will produce an output exhibiting the desired behavior. By designing our framework in this way, we obtain several benefits, including the ability to enforce complex agent behavior, the ability to formally validate prompt examples, and the ability to seamlessly incorporate content-focused logical constraints into generation. In particular, our declarative approach, in which the desired behavior is simply described without concern for how it should be implemented or enforced, enables rapid design, implementation and experimentation with different LLM-based agents. We demonstrate how the proposed framework can be used to implement recent LLM-based agents, and show how the guardrails our approach provides can lead to improvements in agent performance. In addition, we release our code for general use.
Disentangling and Operationalizing AI Fairness at LinkedIn
May 30, 2023Operationalizing AI fairness at LinkedIn's scale is challenging not only because there are multiple mutually incompatible definitions of fairness but also because determining what is fair depends on the specifics and context of the product where AI is deployed. Moreover, AI practitioners need clarity on what fairness expectations need to be addressed at the AI level. In this paper, we present the evolving AI fairness framework used at LinkedIn to address these three challenges. The framework disentangles AI fairness by separating out equal treatment and equitable product expectations. Rather than imposing a trade-off between these two commonly opposing interpretations of fairness, the framework provides clear guidelines for operationalizing equal AI treatment complemented with a product equity strategy. This paper focuses on the equal AI treatment component of LinkedIn's AI fairness framework, shares the principles that support it, and illustrates their application through a case study. We hope this paper will encourage other big tech companies to join us in sharing their approach to operationalizing AI fairness at scale, so that together we can keep advancing this constantly evolving field.
Automated Interactive Domain-Specific Conversational Agents that Understand Human Dialogs
Mar 17, 2023Achieving human-like communication with machines remains a classic, challenging topic in the field of Knowledge Representation and Reasoning and Natural Language Processing. These Large Language Models (LLMs) rely on pattern-matching rather than a true understanding of the semantic meaning of a sentence. As a result, they may generate incorrect responses. To generate an assuredly correct response, one has to "understand" the semantics of a sentence. To achieve this "understanding", logic-based (commonsense) reasoning methods such as Answer Set Programming (ASP) are arguably needed. In this paper, we describe the AutoConcierge system that leverages LLMs and ASP to develop a conversational agent that can truly "understand" human dialogs in restricted domains. AutoConcierge is focused on a specific domain-advising users about restaurants in their local area based on their preferences. AutoConcierge will interactively understand a user's utterances, identify the missing information in them, and request the user via a natural language sentence to provide it. Once AutoConcierge has determined that all the information has been received, it computes a restaurant recommendation based on the user-preferences it has acquired from the human user. AutoConcierge is based on our STAR framework developed earlier, which uses GPT-3 to convert human dialogs into predicates that capture the deep structure of the dialog's sentence. These predicates are then input into the goal-directed s(CASP) ASP system for performing commonsense reasoning. To the best of our knowledge, AutoConcierge is the first automated conversational agent that can realistically converse like a human and provide help to humans based on truly understanding human utterances.