 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Lifecycle Toolkit (ALTK): Reusable Middleware Components for Robust AI Agents
Mar 16, 2026As AI agents move from demos into enterprise deployments, their failure modes become consequential: a misinterpreted tool argument can corrupt production data, a silent reasoning error can go undetected until damage is done, and outputs that violate organizational policy can create legal or compliance risk. Yet, most agent frameworks leave builders to handle these failure modes ad hoc, resulting in brittle, one-off safeguards that are hard to reuse or maintain. We present the Agent Lifecycle Toolkit (ALTK), an open-source collection of modular middleware components that systematically address these gaps across the full agent lifecycle. Across the agent lifecycle, we identify opportunities to intervene and improve, namely, post-user-request, pre-LLM prompt conditioning, post-LLM output processing, pre-tool validation, post-tool result checking, and pre-response assembly. ALTK provides modular middleware that detects, repairs, and mitigates common failure modes. It offers consistent interfaces that fit naturally into existing pipelines. It is compatible with low-code and no-code tools such as the ContextForge MCP Gateway and Langflow. Finally, it significantly reduces the effort of building reliable, production-grade agents.
Kascade: A Practical Sparse Attention Method for Long-Context LLM Inference
Dec 18, 2025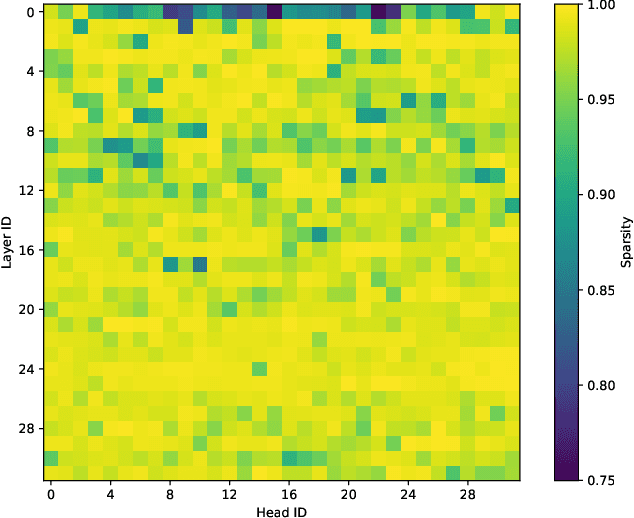



Attention is the dominant source of latency during long-context LLM inference, an increasingly popular workload with reasoning models and RAG. We propose Kascade, a training-free sparse attention method that leverages known observations such as 1) post-softmax attention is intrinsically sparse, and 2) the identity of high-weight keys is stable across nearby layers. Kascade computes exact Top-k indices in a small set of anchor layers, then reuses those indices in intermediate reuse layers. The anchor layers are selected algorithmically, via a dynamic-programming objective that maximizes cross-layer similarity over a development set, allowing easy deployment across models. The method incorporates efficient implementation constraints (e.g. tile-level operations), across both prefill and decode attention. The Top-k selection and reuse in Kascade is head-aware and we show in our experiments that this is critical for high accuracy. Kascade achieves up to 4.1x speedup in decode attention and 2.2x speedup in prefill attention over FlashAttention-3 baseline on H100 GPUs while closely matching dense attention accuracy on long-context benchmarks such as LongBench and AIME-24.
NESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.
ProtoNER: Few shot Incremental Learning for Named Entity Recognition using Prototypical Networks
Oct 03, 2023

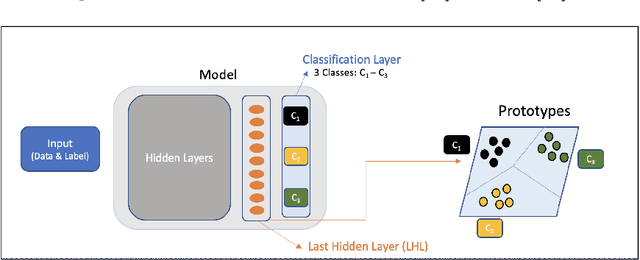
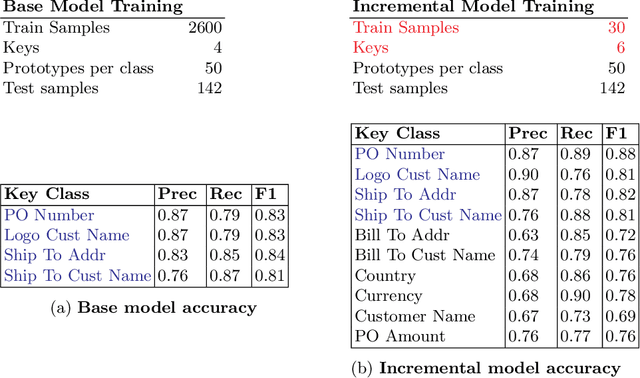
Key value pair (KVP) extraction or Named Entity Recognition(NER) from visually rich documents has been an active area of research in document understanding and data extraction domain. Several transformer based models such as LayoutLMv2, LayoutLMv3, and LiLT have emerged achieving state of the art results. However, addition of even a single new class to the existing model requires (a) re-annotation of entire training dataset to include this new class and (b) retraining the model again. Both of these issues really slow down the deployment of updated model. \\ We present \textbf{ProtoNER}: Prototypical Network based end-to-end KVP extraction model that allows addition of new classes to an existing model while requiring minimal number of newly annotated training samples. The key contributions of our model are: (1) No dependency on dataset used for initial training of the model, which alleviates the need to retain original training dataset for longer duration as well as data re-annotation which is very time consuming task, (2) No intermediate synthetic data generation which tends to add noise and results in model's performance degradation, and (3) Hybrid loss function which allows model to retain knowledge about older classes as well as learn about newly added classes.\\ Experimental results show that ProtoNER finetuned with just 30 samples is able to achieve similar results for the newly added classes as that of regular model finetuned with 2600 samples.
PoWER-BERT: Accelerating BERT inference for Classification Tasks
Jan 24, 2020
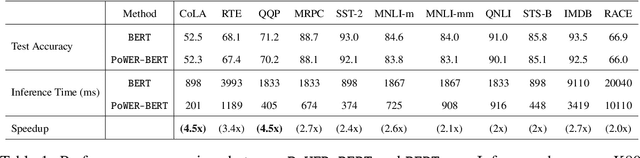
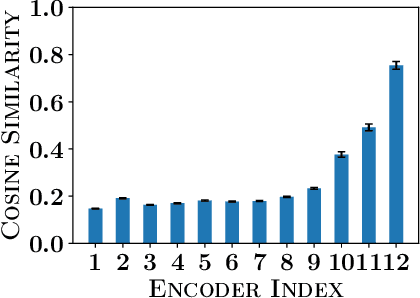
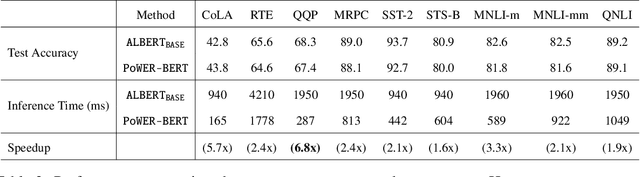
BERT has emerged as a popular model for natural language understanding. Given its compute intensive nature, even for inference, many recent studies have considered optimization of two important performance characteristics: model size and inference time. We consider classification tasks and propose a novel method, called PoWER-BERT, for improving the inference time for the BERT model without significant loss in the accuracy. The method works by eliminating word-vectors (intermediate vector outputs) from the encoder pipeline. We design a strategy for measuring the significance of the word-vectors based on the self-attention mechanism of the encoders which helps us identify the word-vectors to be eliminated. Experimental evaluation on the standard GLUE benchmark shows that PoWER-BERT achieves up to 4.5x reduction in inference time over BERT with < 1% loss in accuracy. We show that compared to the prior inference time reduction methods, PoWER-BERT offers better trade-off between accuracy and inference time. Lastly, we demonstrate that our scheme can also be used in conjunction with ALBERT (a highly compressed version of BERT) and can attain up to 6.8x factor reduction in inference time with < 1% loss in accuracy.
Efficient Inferencing of Compressed Deep Neural Networks
Nov 01, 2017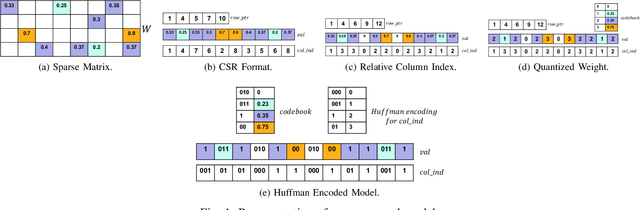
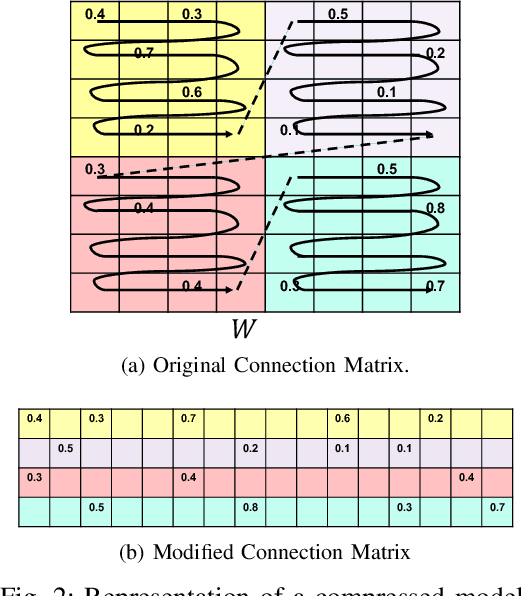
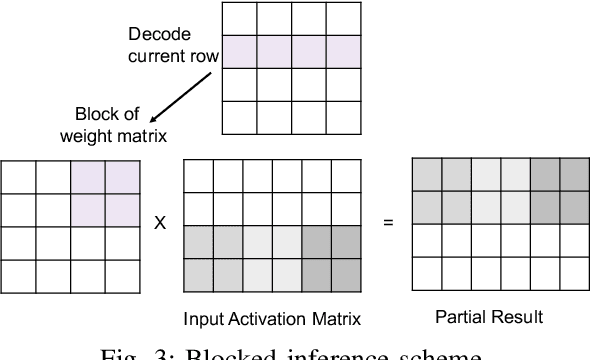
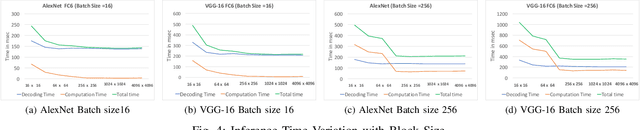
Large number of weights in deep neural networks makes the models difficult to be deployed in low memory environments such as, mobile phones, IOT edge devices as well as "inferencing as a service" environments on cloud. Prior work has considered reduction in the size of the models, through compression techniques like pruning, quantization, Huffman encoding etc. However, efficient inferencing using the compressed models has received little attention, specially with the Huffman encoding in place. In this paper, we propose efficient parallel algorithms for inferencing of single image and batches, under various memory constraints. Our experimental results show that our approach of using variable batch size for inferencing achieves 15-25\% performance improvement in the inference throughput for AlexNet, while maintaining memory and latency constraints.