 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoWER-BERT: Accelerating BERT inference for Classification Tasks
Paper and Code

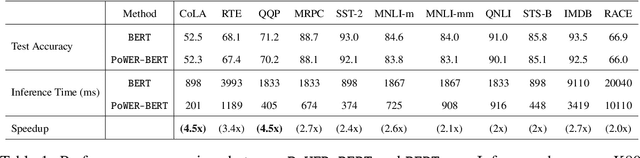
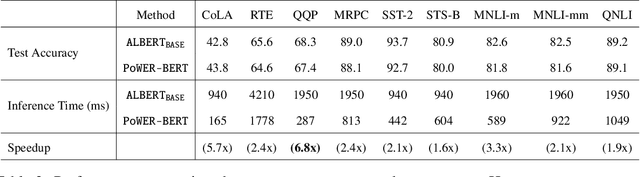
BERT has emerged as a popular model for natural language understanding. Given its compute intensive nature, even for inference, many recent studies have considered optimization of two important performance characteristics: model size and inference time. We consider classification tasks and propose a novel method, called PoWER-BERT, for improving the inference time for the BERT model without significant loss in the accuracy. The method works by eliminating word-vectors (intermediate vector outputs) from the encoder pipeline. We design a strategy for measuring the significance of the word-vectors based on the self-attention mechanism of the encoders which helps us identify the word-vectors to be eliminated. Experimental evaluation on the standard GLUE benchmark shows that PoWER-BERT achieves up to 4.5x reduction in inference time over BERT with < 1% loss in accuracy. We show that compared to the prior inference time reduction methods, PoWER-BERT offers better trade-off between accuracy and inference time. Lastly, we demonstrate that our scheme can also be used in conjunction with ALBERT (a highly compressed version of BERT) and can attain up to 6.8x factor reduction in inference time with < 1% loss in accuracy.