 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-RADS Synthetic Radiology Report Dataset and Head-to-Head Benchmarking of 41 Open-Weight and Proprietary Language Models
Jan 06, 2026Background: Reporting and Data Systems (RADS) standardize radiology risk communication but automated RADS assignment from narrative reports is challenging because of guideline complexity, output-format constraints, and limited benchmarking across RADS frameworks and model sizes. Purpose: To create RXL-RADSet, a radiologist-verified synthetic multi-RADS benchmark, and compare validity and accuracy of open-weight small language models (SLMs) with a proprietary model for RADS assignment. Materials and Methods: RXL-RADSet contains 1,600 synthetic radiology reports across 10 RADS (BI-RADS, CAD-RADS, GB-RADS, LI-RADS, Lung-RADS, NI-RADS, O-RADS, PI-RADS, TI-RADS, VI-RADS) and multiple modalities. Reports were generated by LLMs using scenario plans and simulated radiologist styles and underwent two-stage radiologist verification. We evaluated 41 quantized SLMs (12 families, 0.135-32B parameters) and GPT-5.2 under a fixed guided prompt. Primary endpoints were validity and accuracy; a secondary analysis compared guided versus zero-shot prompting. Results: Under guided prompting GPT-5.2 achieved 99.8% validity and 81.1% accuracy (1,600 predictions). Pooled SLMs (65,600 predictions) achieved 96.8% validity and 61.1% accuracy; top SLMs in the 20-32B range reached ~99% validity and mid-to-high 70% accuracy. Performance scaled with model size (inflection between <1B and >=10B) and declined with RADS complexity primarily due to classification difficulty rather than invalid outputs. Guided prompting improved validity (99.2% vs 96.7%) and accuracy (78.5% vs 69.6%) compared with zero-shot. Conclusion: RXL-RADSet provides a radiologist-verified multi-RADS benchmark; large SLMs (20-32B) can approach proprietary-model performance under guided prompting, but gaps remain for higher-complexity schemes.
HMR-ODTA: Online Diverse Task Allocation for a Team of Heterogeneous Mobile Robots
May 13, 2025
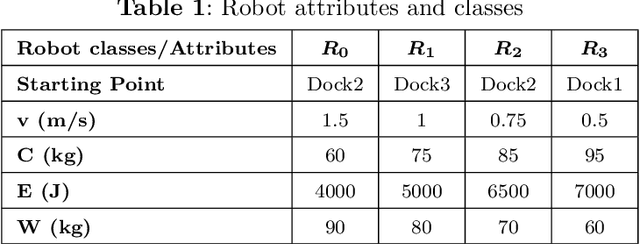
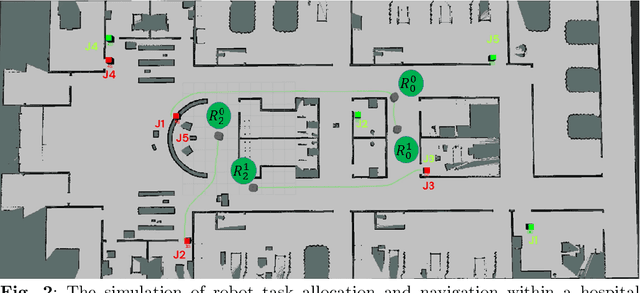

Coordinating time-sensitive deliveries in environments like hospitals poses a complex challenge, particularly when managing multiple online pickup and delivery requests within strict time windows using a team of heterogeneous robots. Traditional approaches fail to address dynamic rescheduling or diverse service requirements, typically restricting robots to single-task types. This paper tackles the Multi-Pickup and Delivery Problem with Time Windows (MPDPTW), where autonomous mobile robots are capable of handling varied service requests. The objective is to minimize late delivery penalties while maximizing task completion rates. To achieve this, we propose a novel framework leveraging a heterogeneous robot team and an efficient dynamic scheduling algorithm that supports dynamic task rescheduling. Users submit requests with specific time constraints, and our decentralized algorithm, Heterogeneous Mobile Robots Online Diverse Task Allocation (HMR-ODTA), optimizes task assignments to ensure timely service while addressing delays or task rejections. Extensive simulations validate the algorithm's effectiveness. For smaller task sets (40-160 tasks), penalties were reduced by nearly 63%, while for larger sets (160-280 tasks), penalties decreased by approximately 50%. These results highlight the algorithm's effectiveness in improving task scheduling and coordination in multi-robot systems, offering a robust solution for enhancing delivery performance in structured, time-critical environments.
ProtoNER: Few shot Incremental Learning for Named Entity Recognition using Prototypical Networks
Oct 03, 2023

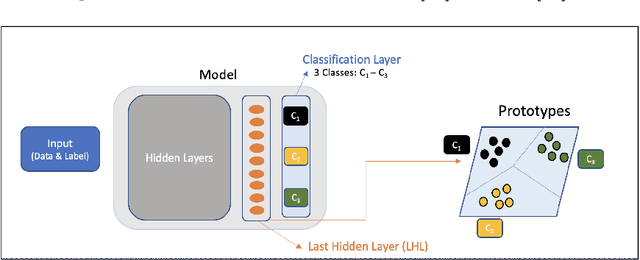
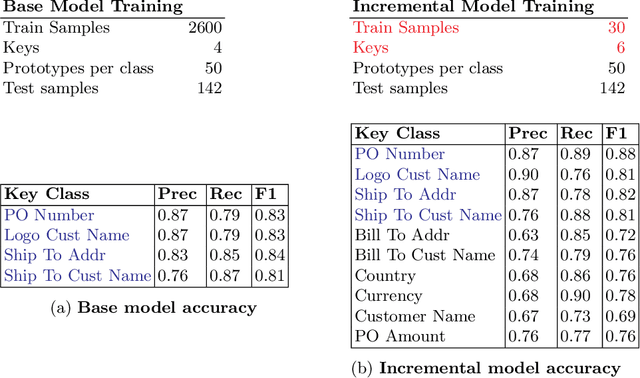
Key value pair (KVP) extraction or Named Entity Recognition(NER) from visually rich documents has been an active area of research in document understanding and data extraction domain. Several transformer based models such as LayoutLMv2, LayoutLMv3, and LiLT have emerged achieving state of the art results. However, addition of even a single new class to the existing model requires (a) re-annotation of entire training dataset to include this new class and (b) retraining the model again. Both of these issues really slow down the deployment of updated model. \\ We present \textbf{ProtoNER}: Prototypical Network based end-to-end KVP extraction model that allows addition of new classes to an existing model while requiring minimal number of newly annotated training samples. The key contributions of our model are: (1) No dependency on dataset used for initial training of the model, which alleviates the need to retain original training dataset for longer duration as well as data re-annotation which is very time consuming task, (2) No intermediate synthetic data generation which tends to add noise and results in model's performance degradation, and (3) Hybrid loss function which allows model to retain knowledge about older classes as well as learn about newly added classes.\\ Experimental results show that ProtoNER finetuned with just 30 samples is able to achieve similar results for the newly added classes as that of regular model finetuned with 2600 samples.
FLIPS: Federated Learning using Intelligent Participant Selection
Aug 07, 2023This paper presents the design and implementation of FLIPS, a middleware system to manage data and participant heterogeneity in federated learning (FL) training workloads. In particular, we examine the benefits of label distribution clustering on participant selection in federated learning. FLIPS clusters parties involved in an FL training job based on the label distribution of their data apriori, and during FL training, ensures that each cluster is equitably represented in the participants selected. FLIPS can support the most common FL algorithms, including FedAvg, FedProx, FedDyn, FedOpt and FedYogi. To manage platform heterogeneity and dynamic resource availability, FLIPS incorporates a straggler management mechanism to handle changing capacities in distributed, smart community applications. Privacy of label distributions, clustering and participant selection is ensured through a trusted execution environment (TEE). Our comprehensive empirical evaluation compares FLIPS with random participant selection, as well as two other "smart" selection mechanisms - Oort and gradient clustering using two real-world datasets, two different non-IID distributions and three common FL algorithms (FedYogi, FedProx and FedAvg). We demonstrate that FLIPS significantly improves convergence, achieving higher accuracy by 17 - 20 % with 20 - 60 % lower communication costs, and these benefits endure in the presence of straggler participants.
GVdoc: Graph-based Visual Document Classification
May 26, 2023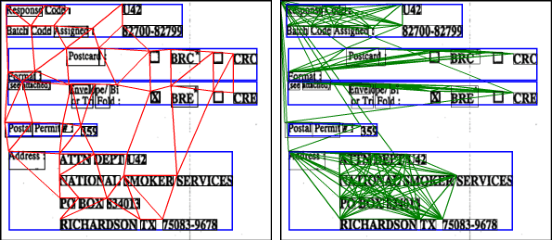
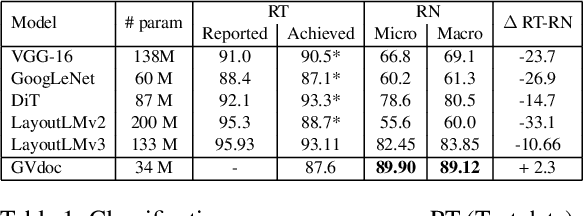


The robustness of a model for real-world deployment is decided by how well it performs on unseen data and distinguishes between in-domain and out-of-domain samples. Visual document classifiers have shown impressive performance on in-distribution test sets. However, they tend to have a hard time correctly classifying and differentiating out-of-distribution examples. Image-based classifiers lack the text component, whereas multi-modality transformer-based models face the token serialization problem in visual documents due to their diverse layouts. They also require a lot of computing power during inference, making them impractical for many real-world applications. We propose, GVdoc, a graph-based document classification model that addresses both of these challenges. Our approach generates a document graph based on its layout, and then trains a graph neural network to learn node and graph embeddings. Through experiments, we show that our model, even with fewer parameters, outperforms state-of-the-art models on out-of-distribution data while retaining comparable performance on the in-distribution test set.
Position Masking for Improved Layout-Aware Document Understanding
Sep 01, 2021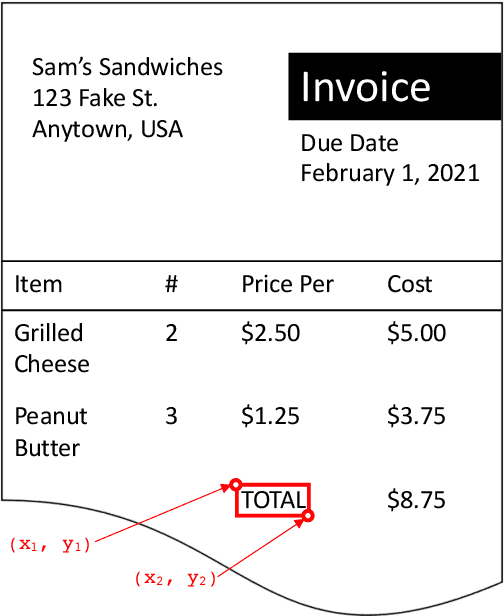
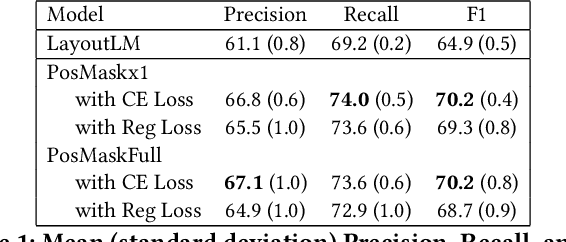
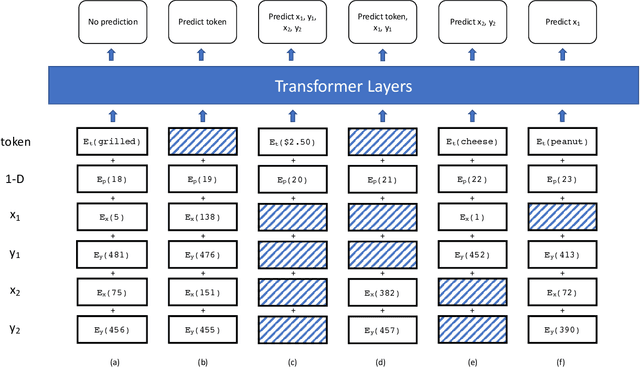
Natural language processing for document scans and PDFs has the potential to enormously improve the efficiency of business processes. Layout-aware word embeddings such as LayoutLM have shown promise for classification of and information extraction from such documents. This paper proposes a new pre-training task called that can improve performance of layout-aware word embeddings that incorporate 2-D position embeddings. We compare models pre-trained with only language masking against models pre-trained with both language masking and position masking, and we find that position masking improves performance by over 5% on a form understanding task.
Separation of Powers in Federated Learning
May 19, 2021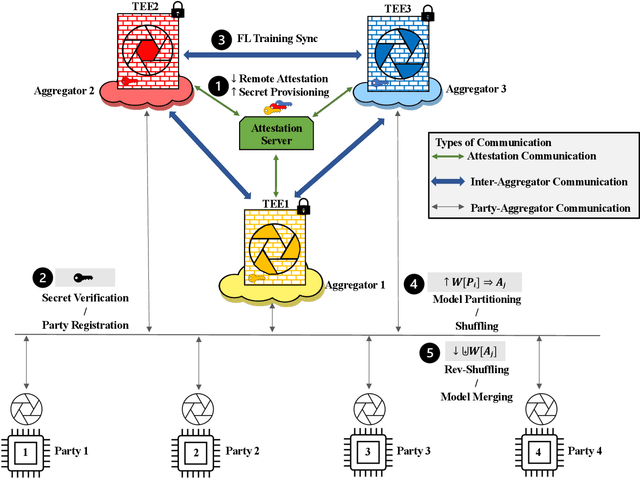
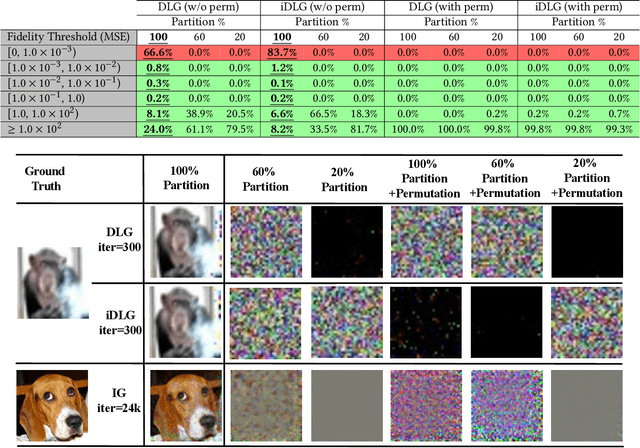
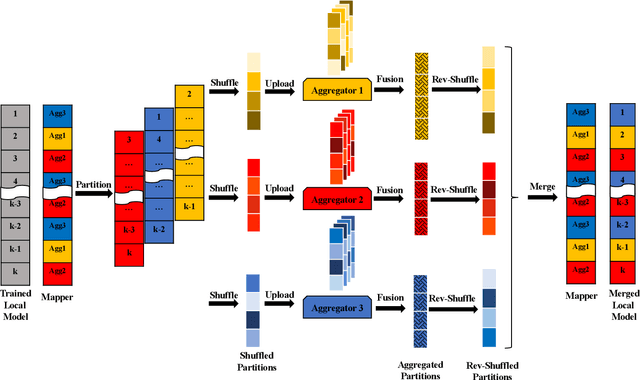

Federated Learning (FL) enables collaborative training among mutually distrusting parties. Model updates, rather than training data, are concentrated and fused in a central aggregation server. A key security challenge in FL is that an untrustworthy or compromised aggregation process might lead to unforeseeable information leakage. This challenge is especially acute due to recently demonstrated attacks that have reconstructed large fractions of training data from ostensibly "sanitized" model updates. In this paper, we introduce TRUDA, a new cross-silo FL system, employing a trustworthy and decentralized aggregation architecture to break down information concentration with regard to a single aggregator. Based on the unique computational properties of model-fusion algorithms, all exchanged model updates in TRUDA are disassembled at the parameter-granularity and re-stitched to random partitions designated for multiple TEE-protected aggregators. Thus, each aggregator only has a fragmentary and shuffled view of model updates and is oblivious to the model architecture. Our new security mechanisms can fundamentally mitigate training reconstruction attacks, while still preserving the final accuracy of trained models and keeping performance overheads low.
Adversarial training in communication constrained federated learning
Mar 01, 2021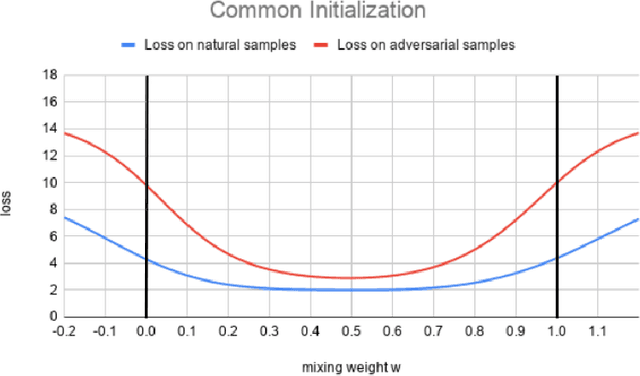
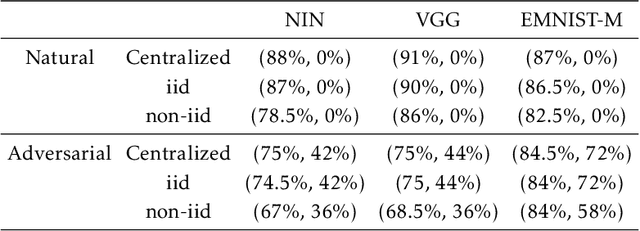
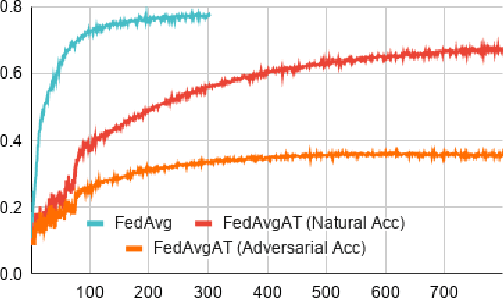
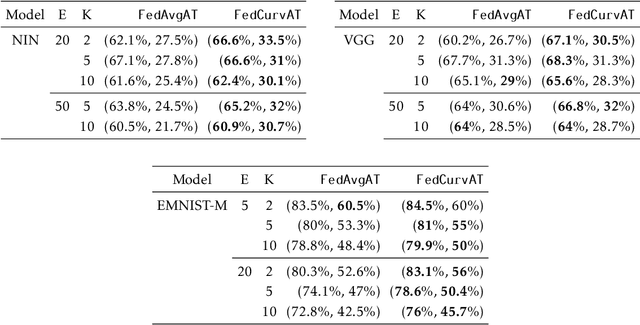
Federated learning enables model training over a distributed corpus of agent data. However, the trained model is vulnerable to adversarial examples, designed to elicit misclassification. We study the feasibility of using adversarial training (AT) in the federated learning setting. Furthermore, we do so assuming a fixed communication budget and non-iid data distribution between participating agents. We observe a significant drop in both natural and adversarial accuracies when AT is used in the federated setting as opposed to centralized training. We attribute this to the number of epochs of AT performed locally at the agents, which in turn effects (i) drift between local models; and (ii) convergence time (measured in number of communication rounds). Towards this end, we propose FedDynAT, a novel algorithm for performing AT in federated setting. Through extensive experimentation we show that FedDynAT significantly improves both natural and adversarial accuracy, as well as model convergence time by reducing the model drift.
MYSTIKO : : Cloud-Mediated, Private, Federated Gradient Descent
Dec 01, 2020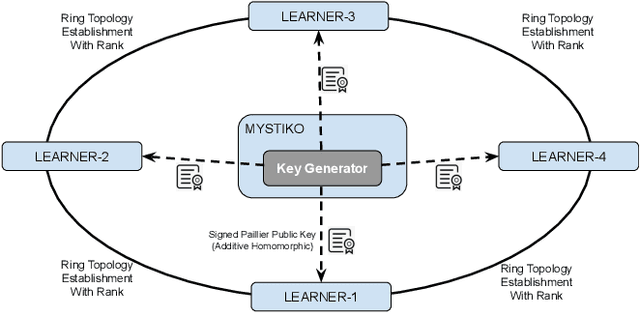
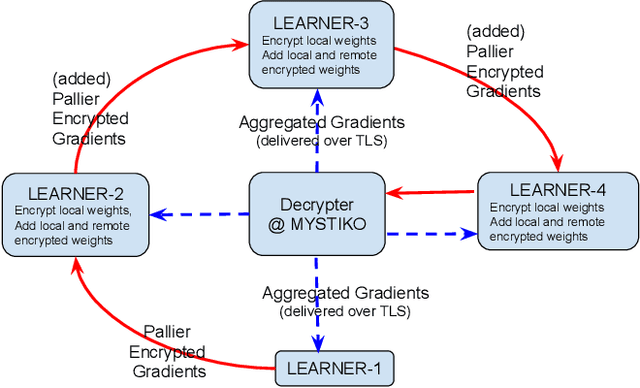

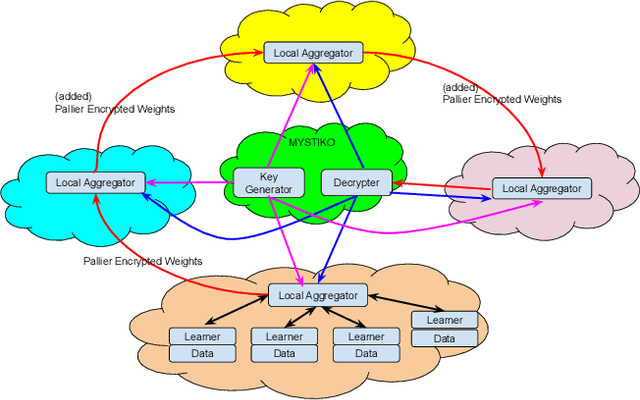
Federated learning enables multiple, distributed participants (potentially on different clouds) to collaborate and train machine/deep learning models by sharing parameters/gradients. However, sharing gradients, instead of centralizing data, may not be as private as one would expect. Reverse engineering attacks on plaintext gradients have been demonstrated to be practically feasible. Existing solutions for differentially private federated learning, while promising, lead to less accurate models and require nontrivial hyperparameter tuning. In this paper, we examine the use of additive homomorphic encryption (specifically the Paillier cipher) to design secure federated gradient descent techniques that (i) do not require addition of statistical noise or hyperparameter tuning, (ii) does not alter the final accuracy or utility of the final model, (iii) ensure that the plaintext model parameters/gradients of a participant are never revealed to any other participant or third party coordinator involved in the federated learning job, (iv) minimize the trust placed in any third party coordinator and (v) are efficient, with minimal overhead, and cost effective.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020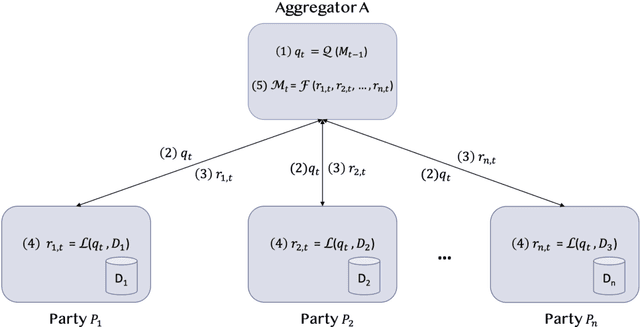
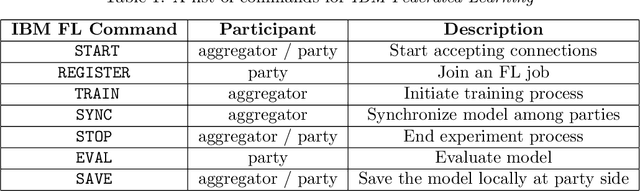
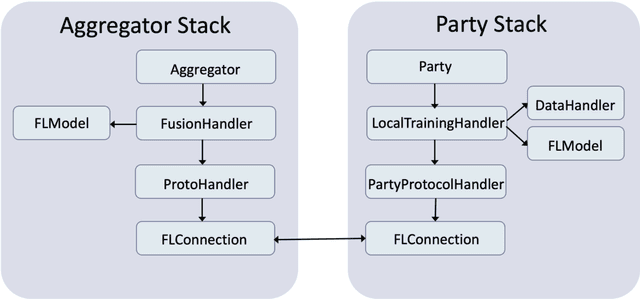
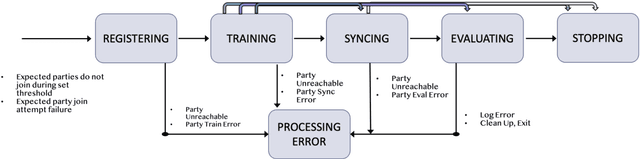
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.