 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKERL: Knowledge-Enhanced Personalized Recipe Recommendation using Large Language Models
May 20, 2025

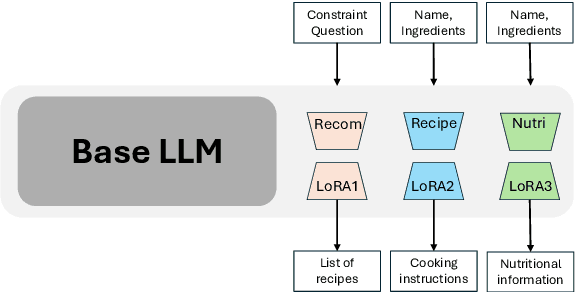

Recent advances in large language models (LLMs) and the abundance of food data have resulted in studies to improve food understanding using LLMs. Despite several recommendation systems utilizing LLMs and Knowledge Graphs (KGs), there has been limited research on integrating food related KGs with LLMs. We introduce KERL, a unified system that leverages food KGs and LLMs to provide personalized food recommendations and generates recipes with associated micro-nutritional information. Given a natural language question, KERL extracts entities, retrieves subgraphs from the KG, which are then fed into the LLM as context to select the recipes that satisfy the constraints. Next, our system generates the cooking steps and nutritional information for each recipe. To evaluate our approach, we also develop a benchmark dataset by curating recipe related questions, combined with constraints and personal preferences. Through extensive experiments, we show that our proposed KG-augmented LLM significantly outperforms existing approaches, offering a complete and coherent solution for food recommendation, recipe generation, and nutritional analysis. Our code and benchmark datasets are publicly available at https://github.com/mohbattharani/KERL.
LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
Aug 29, 2024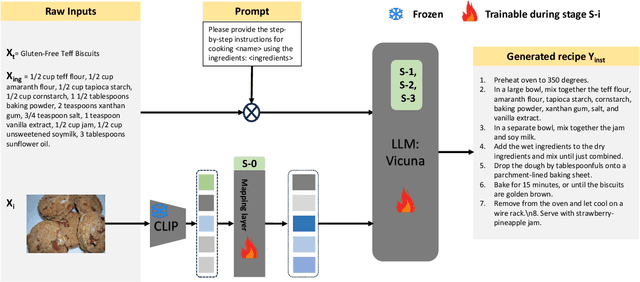



In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.
GVdoc: Graph-based Visual Document Classification
May 26, 2023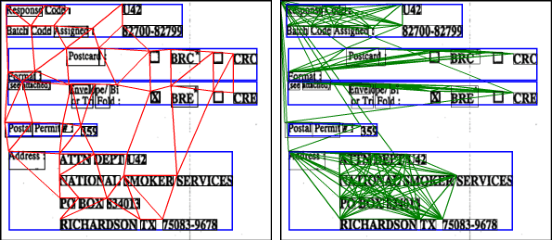
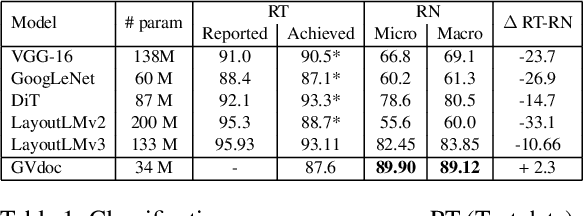


The robustness of a model for real-world deployment is decided by how well it performs on unseen data and distinguishes between in-domain and out-of-domain samples. Visual document classifiers have shown impressive performance on in-distribution test sets. However, they tend to have a hard time correctly classifying and differentiating out-of-distribution examples. Image-based classifiers lack the text component, whereas multi-modality transformer-based models face the token serialization problem in visual documents due to their diverse layouts. They also require a lot of computing power during inference, making them impractical for many real-world applications. We propose, GVdoc, a graph-based document classification model that addresses both of these challenges. Our approach generates a document graph based on its layout, and then trains a graph neural network to learn node and graph embeddings. Through experiments, we show that our model, even with fewer parameters, outperforms state-of-the-art models on out-of-distribution data while retaining comparable performance on the in-distribution test set.