 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVdoc: Graph-based Visual Document Classification
May 26, 2023
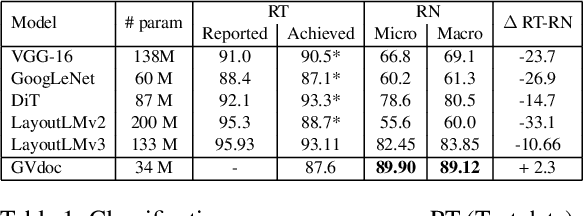


The robustness of a model for real-world deployment is decided by how well it performs on unseen data and distinguishes between in-domain and out-of-domain samples. Visual document classifiers have shown impressive performance on in-distribution test sets. However, they tend to have a hard time correctly classifying and differentiating out-of-distribution examples. Image-based classifiers lack the text component, whereas multi-modality transformer-based models face the token serialization problem in visual documents due to their diverse layouts. They also require a lot of computing power during inference, making them impractical for many real-world applications. We propose, GVdoc, a graph-based document classification model that addresses both of these challenges. Our approach generates a document graph based on its layout, and then trains a graph neural network to learn node and graph embeddings. Through experiments, we show that our model, even with fewer parameters, outperforms state-of-the-art models on out-of-distribution data while retaining comparable performance on the in-distribution test set.
Position Masking for Improved Layout-Aware Document Understanding
Sep 01, 2021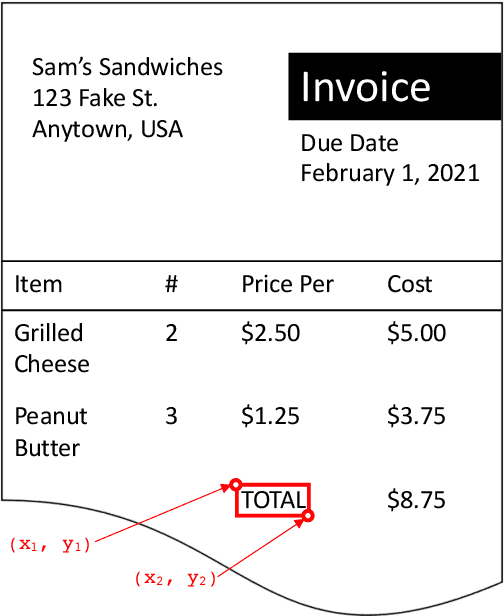
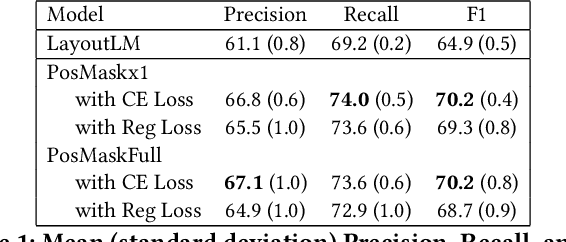
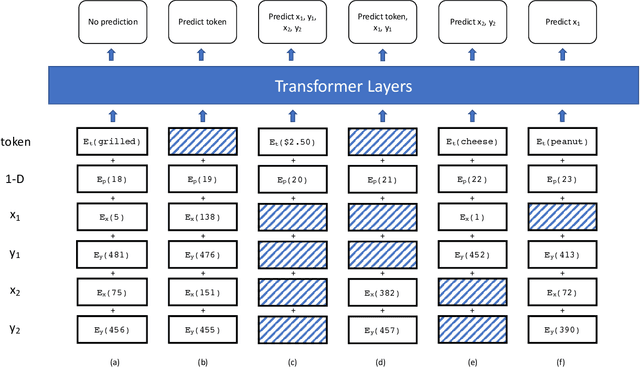
Natural language processing for document scans and PDFs has the potential to enormously improve the efficiency of business processes. Layout-aware word embeddings such as LayoutLM have shown promise for classification of and information extraction from such documents. This paper proposes a new pre-training task called that can improve performance of layout-aware word embeddings that incorporate 2-D position embeddings. We compare models pre-trained with only language masking against models pre-trained with both language masking and position masking, and we find that position masking improves performance by over 5% on a form understanding task.
Improving Text-to-SQL Evaluation Methodology
Jun 23, 2018

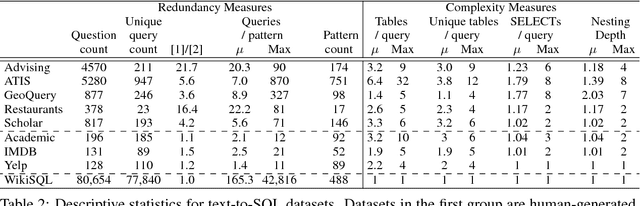

To be informative, an evaluation must measure how well systems generalize to realistic unseen data. We identify limitations of and propose improvements to current evaluations of text-to-SQL systems. First, we compare human-generated and automatically generated questions, characterizing properties of queries necessary for real-world applications. To facilitate evaluation on multiple datasets, we release standardized and improved versions of seven existing datasets and one new text-to-SQL dataset. Second, we show that the current division of data into training and test sets measures robustness to variations in the way questions are asked, but only partially tests how well systems generalize to new queries; therefore, we propose a complementary dataset split for evaluation of future work. Finally, we demonstrate how the common practice of anonymizing variables during evaluation removes an important challenge of the task. Our observations highlight key difficulties, and our methodology enables effective measurement of future development.