 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Clustering with Associative Memories
Jan 02, 2026Deep clustering - joint representation learning and latent space clustering - is a well studied problem especially in computer vision and text processing under the deep learning framework. While the representation learning is generally differentiable, clustering is an inherently discrete optimization task, requiring various approximations and regularizations to fit in a standard differentiable pipeline. This leads to a somewhat disjointed representation learning and clustering. In this work, we propose a novel loss function utilizing energy-based dynamics via Associative Memories to formulate a new deep clustering method, DCAM, which ties together the representation learning and clustering aspects more intricately in a single objective. Our experiments showcase the advantage of DCAM, producing improved clustering quality for various architecture choices (convolutional, residual or fully-connected) and data modalities (images or text).
Memorization to Generalization: Emergence of Diffusion Models from Associative Memory
May 27, 2025



Hopfield networks are associative memory (AM) systems, designed for storing and retrieving patterns as local minima of an energy landscape. In the classical Hopfield model, an interesting phenomenon occurs when the amount of training data reaches its critical memory load $- spurious\,\,states$, or unintended stable points, emerge at the end of the retrieval dynamics, leading to incorrect recall. In this work, we examine diffusion models, commonly used in generative modeling, from the perspective of AMs. The training phase of diffusion model is conceptualized as memory encoding (training data is stored in the memory). The generation phase is viewed as an attempt of memory retrieval. In the small data regime the diffusion model exhibits a strong memorization phase, where the network creates distinct basins of attraction around each sample in the training set, akin to the Hopfield model below the critical memory load. In the large data regime, a different phase appears where an increase in the size of the training set fosters the creation of new attractor states that correspond to manifolds of the generated samples. Spurious states appear at the boundary of this transition and correspond to emergent attractor states, which are absent in the training set, but, at the same time, have distinct basins of attraction around them. Our findings provide: a novel perspective on the memorization-generalization phenomenon in diffusion models via the lens of AMs, theoretical prediction of existence of spurious states, empirical validation of this prediction in commonly-used diffusion models.
Multi-Sense Embeddings for Language Models and Knowledge Distillation
Apr 08, 2025Transformer-based large language models (LLMs) rely on contextual embeddings which generate different (continuous) representations for the same token depending on its surrounding context. Nonetheless, words and tokens typically have a limited number of senses (or meanings). We propose multi-sense embeddings as a drop-in replacement for each token in order to capture the range of their uses in a language. To construct a sense embedding dictionary, we apply a clustering algorithm to embeddings generated by an LLM and consider the cluster centers as representative sense embeddings. In addition, we propose a novel knowledge distillation method that leverages the sense dictionary to learn a smaller student model that mimics the senses from the much larger base LLM model, offering significant space and inference time savings, while maintaining competitive performance. Via thorough experiments on various benchmarks, we showcase the effectiveness of our sense embeddings and knowledge distillation approach. We share our code at https://github.com/Qitong-Wang/SenseDict
FLAG: Financial Long Document Classification via AMR-based GNN
Oct 02, 2024



The advent of large language models (LLMs) has initiated much research into their various financial applications. However, in applying LLMs on long documents, semantic relations are not explicitly incorporated, and a full or arbitrarily sparse attention operation is employed. In recent years, progress has been made in Abstract Meaning Representation (AMR), which is a graph-based representation of text to preserve its semantic relations. Since AMR can represent semantic relationships at a deeper level, it can be beneficially utilized by graph neural networks (GNNs) for constructing effective document-level graph representations built upon LLM embeddings to predict target metrics in the financial domain. We propose FLAG: Financial Long document classification via AMR-based GNN, an AMR graph based framework to generate document-level embeddings for long financial document classification. We construct document-level graphs from sentence-level AMR graphs, endow them with specialized LLM word embeddings in the financial domain, apply a deep learning mechanism that utilizes a GNN, and examine the efficacy of our AMR-based approach in predicting labeled target data from long financial documents. Extensive experiments are conducted on a dataset of quarterly earnings calls transcripts of companies in various sectors of the economy, as well as on a corpus of more recent earnings calls of companies in the S&P 1500 Composite Index. We find that our AMR-based approach outperforms fine-tuning LLMs directly on text in predicting stock price movement trends at different time horizons in both datasets. Our work also outperforms previous work utilizing document graphs and GNNs for text classification.
Replacing Paths with Connection-Biased Attention for Knowledge Graph Completion
Oct 01, 2024



Knowledge graph (KG) completion aims to identify additional facts that can be inferred from the existing facts in the KG. Recent developments in this field have explored this task in the inductive setting, where at test time one sees entities that were not present during training; the most performant models in the inductive setting have employed path encoding modules in addition to standard subgraph encoding modules. This work similarly focuses on KG completion in the inductive setting, without the explicit use of path encodings, which can be time-consuming and introduces several hyperparameters that require costly hyperparameter optimization. Our approach uses a Transformer-based subgraph encoding module only; we introduce connection-biased attention and entity role embeddings into the subgraph encoding module to eliminate the need for an expensive and time-consuming path encoding module. Evaluations on standard inductive KG completion benchmark datasets demonstrate that our Connection-Biased Link Prediction (CBLiP) model has superior performance to models that do not use path information. Compared to models that utilize path information, CBLiP shows competitive or superior performance while being faster. Additionally, to show that the effectiveness of connection-biased attention and entity role embeddings also holds in the transductive setting, we compare CBLiP's performance on the relation prediction task in the transductive setting.
LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
Aug 29, 2024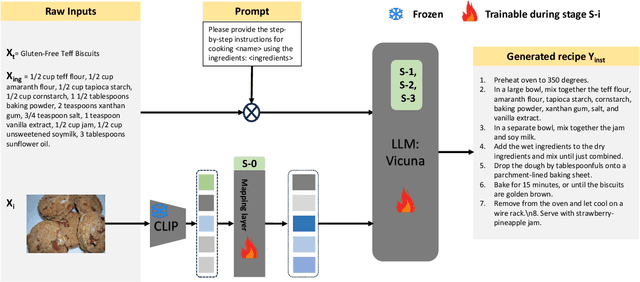



In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.
Triplet Interaction Improves Graph Transformers: Accurate Molecular Graph Learning with Triplet Graph Transformers
Feb 07, 2024



Graph transformers typically lack direct pair-to-pair communication, instead forcing neighboring pairs to exchange information via a common node. We propose the Triplet Graph Transformer (TGT) that enables direct communication between two neighboring pairs in a graph via novel triplet attention and aggregation mechanisms. TGT is applied to molecular property prediction by first predicting interatomic distances from 2D graphs and then using these distances for downstream tasks. A novel three-stage training procedure and stochastic inference further improve training efficiency and model performance. Our model achieves new state-of-the-art (SOTA) results on open challenge benchmarks PCQM4Mv2 and OC20 IS2RE. We also obtain SOTA results on QM9, MOLPCBA, and LIT-PCBA molecular property prediction benchmarks via transfer learning. We also demonstrate the generality of TGT with SOTA results on the traveling salesman problem (TSP).
End-to-end Differentiable Clustering with Associative Memories
Jun 05, 2023

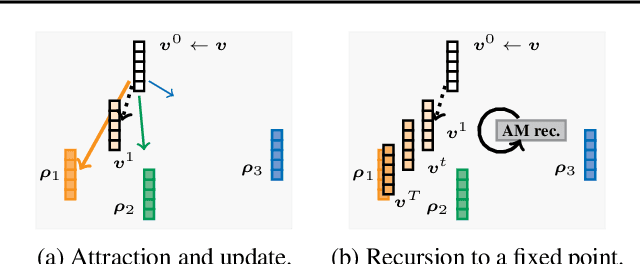

Clustering is a widely used unsupervised learning technique involving an intensive discrete optimization problem. Associative Memory models or AMs are differentiable neural networks defining a recursive dynamical system, which have been integrated with various deep learning architectures. We uncover a novel connection between the AM dynamics and the inherent discrete assignment necessary in clustering to propose a novel unconstrained continuous relaxation of the discrete clustering problem, enabling end-to-end differentiable clustering with AM, dubbed ClAM. Leveraging the pattern completion ability of AMs, we further develop a novel self-supervised clustering loss. Our evaluations on varied datasets demonstrate that ClAM benefits from the self-supervision, and significantly improves upon both the traditional Lloyd's k-means algorithm, and more recent continuous clustering relaxations (by upto 60% in terms of the Silhouette Coefficient).
The Information Pathways Hypothesis: Transformers are Dynamic Self-Ensembles
Jun 02, 2023



Transformers use the dense self-attention mechanism which gives a lot of flexibility for long-range connectivity. Over multiple layers of a deep transformer, the number of possible connectivity patterns increases exponentially. However, very few of these contribute to the performance of the network, and even fewer are essential. We hypothesize that there are sparsely connected sub-networks within a transformer, called information pathways which can be trained independently. However, the dynamic (i.e., input-dependent) nature of these pathways makes it difficult to prune dense self-attention during training. But the overall distribution of these pathways is often predictable. We take advantage of this fact to propose Stochastically Subsampled self-Attention (SSA) - a general-purpose training strategy for transformers that can reduce both the memory and computational cost of self-attention by 4 to 8 times during training while also serving as a regularization method - improving generalization over dense training. We show that an ensemble of sub-models can be formed from the subsampled pathways within a network, which can achieve better performance than its densely attended counterpart. We perform experiments on a variety of NLP, computer vision and graph learning tasks in both generative and discriminative settings to provide empirical evidence for our claims and show the effectiveness of the proposed method.
GVdoc: Graph-based Visual Document Classification
May 26, 2023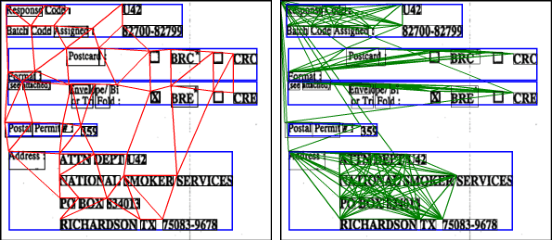
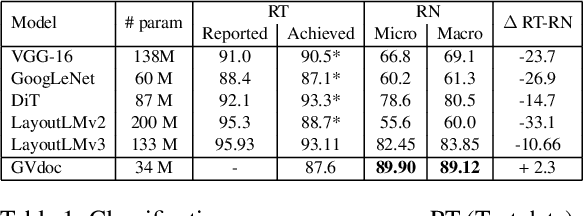


The robustness of a model for real-world deployment is decided by how well it performs on unseen data and distinguishes between in-domain and out-of-domain samples. Visual document classifiers have shown impressive performance on in-distribution test sets. However, they tend to have a hard time correctly classifying and differentiating out-of-distribution examples. Image-based classifiers lack the text component, whereas multi-modality transformer-based models face the token serialization problem in visual documents due to their diverse layouts. They also require a lot of computing power during inference, making them impractical for many real-world applications. We propose, GVdoc, a graph-based document classification model that addresses both of these challenges. Our approach generates a document graph based on its layout, and then trains a graph neural network to learn node and graph embeddings. Through experiments, we show that our model, even with fewer parameters, outperforms state-of-the-art models on out-of-distribution data while retaining comparable performance on the in-distribution test set.