 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"If You're Very Clever, No One Knows You've Used It": The Social Dynamics of Developing Generative AI Literacy in the Workplace
Feb 01, 2026Generative AI (GenAI) tools are rapidly transforming knowledge work, making AI literacy a critical priority for organizations. However, research on AI literacy lacks empirical insight into how knowledge workers' beliefs around GenAI literacy are shaped by the social dynamics of the workplace, and how workers learn to apply GenAI tools in these environments. To address this gap, we conducted in-depth interviews with 19 knowledge workers across multiple sectors to examine how they develop GenAI competencies in real-world professional contexts. We found that, while knowledge sharing from colleagues supported learning, the ability to remove cues indicating GenAI use was perceived as validation of domain expertise. These behaviours ultimately reduced opportunities for learning via knowledge sharing and undermined transparency. To advance workplace AI literacy, we argue for fostering open dialogue, increasing visibility of user-generated knowledge, and greater emphasis on the benefits of collaborative learning for navigating rapid technological developments.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
QoE-oriented Communication Service Provision for Annotation Rendering in Mobile Augmented Reality
Jan 13, 2025


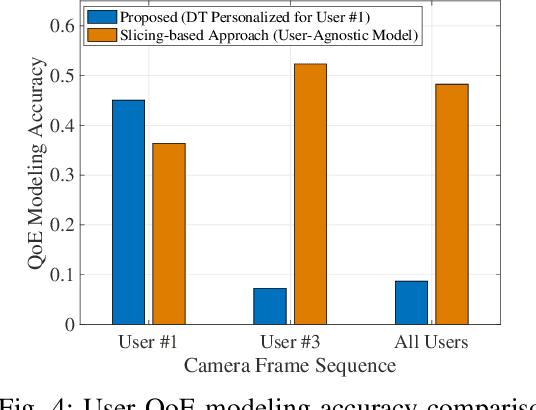
As mobile augmented reality (MAR) continues to evolve, future 6G networks will play a pivotal role in supporting immersive and personalized user experiences. In this paper, we address the communication service provision problem for annotation rendering in edge-assisted MAR, with the objective of optimizing spectrum resource utilization while ensuring the required quality of experience (QoE) for MAR users. To overcome the challenges of user-specific uplink data traffic patterns and the complex operational mechanisms of annotation rendering, we propose a digital twin (DT)-based approach. We first design a DT specifically tailored for MAR applications to learn key annotation rendering mechanisms, enabling the network controller to access MAR application-specific information. Then, we develop a DT based QoE modeling approach to capture the unique relationship between individual user QoE and spectrum resource demands. Finally, we propose a QoE-oriented resource allocation algorithm that decreases resource utilization compared to conventional net work slicing-based approaches. Simulation results demonstrate that our DT-based approach outperforms benchmark approaches in the accuracy and granularity of QoE modeling.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
FLAG: Financial Long Document Classification via AMR-based GNN
Oct 02, 2024



The advent of large language models (LLMs) has initiated much research into their various financial applications. However, in applying LLMs on long documents, semantic relations are not explicitly incorporated, and a full or arbitrarily sparse attention operation is employed. In recent years, progress has been made in Abstract Meaning Representation (AMR), which is a graph-based representation of text to preserve its semantic relations. Since AMR can represent semantic relationships at a deeper level, it can be beneficially utilized by graph neural networks (GNNs) for constructing effective document-level graph representations built upon LLM embeddings to predict target metrics in the financial domain. We propose FLAG: Financial Long document classification via AMR-based GNN, an AMR graph based framework to generate document-level embeddings for long financial document classification. We construct document-level graphs from sentence-level AMR graphs, endow them with specialized LLM word embeddings in the financial domain, apply a deep learning mechanism that utilizes a GNN, and examine the efficacy of our AMR-based approach in predicting labeled target data from long financial documents. Extensive experiments are conducted on a dataset of quarterly earnings calls transcripts of companies in various sectors of the economy, as well as on a corpus of more recent earnings calls of companies in the S&P 1500 Composite Index. We find that our AMR-based approach outperforms fine-tuning LLMs directly on text in predicting stock price movement trends at different time horizons in both datasets. Our work also outperforms previous work utilizing document graphs and GNNs for text classification.
Second-order Non-local Attention Networks for Person Re-identification
Aug 31, 2019



Recent efforts have shown promising results for person re-identification by designing part-based architectures to allow a neural network to learn discriminative representations from semantically coherent parts. Some efforts use soft attention to reallocate distant outliers to their most similar parts, while others adjust part granularity to incorporate more distant positions for learning the relationships. Others seek to generalize part-based methods by introducing a dropout mechanism on consecutive regions of the feature map to enhance distant region relationships. However, only few prior efforts model the distant or non-local positions of the feature map directly for the person re-ID task. In this paper, we propose a novel attention mechanism to directly model long-range relationships via second-order feature statistics. When combined with a generalized DropBlock module, our method performs equally to or better than state-of-the-art results for mainstream person re-identification datasets, including Market1501, CUHK03, and DukeMTMC-reID.