 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Mathematical Problem Solving in LLMs through Execution-Driven Reasoning Augmentation
Feb 03, 2026Mathematical problem solving is a fundamental benchmark for assessing the reasoning capabilities of artificial intelligence and a gateway to applications in education, science, and engineering where reliable symbolic reasoning is essential. Although recent advances in multi-agent LLM-based systems have enhanced their mathematical reasoning capabilities, they still lack a reliably revisable representation of the reasoning process. Existing agents either operate in rigid sequential pipelines that cannot correct earlier steps or rely on heuristic self-evaluation that can fail to identify and fix errors. In addition, programmatic context can distract language models and degrade accuracy. To address these gaps, we introduce Iteratively Improved Program Construction (IIPC), a reasoning method that iteratively refines programmatic reasoning chains and combines execution feedback with the native Chain-of-thought abilities of the base LLM to maintain high-level contextual focus. IIPC surpasses competing approaches in the majority of reasoning benchmarks on multiple base LLMs. All code and implementations are released as open source.
Staircase Streaming for Low-Latency Multi-Agent Inference
Oct 06, 2025



Recent advances in large language models (LLMs) opened up new directions for leveraging the collective expertise of multiple LLMs. These methods, such as Mixture-of-Agents, typically employ additional inference steps to generate intermediate outputs, which are then used to produce the final response. While multi-agent inference can enhance response quality, it can significantly increase the time to first token (TTFT), posing a challenge for latency-sensitive applications and hurting user experience. To address this issue, we propose staircase streaming for low-latency multi-agent inference. Instead of waiting for the complete intermediate outputs from previous steps, we begin generating the final response as soon as we receive partial outputs from these steps. Experimental results demonstrate that staircase streaming reduces TTFT by up to 93% while maintaining response quality.
QoE-oriented Communication Service Provision for Annotation Rendering in Mobile Augmented Reality
Jan 13, 2025


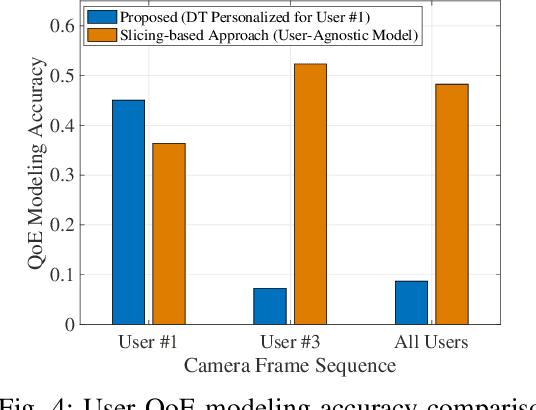
As mobile augmented reality (MAR) continues to evolve, future 6G networks will play a pivotal role in supporting immersive and personalized user experiences. In this paper, we address the communication service provision problem for annotation rendering in edge-assisted MAR, with the objective of optimizing spectrum resource utilization while ensuring the required quality of experience (QoE) for MAR users. To overcome the challenges of user-specific uplink data traffic patterns and the complex operational mechanisms of annotation rendering, we propose a digital twin (DT)-based approach. We first design a DT specifically tailored for MAR applications to learn key annotation rendering mechanisms, enabling the network controller to access MAR application-specific information. Then, we develop a DT based QoE modeling approach to capture the unique relationship between individual user QoE and spectrum resource demands. Finally, we propose a QoE-oriented resource allocation algorithm that decreases resource utilization compared to conventional net work slicing-based approaches. Simulation results demonstrate that our DT-based approach outperforms benchmark approaches in the accuracy and granularity of QoE modeling.
A Multimodal Adaptive Graph-based Intelligent Classification Model for Fake News
Nov 18, 2024
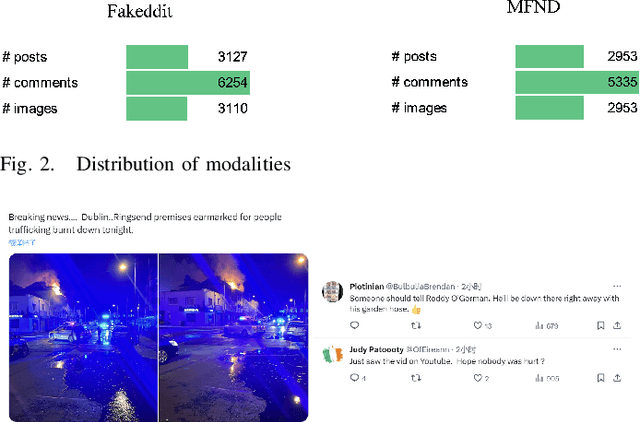


Numerous studies have been proposed to detect fake news focusing on multi-modalities based on machine and/or deep learning. However, studies focusing on graph-based structures using geometric deep learning are lacking. To address this challenge, we introduce the Multimodal Adaptive Graph-based Intelligent Classification (aptly referred to as MAGIC) for fake news detection. Specifically, the Encoder Representations from Transformers was used for text vectorization whilst ResNet50 was used for images. A comprehensive information interaction graph was built using the adaptive Graph Attention Network before classifying the multimodal input through the Softmax function. MAGIC was trained and tested on two fake news datasets, that is, Fakeddit (English) and Multimodal Fake News Detection (Chinese), with the model achieving an accuracy of 98.8\% and 86.3\%, respectively. Ablation experiments also revealed MAGIC to yield superior performance across both the datasets. Findings show that a graph-based deep learning adaptive model is effective in detecting multimodal fake news, surpassing state-of-the-art methods.
Characterizing Behavioral Differences and Adaptations of Automated Vehicles and Human Drivers at Unsignalized Intersections: Insights from Waymo and Lyft Open Datasets
Oct 16, 2024The integration of autonomous vehicles (AVs) into transportation systems presents an unprecedented opportunity to enhance road safety and efficiency. However, understanding the interactions between AVs and human-driven vehicles (HVs) at intersections remains an open research question. This study aims to bridge this gap by examining behavioral differences and adaptations of AVs and HVs at unsignalized intersections by utilizing two comprehensive AV datasets from Waymo and Lyft. Using a systematic methodology, the research identifies and analyzes merging and crossing conflicts by calculating key safety and efficiency metrics, including time to collision (TTC), post-encroachment time (PET), maximum required deceleration (MRD), time advantage (TA), and speed and acceleration profiles. The findings reveal a paradox in mixed traffic flow: while AVs maintain larger safety margins, their conservative behavior can lead to unexpected situations for human drivers, potentially causing unsafe conditions. From a performance point of view, human drivers exhibit more consistent behavior when interacting with AVs versus other HVs, suggesting AVs may contribute to harmonizing traffic flow patterns. Moreover, notable differences were observed between Waymo and Lyft vehicles, which highlights the importance of considering manufacturer-specific AV behaviors in traffic modeling and management strategies for the safe integration of AVs. The processed dataset utilized in this study is openly published to foster the research on AV-HV interactions.
Automated Discovery of Pairwise Interactions from Unstructured Data
Sep 11, 2024



Pairwise interactions between perturbations to a system can provide evidence for the causal dependencies of the underlying underlying mechanisms of a system. When observations are low dimensional, hand crafted measurements, detecting interactions amounts to simple statistical tests, but it is not obvious how to detect interactions between perturbations affecting latent variables. We derive two interaction tests that are based on pairwise interventions, and show how these tests can be integrated into an active learning pipeline to efficiently discover pairwise interactions between perturbations. We illustrate the value of these tests in the context of biology, where pairwise perturbation experiments are frequently used to reveal interactions that are not observable from any single perturbation. Our tests can be run on unstructured data, such as the pixels in an image, which enables a more general notion of interaction than typical cell viability experiments, and can be run on cheaper experimental assays. We validate on several synthetic and real biological experiments that our tests are able to identify interacting pairs effectively. We evaluate our approach on a real biological experiment where we knocked out 50 pairs of genes and measured the effect with microscopy images. We show that we are able to recover significantly more known biological interactions than random search and standard active learning baselines.
FreeRide: Harvesting Bubbles in Pipeline Parallelism
Sep 11, 2024



The occurrence of bubbles in pipeline parallelism is an inherent limitation that can account for more than 40% of the large language model (LLM) training time and is one of the main reasons for the underutilization of GPU resources in LLM training. Harvesting these bubbles for GPU side tasks can increase resource utilization and reduce training costs but comes with challenges. First, because bubbles are discontinuous with various shapes, programming side tasks becomes difficult while requiring excessive engineering effort. Second, a side task can compete with pipeline training for GPU resources and incur significant overhead. To address these challenges, we propose FreeRide, a system designed to harvest bubbles in pipeline parallelism for side tasks. FreeRide provides programmers with interfaces to implement side tasks easily, manages bubbles and side tasks during pipeline training, and controls access to GPU resources by side tasks to reduce overhead. We demonstrate that FreeRide achieves 7.8% average cost savings with a negligible overhead of about 1% in training LLMs while serving model training, graph analytics, and image processing side tasks.
Can Deep Learning Assist Automatic Identification of Layered Pigments From XRF Data?
Jul 26, 2022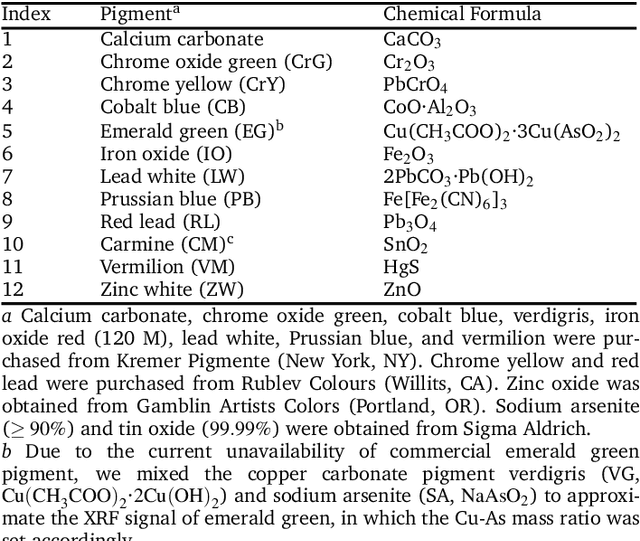
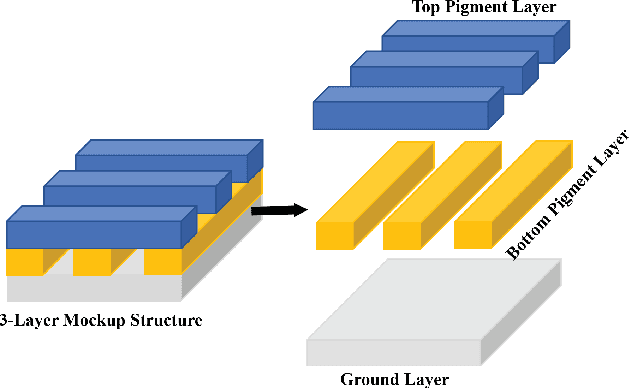
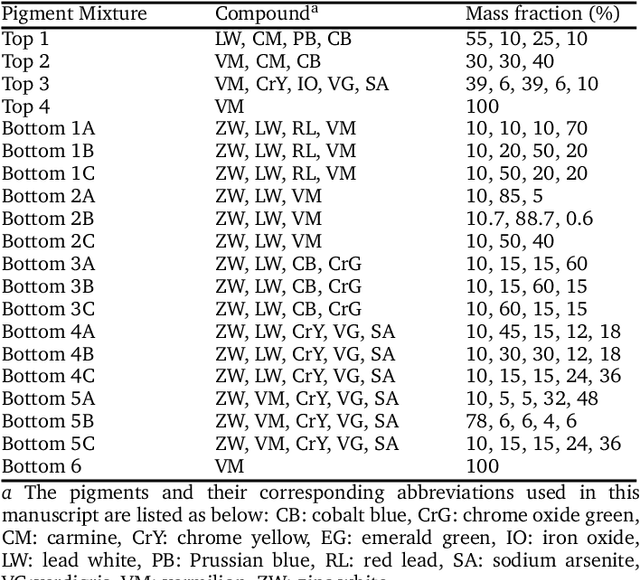
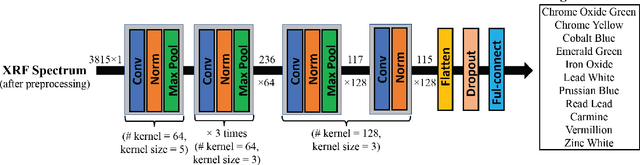
X-ray fluorescence spectroscopy (XRF) plays an important role for elemental analysis in a wide range of scientific fields, especially in cultural heritage. XRF imaging, which uses a raster scan to acquire spectra across artworks, provides the opportunity for spatial analysis of pigment distributions based on their elemental composition. However, conventional XRF-based pigment identification relies on time-consuming elemental mapping by expert interpretations of measured spectra. To reduce the reliance on manual work, recent studies have applied machine learning techniques to cluster similar XRF spectra in data analysis and to identify the most likely pigments. Nevertheless, it is still challenging for automatic pigment identification strategies to directly tackle the complex structure of real paintings, e.g. pigment mixtures and layered pigments. In addition, pixel-wise pigment identification based on XRF imaging remains an obstacle due to the high noise level compared with averaged spectra. Therefore, we developed a deep-learning-based end-to-end pigment identification framework to fully automate the pigment identification process. In particular, it offers high sensitivity to the underlying pigments and to the pigments with a low concentration, therefore enabling satisfying results in mapping the pigments based on single-pixel XRF spectrum. As case studies, we applied our framework to lab-prepared mock-up paintings and two 19th-century paintings: Paul Gauguin's Po\`emes Barbares (1896) that contains layered pigments with an underlying painting, and Paul Cezanne's The Bathers (1899-1904). The pigment identification results demonstrated that our model achieved comparable results to the analysis by elemental mapping, suggesting the generalizability and stability of our model.
Reinforcement Learning from Imperfect Demonstrations
Feb 14, 2018

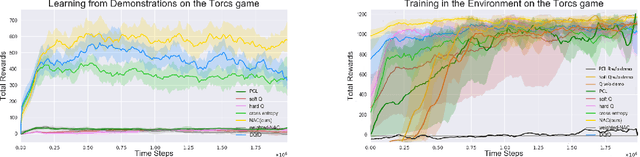
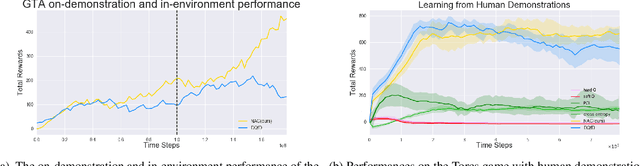
Robust real-world learning should benefit from both demonstrations and interactions with the environment. Current approaches to learning from demonstration and reward perform supervised learning on expert demonstration data and use reinforcement learning to further improve performance based on the reward received from the environment. These tasks have divergent losses which are difficult to jointly optimize and such methods can be very sensitive to noisy demonstrations. We propose a unified reinforcement learning algorithm, Normalized Actor-Critic (NAC), that effectively normalizes the Q-function, reducing the Q-values of actions unseen in the demonstration data. NAC learns an initial policy network from demonstrations and refines the policy in the environment, surpassing the demonstrator's performance. Crucially, both learning from demonstration and interactive refinement use the same objective, unlike prior approaches that combine distinct supervised and reinforcement losses. This makes NAC robust to suboptimal demonstration data since the method is not forced to mimic all of the examples in the dataset. We show that our unified reinforcement learning algorithm can learn robustly and outperform existing baselines when evaluated on several realistic driving games.
An alternative text representation to TF-IDF and Bag-of-Words
Jan 28, 2013


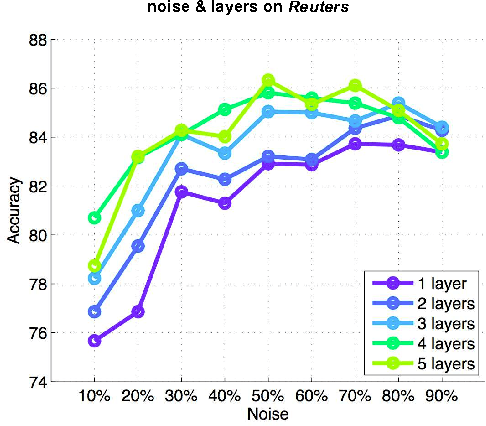
In text mining, information retrieval, and machine learning, text documents are commonly represented through variants of sparse Bag of Words (sBoW) vectors (e.g. TF-IDF). Although simple and intuitive, sBoW style representations suffer from their inherent over-sparsity and fail to capture word-level synonymy and polysemy. Especially when labeled data is limited (e.g. in document classification), or the text documents are short (e.g. emails or abstracts), many features are rarely observed within the training corpus. This leads to overfitting and reduced generalization accuracy. In this paper we propose Dense Cohort of Terms (dCoT), an unsupervised algorithm to learn improved sBoW document features. dCoT explicitly models absent words by removing and reconstructing random sub-sets of words in the unlabeled corpus. With this approach, dCoT learns to reconstruct frequent words from co-occurring infrequent words and maps the high dimensional sparse sBoW vectors into a low-dimensional dense representation. We show that the feature removal can be marginalized out and that the reconstruction can be solved for in closed-form. We demonstrate empirically, on several benchmark datasets, that dCoT features significantly improve the classification accuracy across several document classification tasks.