 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn alternative text representation to TF-IDF and Bag-of-Words
Paper and Code
Jan 28, 2013


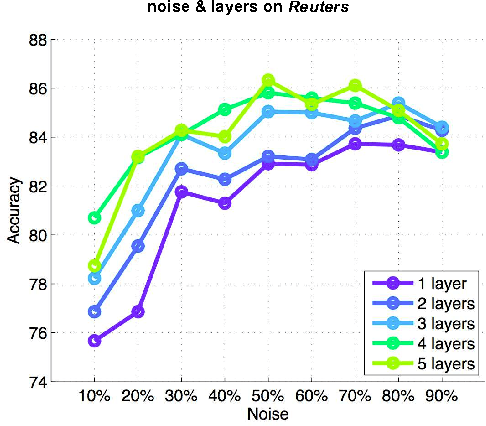
In text mining, information retrieval, and machine learning, text documents are commonly represented through variants of sparse Bag of Words (sBoW) vectors (e.g. TF-IDF). Although simple and intuitive, sBoW style representations suffer from their inherent over-sparsity and fail to capture word-level synonymy and polysemy. Especially when labeled data is limited (e.g. in document classification), or the text documents are short (e.g. emails or abstracts), many features are rarely observed within the training corpus. This leads to overfitting and reduced generalization accuracy. In this paper we propose Dense Cohort of Terms (dCoT), an unsupervised algorithm to learn improved sBoW document features. dCoT explicitly models absent words by removing and reconstructing random sub-sets of words in the unlabeled corpus. With this approach, dCoT learns to reconstruct frequent words from co-occurring infrequent words and maps the high dimensional sparse sBoW vectors into a low-dimensional dense representation. We show that the feature removal can be marginalized out and that the reconstruction can be solved for in closed-form. We demonstrate empirically, on several benchmark datasets, that dCoT features significantly improve the classification accuracy across several document classification tasks.