 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSm: enhanced localization in Multiple Instance Learning for medical imaging classification
Oct 04, 2024Multiple Instance Learning (MIL) is widely used in medical imaging classification to reduce the labeling effort. While only bag labels are available for training, one typically seeks predictions at both bag and instance levels (classification and localization tasks, respectively). Early MIL methods treated the instances in a bag independently. Recent methods account for global and local dependencies among instances. Although they have yielded excellent results in classification, their performance in terms of localization is comparatively limited. We argue that these models have been designed to target the classification task, while implications at the instance level have not been deeply investigated. Motivated by a simple observation -- that neighboring instances are likely to have the same label -- we propose a novel, principled, and flexible mechanism to model local dependencies. It can be used alone or combined with any mechanism to model global dependencies (e.g., transformers). A thorough empirical validation shows that our module leads to state-of-the-art performance in localization while being competitive or superior in classification. Our code is at https://github.com/Franblueee/SmMIL.
Cross-Temporal Spectrogram Autoencoder (CTSAE): Unsupervised Dimensionality Reduction for Clustering Gravitational Wave Glitches
Apr 23, 2024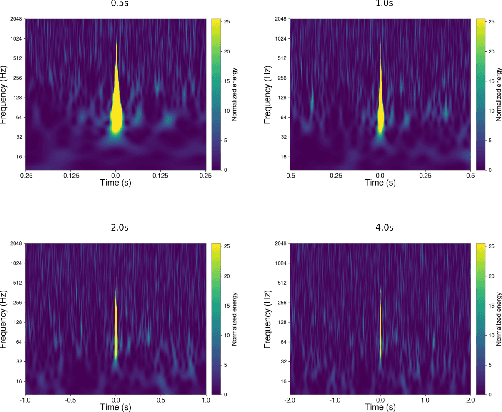
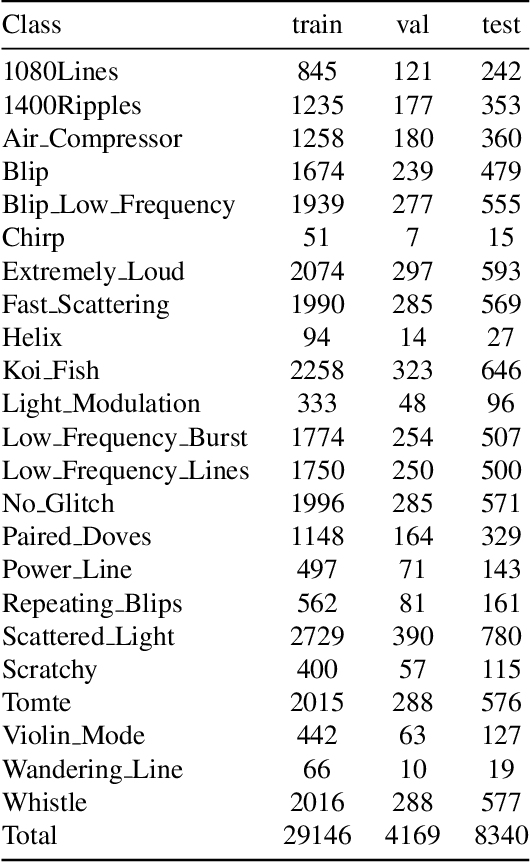
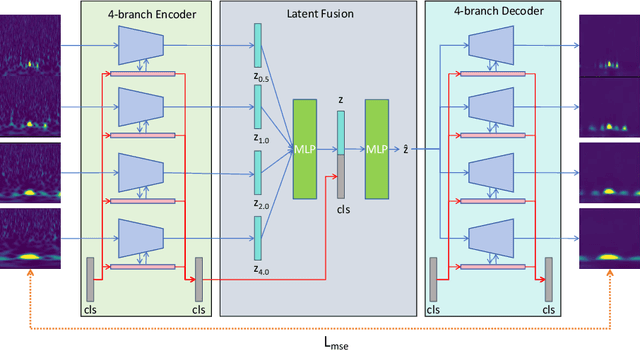
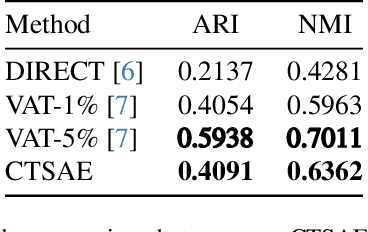
The advancement of The Laser Interferometer Gravitational-Wave Observatory (LIGO) has significantly enhanced the feasibility and reliability of gravitational wave detection. However, LIGO's high sensitivity makes it susceptible to transient noises known as glitches, which necessitate effective differentiation from real gravitational wave signals. Traditional approaches predominantly employ fully supervised or semi-supervised algorithms for the task of glitch classification and clustering. In the future task of identifying and classifying glitches across main and auxiliary channels, it is impractical to build a dataset with manually labeled ground-truth. In addition, the patterns of glitches can vary with time, generating new glitches without manual labels. In response to this challenge, we introduce the Cross-Temporal Spectrogram Autoencoder (CTSAE), a pioneering unsupervised method for the dimensionality reduction and clustering of gravitational wave glitches. CTSAE integrates a novel four-branch autoencoder with a hybrid of Convolutional Neural Networks (CNN) and Vision Transformers (ViT). To further extract features across multi-branches, we introduce a novel multi-branch fusion method using the CLS (Class) token. Our model, trained and evaluated on the GravitySpy O3 dataset on the main channel, demonstrates superior performance in clustering tasks when compared to state-of-the-art semi-supervised learning methods. To the best of our knowledge, CTSAE represents the first unsupervised approach tailored specifically for clustering LIGO data, marking a significant step forward in the field of gravitational wave research. The code of this paper is available at https://github.com/Zod-L/CTSAE
Advancing Glitch Classification in Gravity Spy: Multi-view Fusion with Attention-based Machine Learning for Advanced LIGO's Fourth Observing Run
Jan 23, 2024The first successful detection of gravitational waves by ground-based observatories, such as the Laser Interferometer Gravitational-Wave Observatory (LIGO), marked a revolutionary breakthrough in our comprehension of the Universe. However, due to the unprecedented sensitivity required to make such observations, gravitational-wave detectors also capture disruptive noise sources called glitches, potentially masking or appearing as gravitational-wave signals themselves. To address this problem, a community-science project, Gravity Spy, incorporates human insight and machine learning to classify glitches in LIGO data. The machine learning classifier, integrated into the project since 2017, has evolved over time to accommodate increasing numbers of glitch classes. Despite its success, limitations have arisen in the ongoing LIGO fourth observing run (O4) due to its architecture's simplicity, which led to poor generalization and inability to handle multi-time window inputs effectively. We propose an advanced classifier for O4 glitches. Our contributions include evaluating fusion strategies for multi-time window inputs, using label smoothing to counter noisy labels, and enhancing interpretability through attention module-generated weights. This development seeks to enhance glitch classification, aiding in the ongoing exploration of gravitational-wave phenomena.
Smooth Attention for Deep Multiple Instance Learning: Application to CT Intracranial Hemorrhage Detection
Jul 18, 2023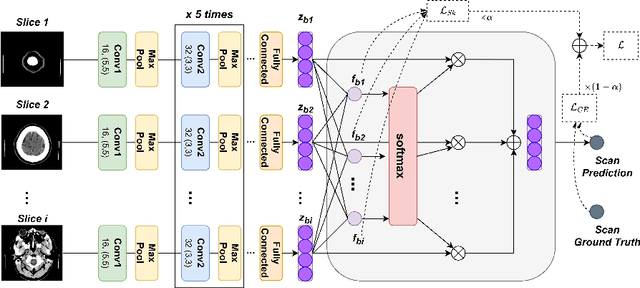

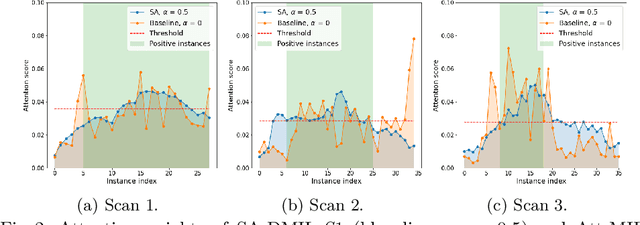
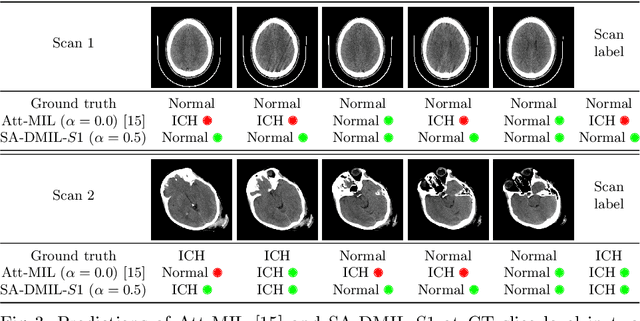
Multiple Instance Learning (MIL) has been widely applied to medical imaging diagnosis, where bag labels are known and instance labels inside bags are unknown. Traditional MIL assumes that instances in each bag are independent samples from a given distribution. However, instances are often spatially or sequentially ordered, and one would expect similar diagnostic importance for neighboring instances. To address this, in this study, we propose a smooth attention deep MIL (SA-DMIL) model. Smoothness is achieved by the introduction of first and second order constraints on the latent function encoding the attention paid to each instance in a bag. The method is applied to the detection of intracranial hemorrhage (ICH) on head CT scans. The results show that this novel SA-DMIL: (a) achieves better performance than the non-smooth attention MIL at both scan (bag) and slice (instance) levels; (b) learns spatial dependencies between slices; and (c) outperforms current state-of-the-art MIL methods on the same ICH test set.
The ART of Transfer Learning: An Adaptive and Robust Pipeline
Apr 30, 2023Transfer learning is an essential tool for improving the performance of primary tasks by leveraging information from auxiliary data resources. In this work, we propose Adaptive Robust Transfer Learning (ART), a flexible pipeline of performing transfer learning with generic machine learning algorithms. We establish the non-asymptotic learning theory of ART, providing a provable theoretical guarantee for achieving adaptive transfer while preventing negative transfer. Additionally, we introduce an ART-integrated-aggregating machine that produces a single final model when multiple candidate algorithms are considered. We demonstrate the promising performance of ART through extensive empirical studies on regression, classification, and sparse learning. We further present a real-data analysis for a mortality study.
DeepCOVID-Fuse: A Multi-modality Deep Learning Model Fusing Chest X-Radiographs and Clinical Variables to Predict COVID-19 Risk Levels
Jan 20, 2023Propose: To present DeepCOVID-Fuse, a deep learning fusion model to predict risk levels in patients with confirmed coronavirus disease 2019 (COVID-19) and to evaluate the performance of pre-trained fusion models on full or partial combination of chest x-ray (CXRs) or chest radiograph and clinical variables. Materials and Methods: The initial CXRs, clinical variables and outcomes (i.e., mortality, intubation, hospital length of stay, ICU admission) were collected from February 2020 to April 2020 with reverse-transcription polymerase chain reaction (RT-PCR) test results as the reference standard. The risk level was determined by the outcome. The fusion model was trained on 1657 patients (Age: 58.30 +/- 17.74; Female: 807) and validated on 428 patients (56.41 +/- 17.03; 190) from Northwestern Memorial HealthCare system and was tested on 439 patients (56.51 +/- 17.78; 205) from a single holdout hospital. Performance of pre-trained fusion models on full or partial modalities were compared on the test set using the DeLong test for the area under the receiver operating characteristic curve (AUC) and the McNemar test for accuracy, precision, recall and F1. Results: The accuracy of DeepCOVID-Fuse trained on CXRs and clinical variables is 0.658, with an AUC of 0.842, which significantly outperformed (p < 0.05) models trained only on CXRs with an accuracy of 0.621 and AUC of 0.807 and only on clinical variables with an accuracy of 0.440 and AUC of 0.502. The pre-trained fusion model with only CXRs as input increases accuracy to 0.632 and AUC to 0.813 and with only clinical variables as input increases accuracy to 0.539 and AUC to 0.733. Conclusion: The fusion model learns better feature representations across different modalities during training and achieves good outcome predictions even when only some of the modalities are used in testing.
Can Deep Learning Assist Automatic Identification of Layered Pigments From XRF Data?
Jul 26, 2022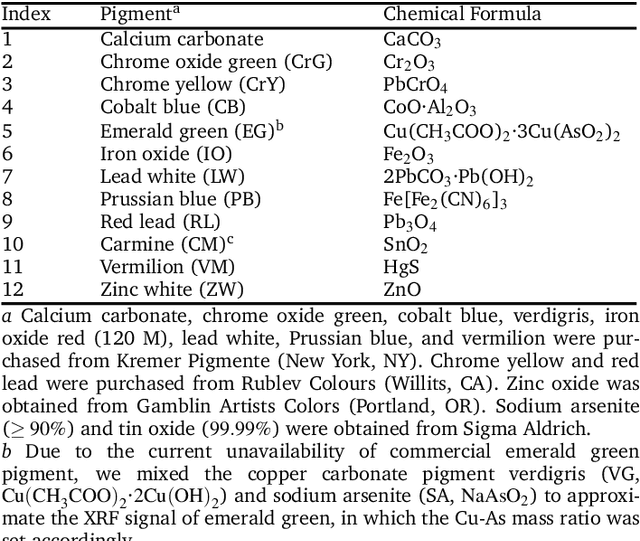
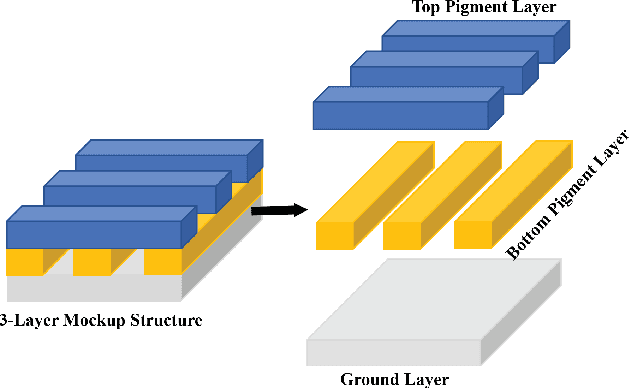
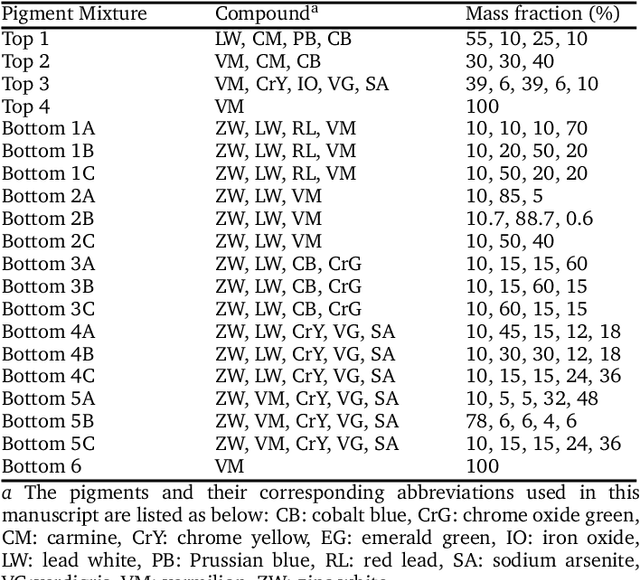
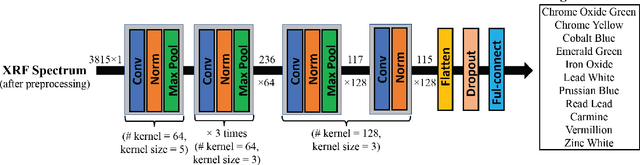
X-ray fluorescence spectroscopy (XRF) plays an important role for elemental analysis in a wide range of scientific fields, especially in cultural heritage. XRF imaging, which uses a raster scan to acquire spectra across artworks, provides the opportunity for spatial analysis of pigment distributions based on their elemental composition. However, conventional XRF-based pigment identification relies on time-consuming elemental mapping by expert interpretations of measured spectra. To reduce the reliance on manual work, recent studies have applied machine learning techniques to cluster similar XRF spectra in data analysis and to identify the most likely pigments. Nevertheless, it is still challenging for automatic pigment identification strategies to directly tackle the complex structure of real paintings, e.g. pigment mixtures and layered pigments. In addition, pixel-wise pigment identification based on XRF imaging remains an obstacle due to the high noise level compared with averaged spectra. Therefore, we developed a deep-learning-based end-to-end pigment identification framework to fully automate the pigment identification process. In particular, it offers high sensitivity to the underlying pigments and to the pigments with a low concentration, therefore enabling satisfying results in mapping the pigments based on single-pixel XRF spectrum. As case studies, we applied our framework to lab-prepared mock-up paintings and two 19th-century paintings: Paul Gauguin's Po\`emes Barbares (1896) that contains layered pigments with an underlying painting, and Paul Cezanne's The Bathers (1899-1904). The pigment identification results demonstrated that our model achieved comparable results to the analysis by elemental mapping, suggesting the generalizability and stability of our model.
Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes
Jan 22, 2022
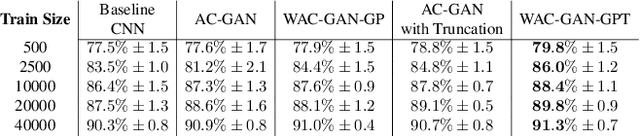
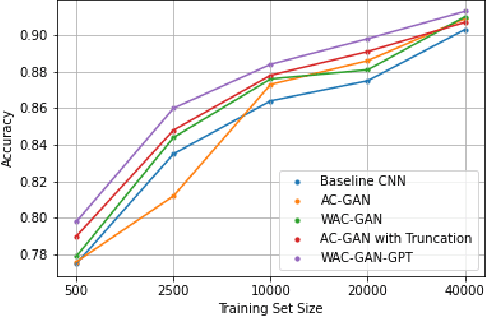

Generative Adversarial Networks (GANs) have shown promise in augmenting datasets and boosting convolutional neural networks' (CNN) performance on image classification tasks. But they introduce more hyperparameters to tune as well as the need for additional time and computational power to train supplementary to the CNN. In this work, we examine the potential for Auxiliary-Classifier GANs (AC-GANs) as a 'one-stop-shop' architecture for image classification, particularly in low data regimes. Additionally, we explore modifications to the typical AC-GAN framework, changing the generator's latent space sampling scheme and employing a Wasserstein loss with gradient penalty to stabilize the simultaneous training of image synthesis and classification. Through experiments on images of varying resolutions and complexity, we demonstrate that AC-GANs show promise in image classification, achieving competitive performance with standard CNNs. These methods can be employed as an 'all-in-one' framework with particular utility in the absence of large amounts of training data.
Interpretation of Brain Morphology in Association to Alzheimer's Disease Dementia Classification Using Graph Convolutional Networks on Triangulated Meshes
Aug 20, 2020
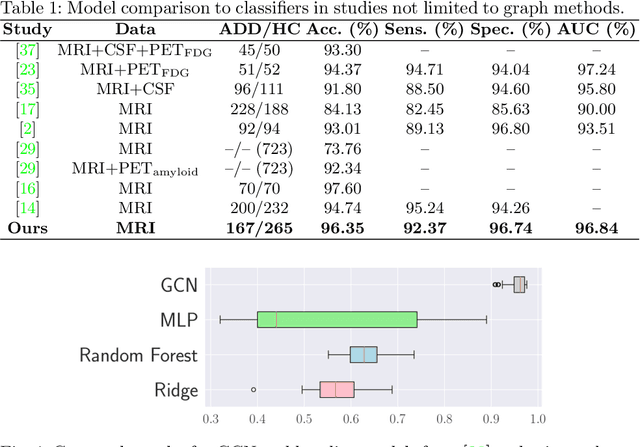
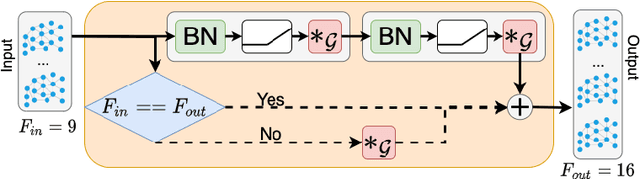

We propose a mesh-based technique to aid in the classification of Alzheimer's disease dementia (ADD) using mesh representations of the cortex and subcortical structures. Deep learning methods for classification tasks that utilize structural neuroimaging often require extensive learning parameters to optimize. Frequently, these approaches for automated medical diagnosis also lack visual interpretability for areas in the brain involved in making a diagnosis. This work: (a) analyzes brain shape using surface information of the cortex and subcortical structures, (b) proposes a residual learning framework for state-of-the-art graph convolutional networks which offer a significant reduction in learnable parameters, and (c) offers visual interpretability of the network via class-specific gradient information that localizes important regions of interest in our inputs. With our proposed method leveraging the use of cortical and subcortical surface information, we outperform other machine learning methods with a 96.35% testing accuracy for the ADD vs. healthy control problem. We confirm the validity of our model by observing its performance in a 25-trial Monte Carlo cross-validation. The generated visualization maps in our study show correspondences with current knowledge regarding the structural localization of pathological changes in the brain associated to dementia of the Alzheimer's type.
Resampling-based Confidence Intervals for Model-free Robust Inference on Optimal Treatment Regimes
Nov 25, 2019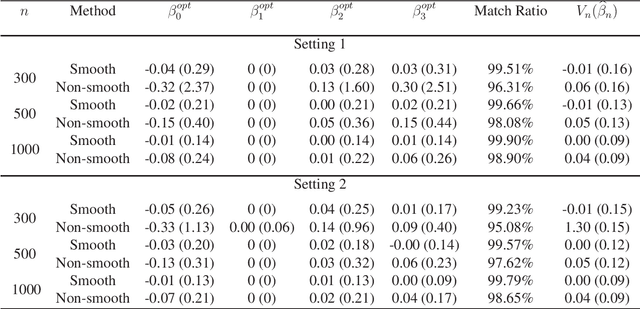
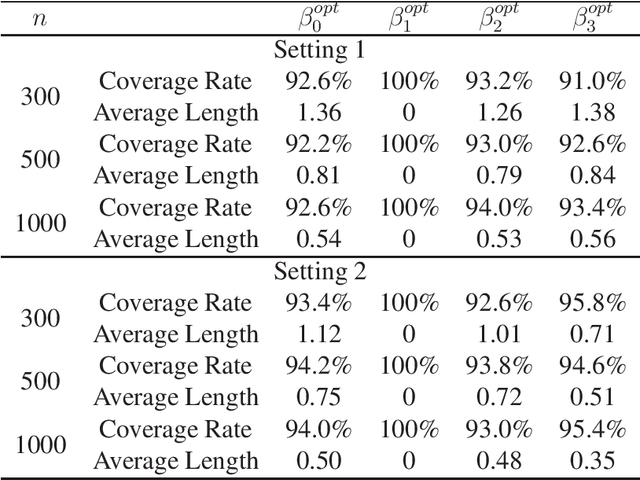

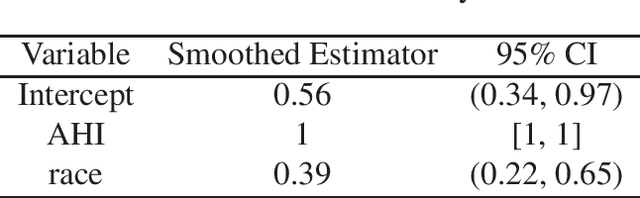
Recently, there has been growing interest in estimating optimal treatment regimes which are individualized decision rules that can achieve maximal average outcomes. This paper considers the problem of inference for optimal treatment regimes in the model-free setting, where the specification of an outcome regression model is not needed. Existing model-free estimators are usually not suitable for the purpose of inference because they either have nonstandard asymptotic distributions, or are designed to achieve fisher-consistent classification performance. This paper first studies a smoothed robust estimator that directly targets estimating the parameters corresponding to the Bayes decision rule for estimating the optimal treatment regime. This estimator is shown to have an asymptotic normal distribution. Furthermore, it is proved that a resampling procedure provides asymptotically accurate inference for both the parameters indexing the optimal treatment regime and the optimal value function. A new algorithm is developed to calculate the proposed estimator with substantially improved speed and stability. Numerical results demonstrate the satisfactory performance of the new methods.