 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Glitch Classification in Gravity Spy: Multi-view Fusion with Attention-based Machine Learning for Advanced LIGO's Fourth Observing Run
Jan 23, 2024The first successful detection of gravitational waves by ground-based observatories, such as the Laser Interferometer Gravitational-Wave Observatory (LIGO), marked a revolutionary breakthrough in our comprehension of the Universe. However, due to the unprecedented sensitivity required to make such observations, gravitational-wave detectors also capture disruptive noise sources called glitches, potentially masking or appearing as gravitational-wave signals themselves. To address this problem, a community-science project, Gravity Spy, incorporates human insight and machine learning to classify glitches in LIGO data. The machine learning classifier, integrated into the project since 2017, has evolved over time to accommodate increasing numbers of glitch classes. Despite its success, limitations have arisen in the ongoing LIGO fourth observing run (O4) due to its architecture's simplicity, which led to poor generalization and inability to handle multi-time window inputs effectively. We propose an advanced classifier for O4 glitches. Our contributions include evaluating fusion strategies for multi-time window inputs, using label smoothing to counter noisy labels, and enhancing interpretability through attention module-generated weights. This development seeks to enhance glitch classification, aiding in the ongoing exploration of gravitational-wave phenomena.
Active Learning for Computationally Efficient Distribution of Binary Evolution Simulations
Mar 30, 2022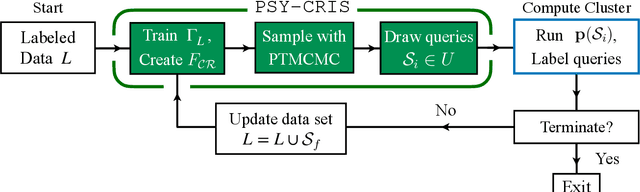

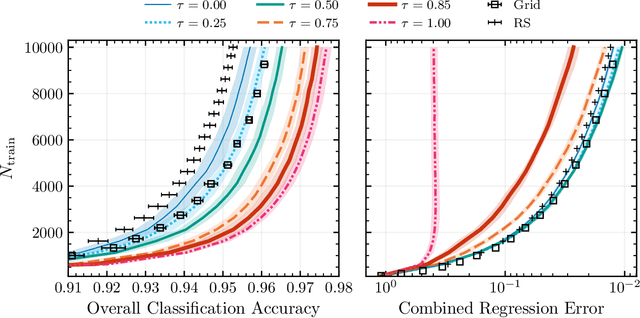
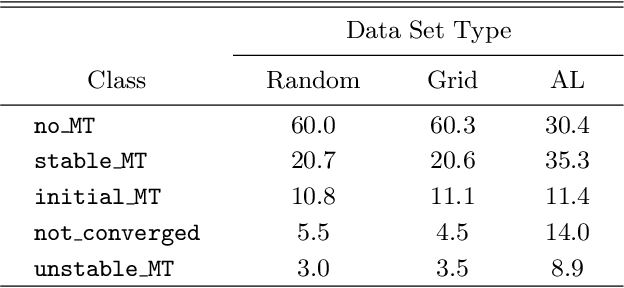
Binary stars undergo a variety of interactions and evolutionary phases, critical for predicting and explaining observed properties. Binary population synthesis with full stellar-structure and evolution simulations are computationally expensive requiring a large number of mass-transfer sequences. The recently developed binary population synthesis code POSYDON incorporates grids of MESA binary star simulations which are then interpolated to model large-scale populations of massive binaries. The traditional method of computing a high-density rectilinear grid of simulations is not scalable for higher-dimension grids, accounting for a range of metallicities, rotation, and eccentricity. We present a new active learning algorithm, psy-cris, which uses machine learning in the data-gathering process to adaptively and iteratively select targeted simulations to run, resulting in a custom, high-performance training set. We test psy-cris on a toy problem and find the resulting training sets require fewer simulations for accurate classification and regression than either regular or randomly sampled grids. We further apply psy-cris to the target problem of building a dynamic grid of MESA simulations, and we demonstrate that, even without fine tuning, a simulation set of only $\sim 1/4$ the size of a rectilinear grid is sufficient to achieve the same classification accuracy. We anticipate further gains when algorithmic parameters are optimized for the targeted application. We find that optimizing for classification only may lead to performance losses in regression, and vice versa. Lowering the computational cost of producing grids will enable future versions of POSYDON to cover more input parameters while preserving interpolation accuracies.
Fast methods for training Gaussian processes on large data sets
May 13, 2016

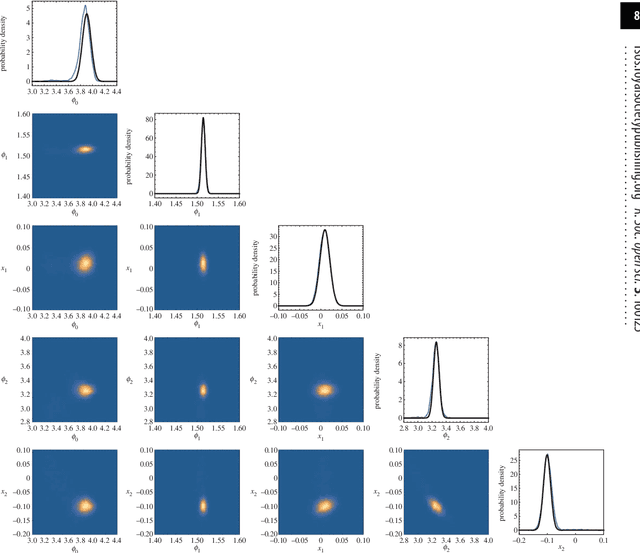
Gaussian process regression (GPR) is a non-parametric Bayesian technique for interpolating or fitting data. The main barrier to further uptake of this powerful tool rests in the computational costs associated with the matrices which arise when dealing with large data sets. Here, we derive some simple results which we have found useful for speeding up the learning stage in the GPR algorithm, and especially for performing Bayesian model comparison between different covariance functions. We apply our techniques to both synthetic and real data and quantify the speed-up relative to using nested sampling to numerically evaluate model evidences.
* Fixed missing references