 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Computationally Efficient Distribution of Binary Evolution Simulations
Paper and Code
Mar 30, 2022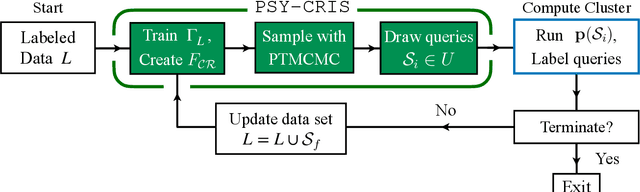

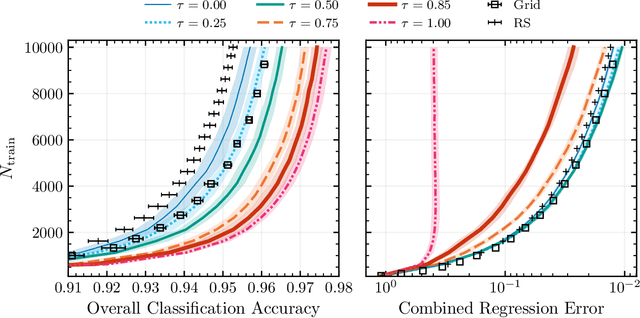
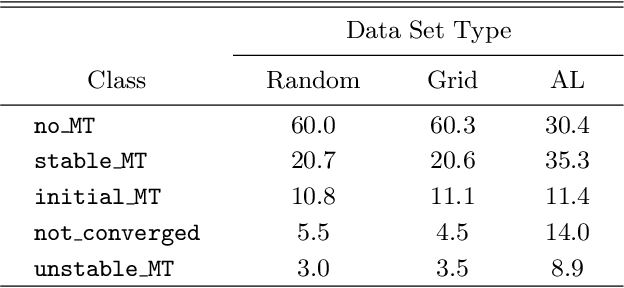
Binary stars undergo a variety of interactions and evolutionary phases, critical for predicting and explaining observed properties. Binary population synthesis with full stellar-structure and evolution simulations are computationally expensive requiring a large number of mass-transfer sequences. The recently developed binary population synthesis code POSYDON incorporates grids of MESA binary star simulations which are then interpolated to model large-scale populations of massive binaries. The traditional method of computing a high-density rectilinear grid of simulations is not scalable for higher-dimension grids, accounting for a range of metallicities, rotation, and eccentricity. We present a new active learning algorithm, psy-cris, which uses machine learning in the data-gathering process to adaptively and iteratively select targeted simulations to run, resulting in a custom, high-performance training set. We test psy-cris on a toy problem and find the resulting training sets require fewer simulations for accurate classification and regression than either regular or randomly sampled grids. We further apply psy-cris to the target problem of building a dynamic grid of MESA simulations, and we demonstrate that, even without fine tuning, a simulation set of only $\sim 1/4$ the size of a rectilinear grid is sufficient to achieve the same classification accuracy. We anticipate further gains when algorithmic parameters are optimized for the targeted application. We find that optimizing for classification only may lead to performance losses in regression, and vice versa. Lowering the computational cost of producing grids will enable future versions of POSYDON to cover more input parameters while preserving interpolation accuracies.