 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Computationally Efficient Distribution of Binary Evolution Simulations
Mar 30, 2022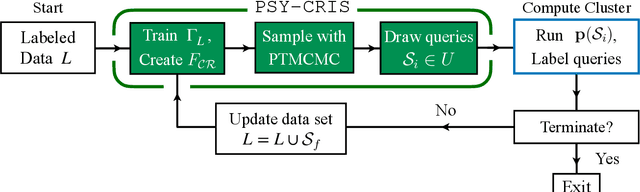

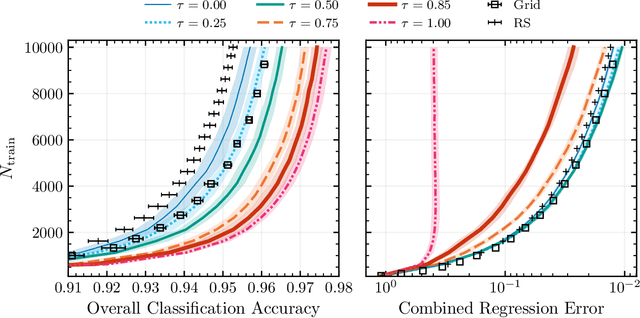
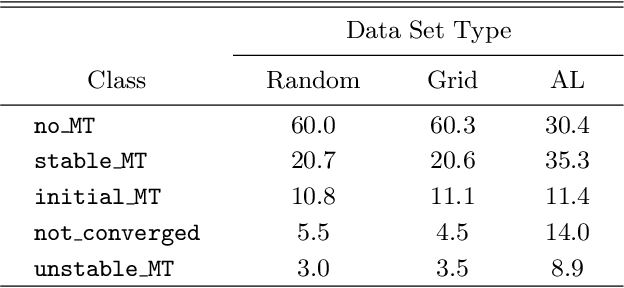
Binary stars undergo a variety of interactions and evolutionary phases, critical for predicting and explaining observed properties. Binary population synthesis with full stellar-structure and evolution simulations are computationally expensive requiring a large number of mass-transfer sequences. The recently developed binary population synthesis code POSYDON incorporates grids of MESA binary star simulations which are then interpolated to model large-scale populations of massive binaries. The traditional method of computing a high-density rectilinear grid of simulations is not scalable for higher-dimension grids, accounting for a range of metallicities, rotation, and eccentricity. We present a new active learning algorithm, psy-cris, which uses machine learning in the data-gathering process to adaptively and iteratively select targeted simulations to run, resulting in a custom, high-performance training set. We test psy-cris on a toy problem and find the resulting training sets require fewer simulations for accurate classification and regression than either regular or randomly sampled grids. We further apply psy-cris to the target problem of building a dynamic grid of MESA simulations, and we demonstrate that, even without fine tuning, a simulation set of only $\sim 1/4$ the size of a rectilinear grid is sufficient to achieve the same classification accuracy. We anticipate further gains when algorithmic parameters are optimized for the targeted application. We find that optimizing for classification only may lead to performance losses in regression, and vice versa. Lowering the computational cost of producing grids will enable future versions of POSYDON to cover more input parameters while preserving interpolation accuracies.
Scalable Variational Gaussian Processes for Crowdsourcing: Glitch Detection in LIGO
Nov 05, 2019

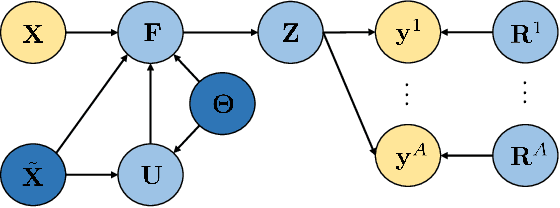

In the last years, crowdsourcing is transforming the way classification training sets are obtained. Instead of relying on a single expert annotator, crowdsourcing shares the labelling effort among a large number of collaborators. For instance, this is being applied to the data acquired by the laureate Laser Interferometer Gravitational Waves Observatory (LIGO), in order to detect glitches which might hinder the identification of true gravitational-waves. The crowdsourcing scenario poses new challenging difficulties, as it deals with different opinions from a heterogeneous group of annotators with unknown degrees of expertise. Probabilistic methods, such as Gaussian Processes (GP), have proven successful in modeling this setting. However, GPs do not scale well to large data sets, which hampers their broad adoption in real practice (in particular at LIGO). This has led to the recent introduction of deep learning based crowdsourcing methods, which have become the state-of-the-art. However, the accurate uncertainty quantification of GPs has been partially sacrificed. This is an important aspect for astrophysicists in LIGO, since a glitch detection system should provide very accurate probability distributions of its predictions. In this work, we leverage the most popular sparse GP approximation to develop a novel GP based crowdsourcing method that factorizes into mini-batches. This makes it able to cope with previously-prohibitive data sets. The approach, which we refer to as Scalable Variational Gaussian Processes for Crowdsourcing (SVGPCR), brings back GP-based methods to the state-of-the-art, and excels at uncertainty quantification. SVGPCR is shown to outperform deep learning based methods and previous probabilistic approaches when applied to the LIGO data. Moreover, its behavior and main properties are carefully analyzed in a controlled experiment based on the MNIST data set.
DIRECT: Deep Discriminative Embedding for Clustering of LIGO Data
May 07, 2018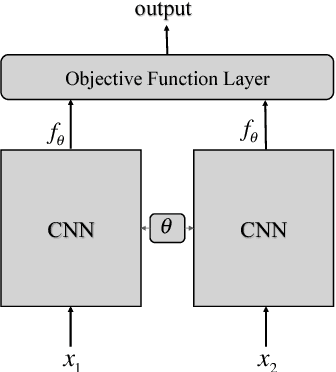
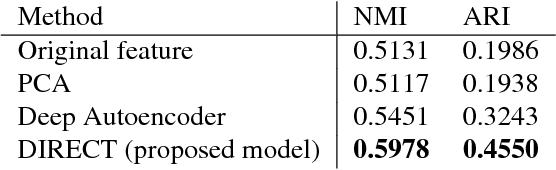
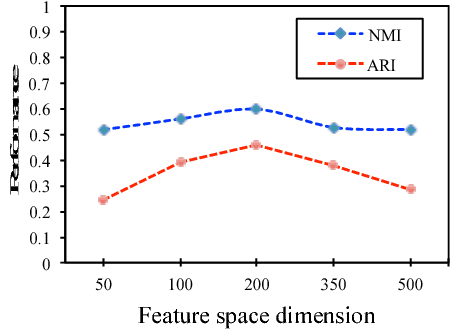
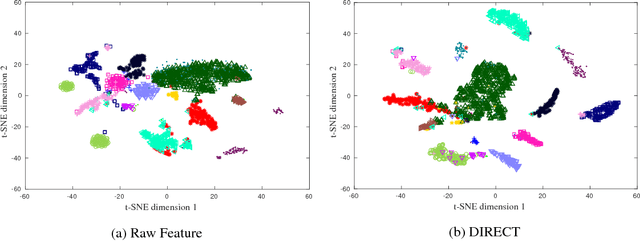
In this paper, benefiting from the strong ability of deep neural network in estimating non-linear functions, we propose a discriminative embedding function to be used as a feature extractor for clustering tasks. The trained embedding function transfers knowledge from the domain of a labeled set of morphologically-distinct images, known as classes, to a new domain within which new classes can potentially be isolated and identified. Our target application in this paper is the Gravity Spy Project, which is an effort to characterize transient, non-Gaussian noise present in data from the Advanced Laser Interferometer Gravitational-wave Observatory, or LIGO. Accumulating large, labeled sets of noise features and identifying of new classes of noise lead to a better understanding of their origin, which makes their removal from the data and/or detectors possible.
Deep Multi-view Models for Glitch Classification
Apr 28, 2017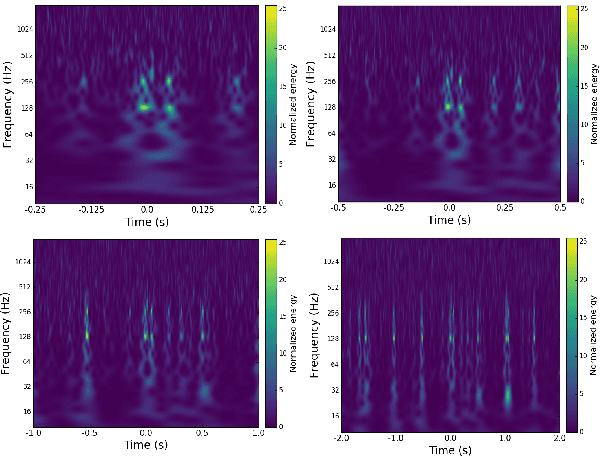

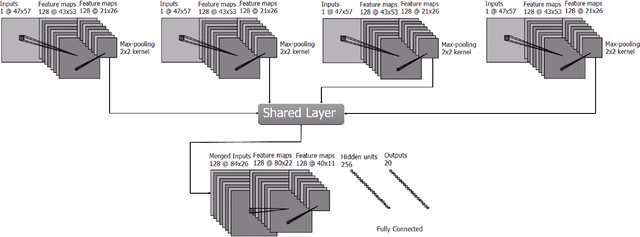
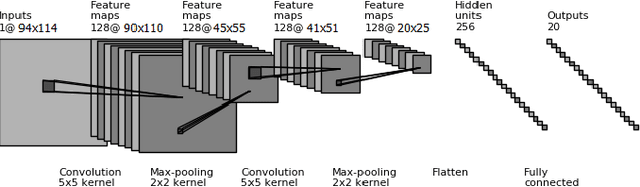
Non-cosmic, non-Gaussian disturbances known as "glitches", show up in gravitational-wave data of the Advanced Laser Interferometer Gravitational-wave Observatory, or aLIGO. In this paper, we propose a deep multi-view convolutional neural network to classify glitches automatically. The primary purpose of classifying glitches is to understand their characteristics and origin, which facilitates their removal from the data or from the detector entirely. We visualize glitches as spectrograms and leverage the state-of-the-art image classification techniques in our model. The suggested classifier is a multi-view deep neural network that exploits four different views for classification. The experimental results demonstrate that the proposed model improves the overall accuracy of the classification compared to traditional single view algorithms.