 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Variational Gaussian Processes for Crowdsourcing: Glitch Detection in LIGO
Paper and Code


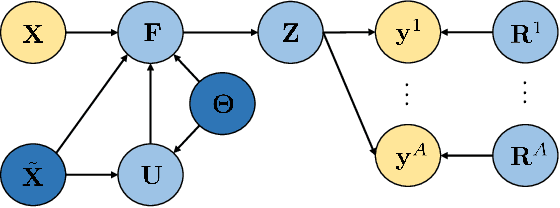

In the last years, crowdsourcing is transforming the way classification training sets are obtained. Instead of relying on a single expert annotator, crowdsourcing shares the labelling effort among a large number of collaborators. For instance, this is being applied to the data acquired by the laureate Laser Interferometer Gravitational Waves Observatory (LIGO), in order to detect glitches which might hinder the identification of true gravitational-waves. The crowdsourcing scenario poses new challenging difficulties, as it deals with different opinions from a heterogeneous group of annotators with unknown degrees of expertise. Probabilistic methods, such as Gaussian Processes (GP), have proven successful in modeling this setting. However, GPs do not scale well to large data sets, which hampers their broad adoption in real practice (in particular at LIGO). This has led to the recent introduction of deep learning based crowdsourcing methods, which have become the state-of-the-art. However, the accurate uncertainty quantification of GPs has been partially sacrificed. This is an important aspect for astrophysicists in LIGO, since a glitch detection system should provide very accurate probability distributions of its predictions. In this work, we leverage the most popular sparse GP approximation to develop a novel GP based crowdsourcing method that factorizes into mini-batches. This makes it able to cope with previously-prohibitive data sets. The approach, which we refer to as Scalable Variational Gaussian Processes for Crowdsourcing (SVGPCR), brings back GP-based methods to the state-of-the-art, and excels at uncertainty quantification. SVGPCR is shown to outperform deep learning based methods and previous probabilistic approaches when applied to the LIGO data. Moreover, its behavior and main properties are carefully analyzed in a controlled experiment based on the MNIST data set.