 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination-Free Automatic Question & Answer Generation for Intuitive Learning
Jan 13, 2026Hallucinations in large language models (LLMs), defined as fluent yet incorrect or incoherent outputs, pose a significant challenge to the automatic generation of educational multiple-choice questions (MCQs). We identified four key hallucination types in MCQ generation: reasoning inconsistencies, insolvability, factual errors, and mathematical errors. To address this, we propose a hallucination-free multi-agent generation framework that breaks down MCQ generation into discrete, verifiable stages. Our framework utilizes both rule-based and LLM-based detection agents, as well as hallucination scoring metrics to optimize question quality. We redefined MCQ generation as an optimization task minimizing hallucination risk while maximizing validity, answerability, and cost-efficiency. We also introduce an agent-led refinement process that uses counterfactual reasoning and chain-of-thought (CoT) to iteratively improve hallucination in question generation. We evaluated a sample of AP- aligned STEM questions, where our system reduced hallucination rates by over 90% compared to baseline generation while preserving the educational value and style of questions. Our results demonstrate that structured multi-agent collaboration can mitigate hallucinations in educational content creation at scale, paving the way for more reliable LLM-powered learning tools.
Physics-Informed Image Restoration via Progressive PDE Integration
Nov 09, 2025Motion blur, caused by relative movement between camera and scene during exposure, significantly degrades image quality and impairs downstream computer vision tasks such as object detection, tracking, and recognition in dynamic environments. While deep learning-based motion deblurring methods have achieved remarkable progress, existing approaches face fundamental challenges in capturing the long-range spatial dependencies inherent in motion blur patterns. Traditional convolutional methods rely on limited receptive fields and require extremely deep networks to model global spatial relationships. These limitations motivate the need for alternative approaches that incorporate physical priors to guide feature evolution during restoration. In this paper, we propose a progressive training framework that integrates physics-informed PDE dynamics into state-of-the-art restoration architectures. By leveraging advection-diffusion equations to model feature evolution, our approach naturally captures the directional flow characteristics of motion blur while enabling principled global spatial modeling. Our PDE-enhanced deblurring models achieve superior restoration quality with minimal overhead, adding only approximately 1\% to inference GMACs while providing consistent improvements in perceptual quality across multiple state-of-the-art architectures. Comprehensive experiments on standard motion deblurring benchmarks demonstrate that our physics-informed approach improves PSNR and SSIM significantly across four diverse architectures, including FFTformer, NAFNet, Restormer, and Stripformer. These results validate that incorporating mathematical physics principles through PDE-based global layers can enhance deep learning-based image restoration, establishing a promising direction for physics-informed neural network design in computer vision applications.
Advancing Limited-Angle CT Reconstruction Through Diffusion-Based Sinogram Completion
May 26, 2025Limited Angle Computed Tomography (LACT) often faces significant challenges due to missing angular information. Unlike previous methods that operate in the image domain, we propose a new method that focuses on sinogram inpainting. We leverage MR-SDEs, a variant of diffusion models that characterize the diffusion process with mean-reverting stochastic differential equations, to fill in missing angular data at the projection level. Furthermore, by combining distillation with constraining the output of the model using the pseudo-inverse of the inpainting matrix, the diffusion process is accelerated and done in a step, enabling efficient and accurate sinogram completion. A subsequent post-processing module back-projects the inpainted sinogram into the image domain and further refines the reconstruction, effectively suppressing artifacts while preserving critical structural details. Quantitative experimental results demonstrate that the proposed method achieves state-of-the-art performance in both perceptual and fidelity quality, offering a promising solution for LACT reconstruction in scientific and clinical applications.
ScarNet: A Novel Foundation Model for Automated Myocardial Scar Quantification from LGE in Cardiac MRI
Jan 02, 2025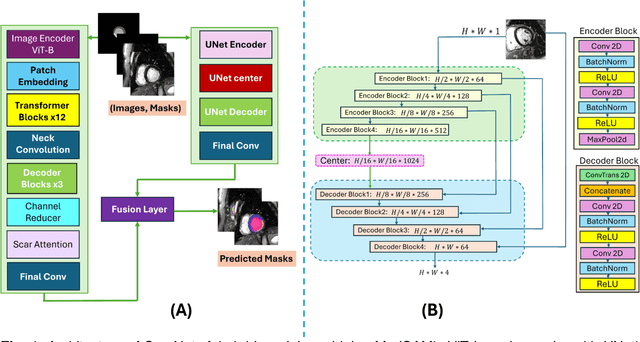
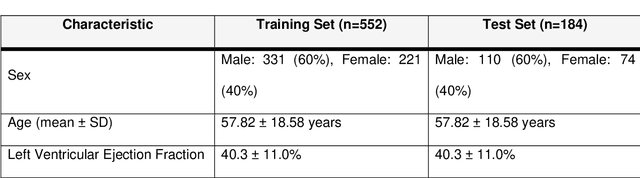
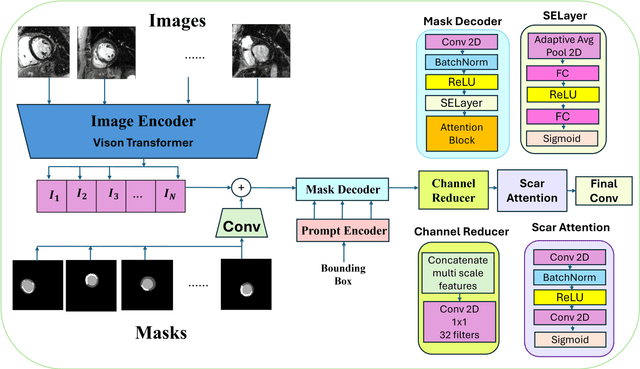
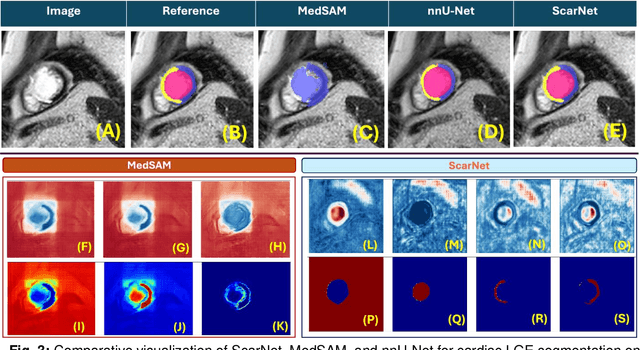
Background: Late Gadolinium Enhancement (LGE) imaging is the gold standard for assessing myocardial fibrosis and scarring, with left ventricular (LV) LGE extent predicting major adverse cardiac events (MACE). Despite its importance, routine LGE-based LV scar quantification is hindered by labor-intensive manual segmentation and inter-observer variability. Methods: We propose ScarNet, a hybrid model combining a transformer-based encoder from the Medical Segment Anything Model (MedSAM) with a convolution-based U-Net decoder, enhanced by tailored attention blocks. ScarNet was trained on 552 ischemic cardiomyopathy patients with expert segmentations of myocardial and scar boundaries and tested on 184 separate patients. Results: ScarNet achieved robust scar segmentation in 184 test patients, yielding a median Dice score of 0.912 (IQR: 0.863--0.944), significantly outperforming MedSAM (median Dice = 0.046, IQR: 0.043--0.047) and nnU-Net (median Dice = 0.638, IQR: 0.604--0.661). ScarNet demonstrated lower bias (-0.63%) and coefficient of variation (4.3%) compared to MedSAM (bias: -13.31%, CoV: 130.3%) and nnU-Net (bias: -2.46%, CoV: 20.3%). In Monte Carlo simulations with noise perturbations, ScarNet achieved significantly higher scar Dice (0.892 \pm 0.053, CoV = 5.9%) than MedSAM (0.048 \pm 0.112, CoV = 233.3%) and nnU-Net (0.615 \pm 0.537, CoV = 28.7%). Conclusion: ScarNet outperformed MedSAM and nnU-Net in accurately segmenting myocardial and scar boundaries in LGE images. The model exhibited robust performance across diverse image qualities and scar patterns.
Sm: enhanced localization in Multiple Instance Learning for medical imaging classification
Oct 04, 2024Multiple Instance Learning (MIL) is widely used in medical imaging classification to reduce the labeling effort. While only bag labels are available for training, one typically seeks predictions at both bag and instance levels (classification and localization tasks, respectively). Early MIL methods treated the instances in a bag independently. Recent methods account for global and local dependencies among instances. Although they have yielded excellent results in classification, their performance in terms of localization is comparatively limited. We argue that these models have been designed to target the classification task, while implications at the instance level have not been deeply investigated. Motivated by a simple observation -- that neighboring instances are likely to have the same label -- we propose a novel, principled, and flexible mechanism to model local dependencies. It can be used alone or combined with any mechanism to model global dependencies (e.g., transformers). A thorough empirical validation shows that our module leads to state-of-the-art performance in localization while being competitive or superior in classification. Our code is at https://github.com/Franblueee/SmMIL.
DRL-STNet: Unsupervised Domain Adaptation for Cross-modality Medical Image Segmentation via Disentangled Representation Learning
Sep 26, 2024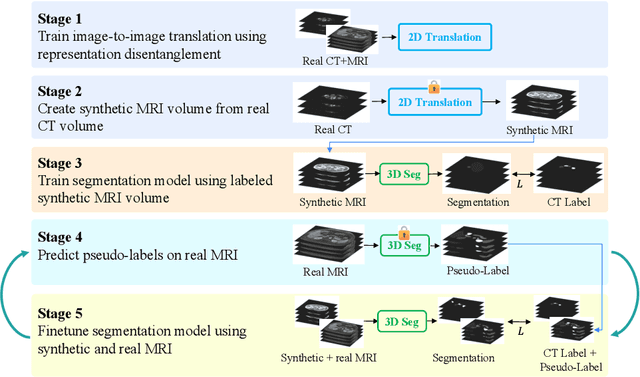

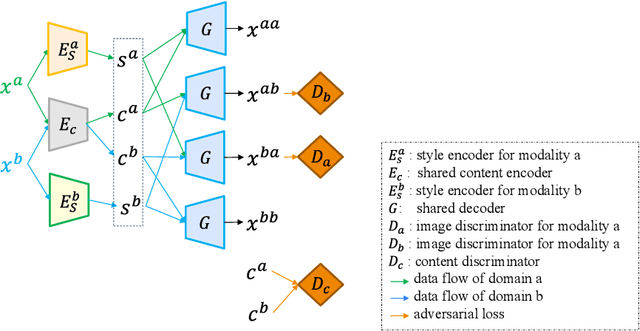
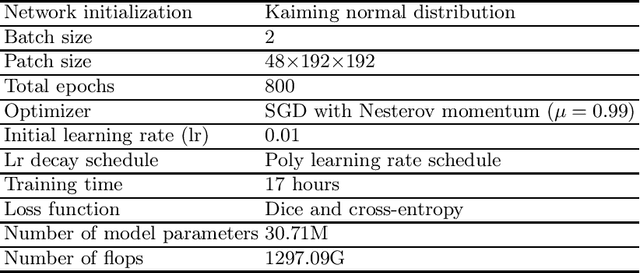
Unsupervised domain adaptation (UDA) is essential for medical image segmentation, especially in cross-modality data scenarios. UDA aims to transfer knowledge from a labeled source domain to an unlabeled target domain, thereby reducing the dependency on extensive manual annotations. This paper presents DRL-STNet, a novel framework for cross-modality medical image segmentation that leverages generative adversarial networks (GANs), disentangled representation learning (DRL), and self-training (ST). Our method leverages DRL within a GAN to translate images from the source to the target modality. Then, the segmentation model is initially trained with these translated images and corresponding source labels and then fine-tuned iteratively using a combination of synthetic and real images with pseudo-labels and real labels. The proposed framework exhibits superior performance in abdominal organ segmentation on the FLARE challenge dataset, surpassing state-of-the-art methods by 11.4% in the Dice similarity coefficient and by 13.1% in the Normalized Surface Dice metric, achieving scores of 74.21% and 80.69%, respectively. The average running time is 41 seconds, and the area under the GPU memory-time curve is 11,292 MB. These results indicate the potential of DRL-STNet for enhancing cross-modality medical image segmentation tasks.
RN-SDEs: Limited-Angle CT Reconstruction with Residual Null-Space Diffusion Stochastic Differential Equations
Sep 20, 2024Computed tomography is a widely used imaging modality with applications ranging from medical imaging to material analysis. One major challenge arises from the lack of scanning information at certain angles, leading to distorted CT images with artifacts. This results in an ill-posed problem known as the Limited Angle Computed Tomography (LACT) reconstruction problem. To address this problem, we propose Residual Null-Space Diffusion Stochastic Differential Equations (RN-SDEs), which are a variant of diffusion models that characterize the diffusion process with mean-reverting (MR) stochastic differential equations. To demonstrate the generalizability of RN-SDEs, our experiments are conducted on two different LACT datasets, i.e., ChromSTEM and C4KC-KiTS. Through extensive experiments, we show that by leveraging learned Mean-Reverting SDEs as a prior and emphasizing data consistency using Range-Null Space Decomposition (RNSD) based rectification, RN-SDEs can restore high-quality images from severe degradation and achieve state-of-the-art performance in most LACT tasks. Additionally, we present a quantitative comparison of computational complexity and runtime efficiency, highlighting the superior effectiveness of our proposed approach.
VDPI: Video Deblurring with Pseudo-inverse Modeling
Sep 01, 2024



Video deblurring is a challenging task that aims to recover sharp sequences from blur and noisy observations. The image-formation model plays a crucial role in traditional model-based methods, constraining the possible solutions. However, this is only the case for some deep learning-based methods. Despite deep-learning models achieving better results, traditional model-based methods remain widely popular due to their flexibility. An increasing number of scholars combine the two to achieve better deblurring performance. This paper proposes introducing knowledge of the image-formation model into a deep learning network by using the pseudo-inverse of the blur. We use a deep network to fit the blurring and estimate pseudo-inverse. Then, we use this estimation, combined with a variational deep-learning network, to deblur the video sequence. Notably, our experimental results demonstrate that such modifications can significantly improve the performance of deep learning models for video deblurring. Furthermore, our experiments on different datasets achieved notable performance improvements, proving that our proposed method can generalize to different scenarios and cameras.
Modeling and Simulation of Charge-Induced Signals in Photon-Counting CZT Detectors for Medical Imaging Applications
May 21, 2024


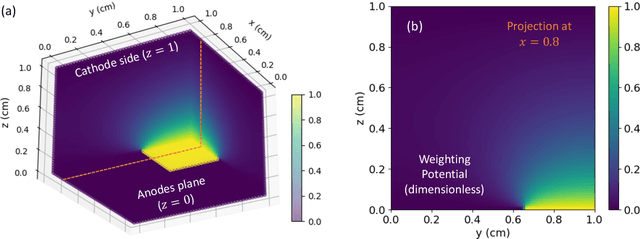
Photon-counting detectors based on CZT are essential in nuclear medical imaging, particularly for SPECT applications. Although CZT detectors are known for their precise energy resolution, defects within the CZT crystals significantly impact their performance. These defects result in inhomogeneous material properties throughout the bulk of the detector. The present work introduces an efficient computational model that simulates the operation of semiconductor detectors, accounting for the spatial variability of the crystal properties. Our simulator reproduces the charge-induced pulse signals generated after the X/gamma-rays interact with the detector. The performance evaluation of the model shows an RMSE in the signal below 0.70%. Our simulator can function as a digital twin to accurately replicate the operation of actual detectors. Thus, it can be used to mitigate and compensate for adverse effects arising from crystal impurities.
Brighteye: Glaucoma Screening with Color Fundus Photographs based on Vision Transformer
May 01, 2024Differences in image quality, lighting conditions, and patient demographics pose challenges to automated glaucoma detection from color fundus photography. Brighteye, a method based on Vision Transformer, is proposed for glaucoma detection and glaucomatous feature classification. Brighteye learns long-range relationships among pixels within large fundus images using a self-attention mechanism. Prior to being input into Brighteye, the optic disc is localized using YOLOv8, and the region of interest (ROI) around the disc center is cropped to ensure alignment with clinical practice. Optic disc detection improves the sensitivity at 95% specificity from 79.20% to 85.70% for glaucoma detection and the Hamming distance from 0.2470 to 0.1250 for glaucomatous feature classification. In the developmental stage of the Justified Referral in AI Glaucoma Screening (JustRAIGS) challenge, the overall outcome secured the fifth position out of 226 entries.