 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conversational Head Dynamics
Dec 17, 2025



Human conversation involves continuous exchanges of speech and nonverbal cues such as head nods, gaze shifts, and facial expressions that convey attention and emotion. Modeling these bidirectional dynamics in 3D is essential for building expressive avatars and interactive robots. However, existing frameworks often treat talking and listening as independent processes or rely on non-causal full-sequence modeling, hindering temporal coherence across turns. We present TIMAR (Turn-level Interleaved Masked AutoRegression), a causal framework for 3D conversational head generation that models dialogue as interleaved audio-visual contexts. It fuses multimodal information within each turn and applies turn-level causal attention to accumulate conversational history, while a lightweight diffusion head predicts continuous 3D head dynamics that captures both coordination and expressive variability. Experiments on the DualTalk benchmark show that TIMAR reduces Fréchet Distance and MSE by 15-30% on the test set, and achieves similar gains on out-of-distribution data. The source code will be released in the GitHub repository https://github.com/CoderChen01/towards-seamleass-interaction.
ViewMask-1-to-3: Multi-View Consistent Image Generation via Multimodal Diffusion Models
Dec 16, 2025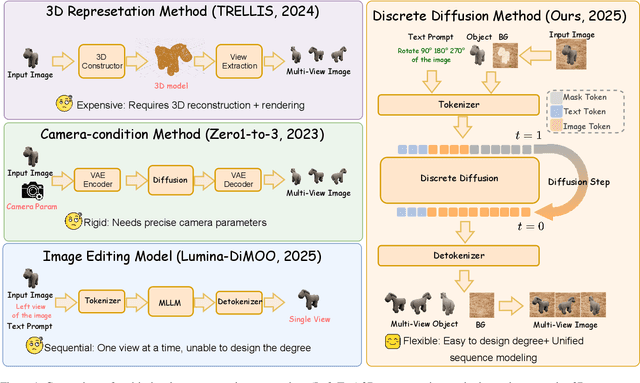
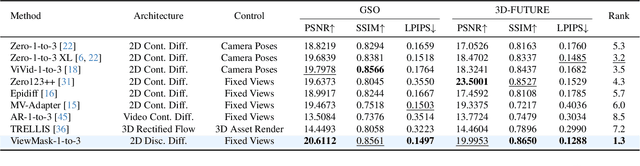
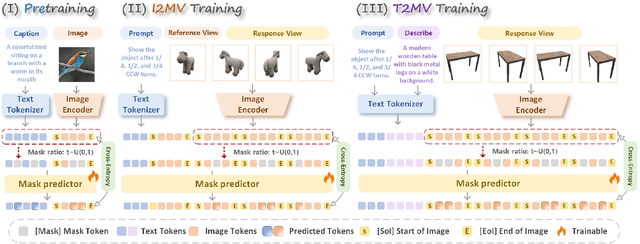
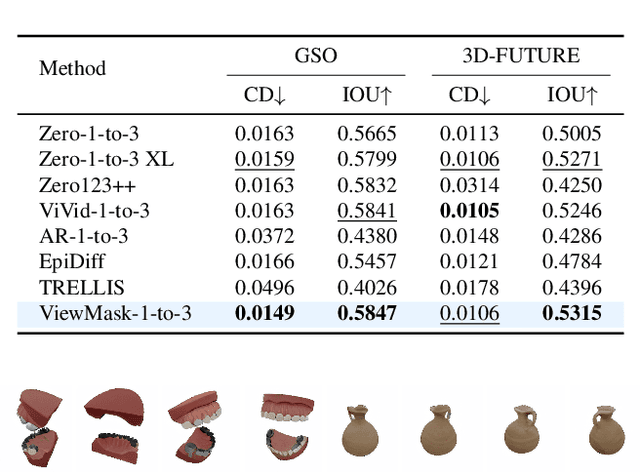
Multi-view image generation from a single image and text description remains challenging due to the difficulty of maintaining geometric consistency across different viewpoints. Existing approaches typically rely on 3D-aware architectures or specialized diffusion models that require extensive multi-view training data and complex geometric priors. In this work, we introduce ViewMask-1-to-3, a pioneering approach to apply discrete diffusion models to multi-view image generation. Unlike continuous diffusion methods that operate in latent spaces, ViewMask-1-to-3 formulates multi-view synthesis as a discrete sequence modeling problem, where each viewpoint is represented as visual tokens obtained through MAGVIT-v2 tokenization. By unifying language and vision through masked token prediction, our approach enables progressive generation of multiple viewpoints through iterative token unmasking with text input. ViewMask-1-to-3 achieves cross-view consistency through simple random masking combined with self-attention, eliminating the requirement for complex 3D geometric constraints or specialized attention architectures. Our approach demonstrates that discrete diffusion provides a viable and simple alternative to existing multi-view generation methods, ranking first on average across GSO and 3D-FUTURE datasets in terms of PSNR, SSIM, and LPIPS, while maintaining architectural simplicity.
NFIG: Autoregressive Image Generation with Next-Frequency Prediction
Mar 10, 2025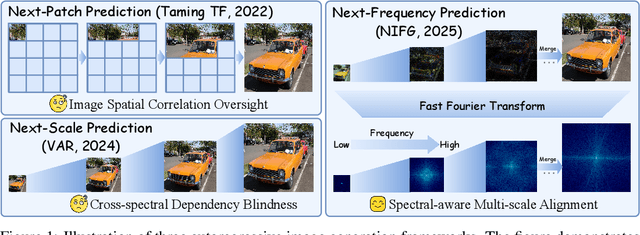

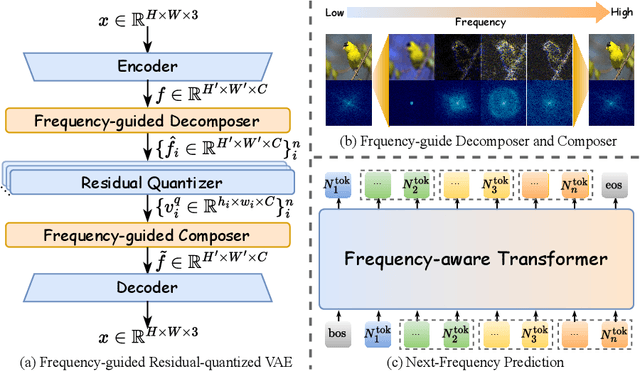
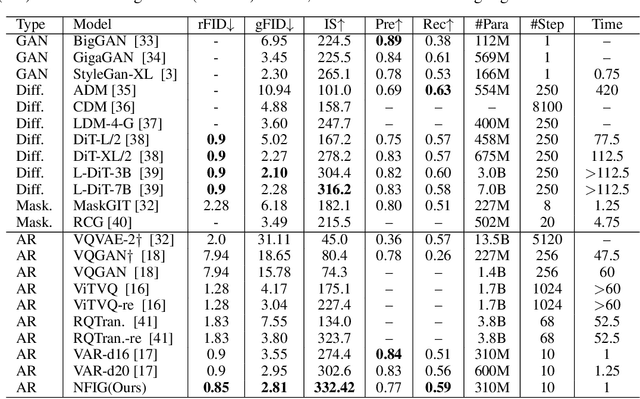
Autoregressive models have achieved promising results in natural language processing. However, for image generation tasks, they encounter substantial challenges in effectively capturing long-range dependencies, managing computational costs, and most crucially, defining meaningful autoregressive sequences that reflect natural image hierarchies. To address these issues, we present \textbf{N}ext-\textbf{F}requency \textbf{I}mage \textbf{G}eneration (\textbf{NFIG}), a novel framework that decomposes the image generation process into multiple frequency-guided stages. Our approach first generates low-frequency components to establish global structure with fewer tokens, then progressively adds higher-frequency details, following the natural spectral hierarchy of images. This principled autoregressive sequence not only improves the quality of generated images by better capturing true causal relationships between image components, but also significantly reduces computational overhead during inference. Extensive experiments demonstrate that NFIG achieves state-of-the-art performance with fewer steps, offering a more efficient solution for image generation, with 1.25$\times$ speedup compared to VAR-d20 while achieving better performance (FID: 2.81) on the ImageNet-256 benchmark. We hope that our insight of incorporating frequency-domain knowledge to guide autoregressive sequence design will shed light on future research. We will make our code publicly available upon acceptance of the paper.
VDPI: Video Deblurring with Pseudo-inverse Modeling
Sep 01, 2024



Video deblurring is a challenging task that aims to recover sharp sequences from blur and noisy observations. The image-formation model plays a crucial role in traditional model-based methods, constraining the possible solutions. However, this is only the case for some deep learning-based methods. Despite deep-learning models achieving better results, traditional model-based methods remain widely popular due to their flexibility. An increasing number of scholars combine the two to achieve better deblurring performance. This paper proposes introducing knowledge of the image-formation model into a deep learning network by using the pseudo-inverse of the blur. We use a deep network to fit the blurring and estimate pseudo-inverse. Then, we use this estimation, combined with a variational deep-learning network, to deblur the video sequence. Notably, our experimental results demonstrate that such modifications can significantly improve the performance of deep learning models for video deblurring. Furthermore, our experiments on different datasets achieved notable performance improvements, proving that our proposed method can generalize to different scenarios and cameras.