 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTLB-STRUCT @PARSEME 2020: Capturing Unseen Multiword Expressions Using Multi-task Learning and Pre-trained Masked Language Models
Nov 04, 2020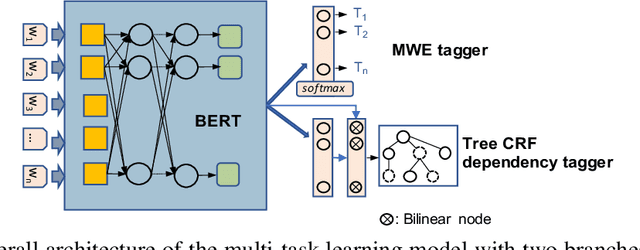

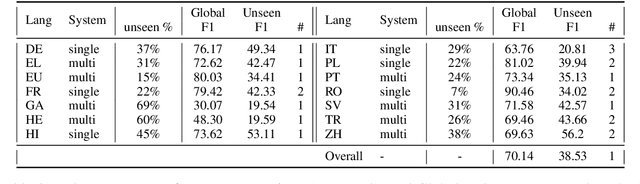
This paper describes a semi-supervised system that jointly learns verbal multiword expressions (VMWEs) and dependency parse trees as an auxiliary task. The model benefits from pre-trained multilingual BERT. BERT hidden layers are shared among the two tasks and we introduce an additional linear layer to retrieve VMWE tags. The dependency parse tree prediction is modelled by a linear layer and a bilinear one plus a tree CRF on top of BERT. The system has participated in the open track of the PARSEME shared task 2020 and ranked first in terms of F1-score in identifying unseen VMWEs as well as VMWEs in general, averaged across all 14 languages.
Leveraging Semi-Supervised Learning for Fairness using Neural Networks
Dec 31, 2019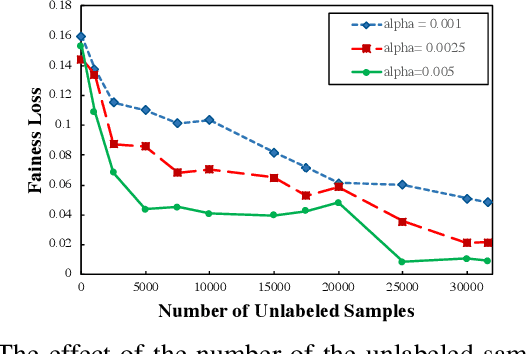
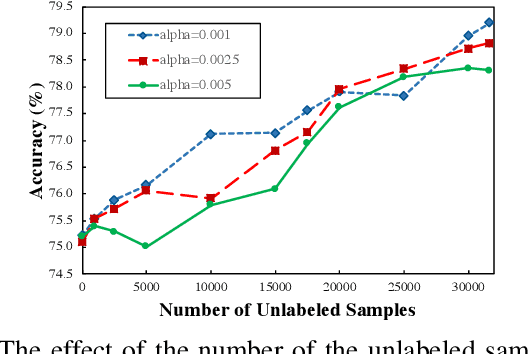
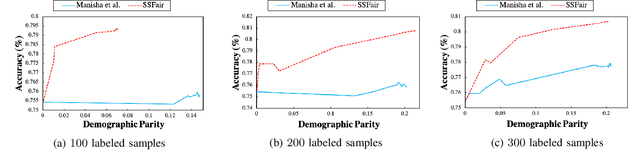
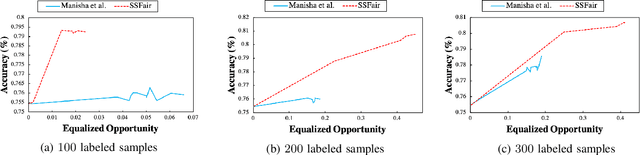
There has been a growing concern about the fairness of decision-making systems based on machine learning. The shortage of labeled data has been always a challenging problem facing machine learning based systems. In such scenarios, semi-supervised learning has shown to be an effective way of exploiting unlabeled data to improve upon the performance of model. Notably, unlabeled data do not contain label information which itself can be a significant source of bias in training machine learning systems. This inspired us to tackle the challenge of fairness by formulating the problem in a semi-supervised framework. In this paper, we propose a semi-supervised algorithm using neural networks benefiting from unlabeled data to not just improve the performance but also improve the fairness of the decision-making process. The proposed model, called SSFair, exploits the information in the unlabeled data to mitigate the bias in the training data.
Semi-supervised Deep Representation Learning for Multi-View Problems
Nov 11, 2018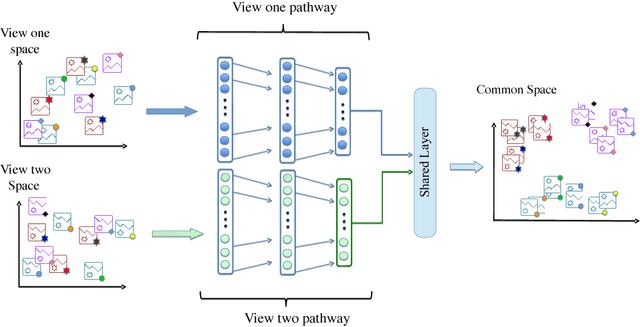
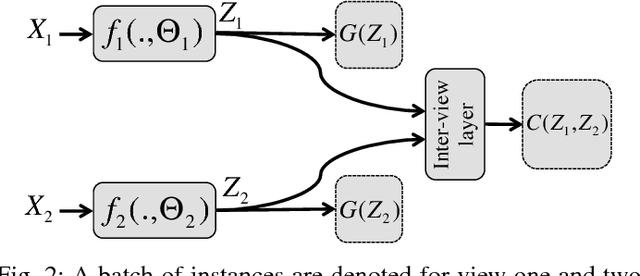

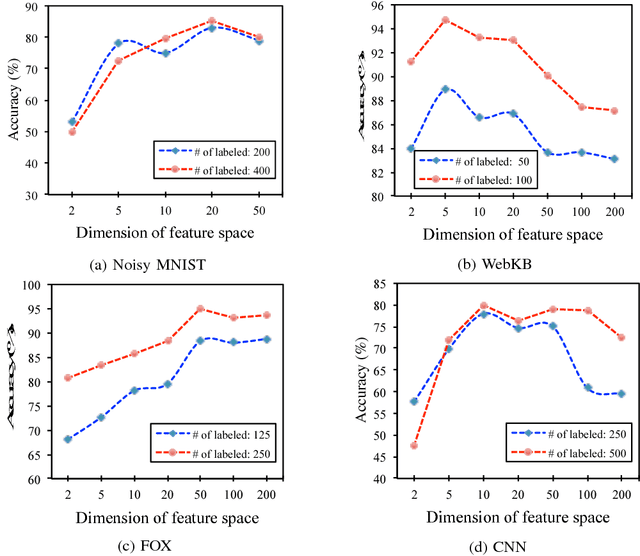
While neural networks for learning representation of multi-view data have been previously proposed as one of the state-of-the-art multi-view dimension reduction techniques, how to make the representation discriminative with only a small amount of labeled data is not well-studied. We introduce a semi-supervised neural network model, named Multi-view Discriminative Neural Network (MDNN), for multi-view problems. MDNN finds nonlinear view-specific mappings by projecting samples to a common feature space using multiple coupled deep networks. It is capable of leveraging both labeled and unlabeled data to project multi-view data so that samples from different classes are separated and those from the same class are clustered together. It also uses the inter-view correlation between views to exploit the available information in both the labeled and unlabeled data. Extensive experiments conducted on four datasets demonstrate the effectiveness of the proposed algorithm for multi-view semi-supervised learning.
DIRECT: Deep Discriminative Embedding for Clustering of LIGO Data
May 07, 2018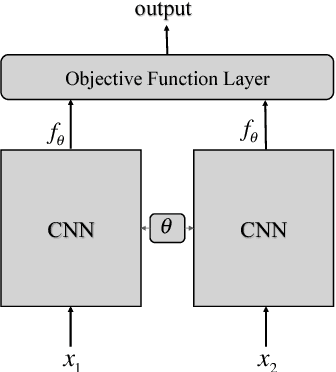
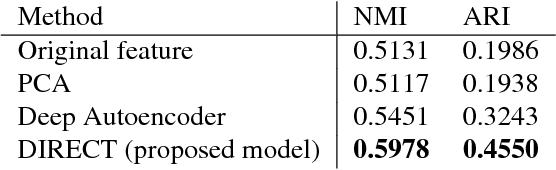
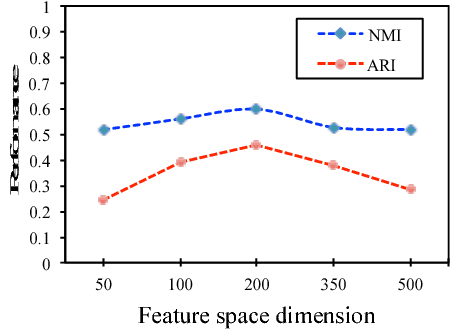
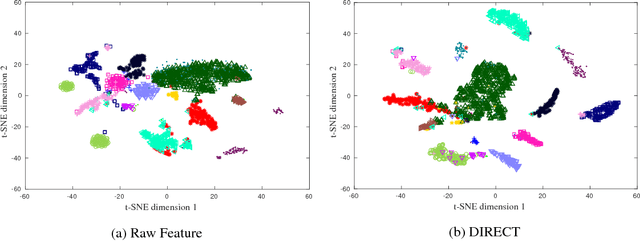
In this paper, benefiting from the strong ability of deep neural network in estimating non-linear functions, we propose a discriminative embedding function to be used as a feature extractor for clustering tasks. The trained embedding function transfers knowledge from the domain of a labeled set of morphologically-distinct images, known as classes, to a new domain within which new classes can potentially be isolated and identified. Our target application in this paper is the Gravity Spy Project, which is an effort to characterize transient, non-Gaussian noise present in data from the Advanced Laser Interferometer Gravitational-wave Observatory, or LIGO. Accumulating large, labeled sets of noise features and identifying of new classes of noise lead to a better understanding of their origin, which makes their removal from the data and/or detectors possible.
SEVEN: Deep Semi-supervised Verification Networks
Jun 14, 2017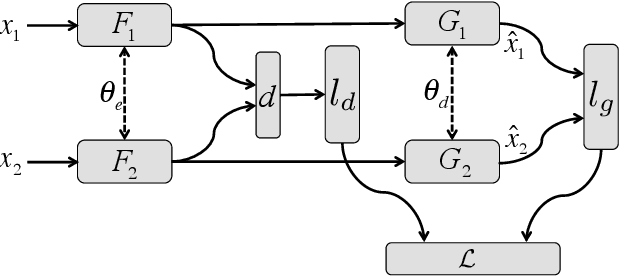


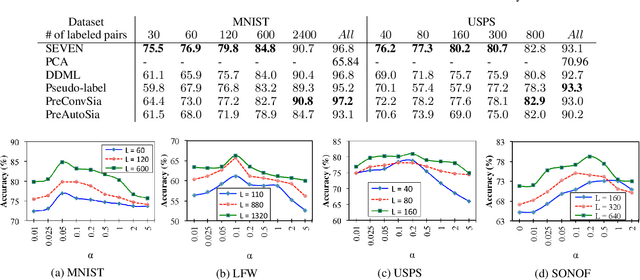
Verification determines whether two samples belong to the same class or not, and has important applications such as face and fingerprint verification, where thousands or millions of categories are present but each category has scarce labeled examples, presenting two major challenges for existing deep learning models. We propose a deep semi-supervised model named SEmi-supervised VErification Network (SEVEN) to address these challenges. The model consists of two complementary components. The generative component addresses the lack of supervision within each category by learning general salient structures from a large amount of data across categories. The discriminative component exploits the learned general features to mitigate the lack of supervision within categories, and also directs the generative component to find more informative structures of the whole data manifold. The two components are tied together in SEVEN to allow an end-to-end training of the two components. Extensive experiments on four verification tasks demonstrate that SEVEN significantly outperforms other state-of-the-art deep semi-supervised techniques when labeled data are in short supply. Furthermore, SEVEN is competitive with fully supervised baselines trained with a larger amount of labeled data. It indicates the importance of the generative component in SEVEN.
Deep Multi-view Models for Glitch Classification
Apr 28, 2017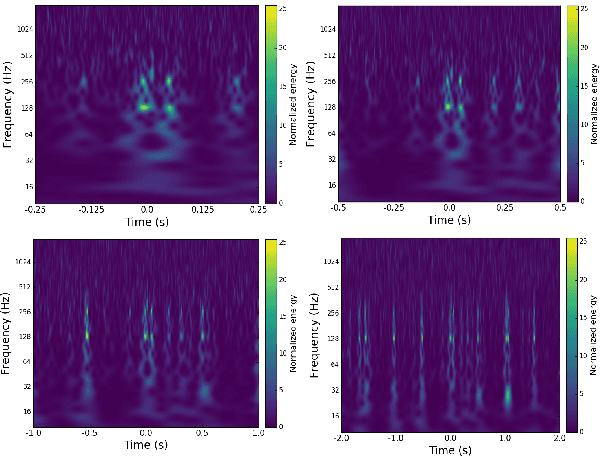

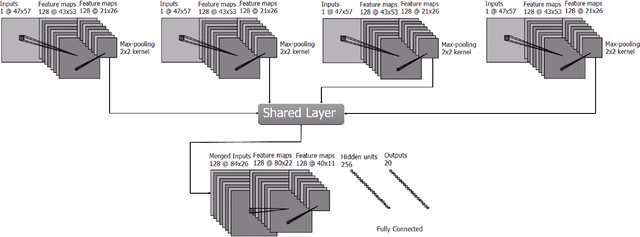
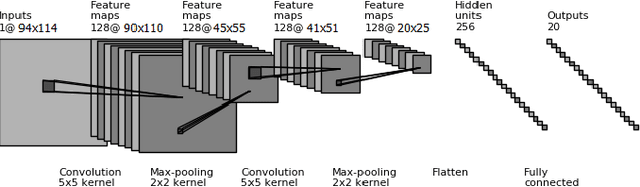
Non-cosmic, non-Gaussian disturbances known as "glitches", show up in gravitational-wave data of the Advanced Laser Interferometer Gravitational-wave Observatory, or aLIGO. In this paper, we propose a deep multi-view convolutional neural network to classify glitches automatically. The primary purpose of classifying glitches is to understand their characteristics and origin, which facilitates their removal from the data or from the detector entirely. We visualize glitches as spectrograms and leverage the state-of-the-art image classification techniques in our model. The suggested classifier is a multi-view deep neural network that exploits four different views for classification. The experimental results demonstrate that the proposed model improves the overall accuracy of the classification compared to traditional single view algorithms.