 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Deep Representation Learning for Multi-View Problems
Nov 11, 2018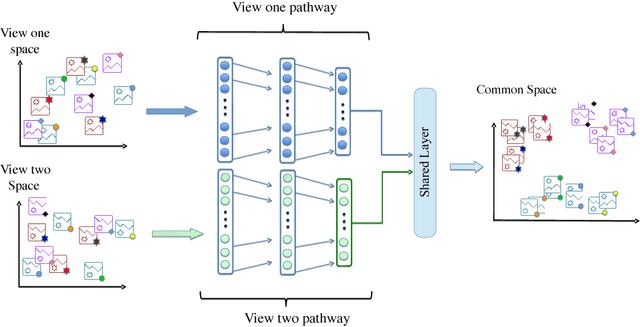
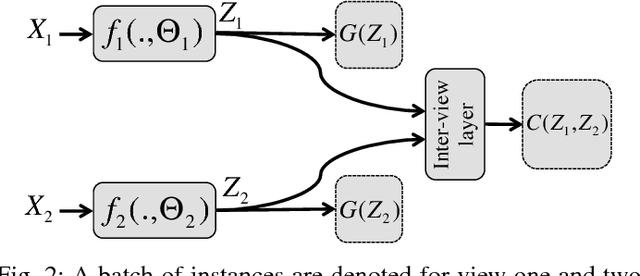

While neural networks for learning representation of multi-view data have been previously proposed as one of the state-of-the-art multi-view dimension reduction techniques, how to make the representation discriminative with only a small amount of labeled data is not well-studied. We introduce a semi-supervised neural network model, named Multi-view Discriminative Neural Network (MDNN), for multi-view problems. MDNN finds nonlinear view-specific mappings by projecting samples to a common feature space using multiple coupled deep networks. It is capable of leveraging both labeled and unlabeled data to project multi-view data so that samples from different classes are separated and those from the same class are clustered together. It also uses the inter-view correlation between views to exploit the available information in both the labeled and unlabeled data. Extensive experiments conducted on four datasets demonstrate the effectiveness of the proposed algorithm for multi-view semi-supervised learning.
Online Multi-view Clustering with Incomplete Views
Nov 06, 2016
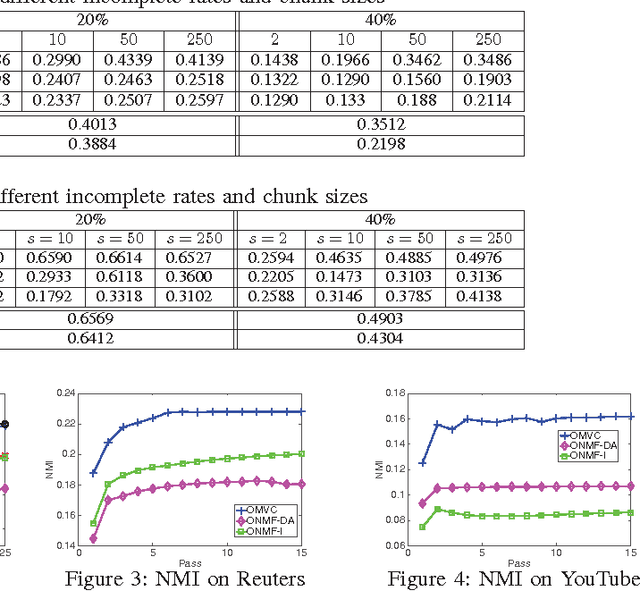
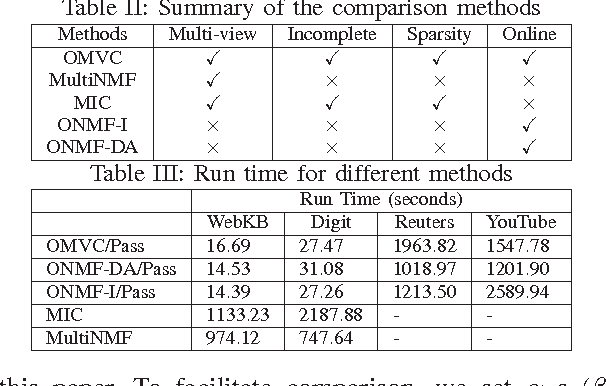
In the era of big data, it is common to have data with multiple modalities or coming from multiple sources, known as "multi-view data". Multi-view clustering provides a natural way to generate clusters from such data. Since different views share some consistency and complementary information, previous works on multi-view clustering mainly focus on how to combine various numbers of views to improve clustering performance. However, in reality, each view may be incomplete, i.e., instances missing in the view. Furthermore, the size of data could be extremely huge. It is unrealistic to apply multi-view clustering in large real-world applications without considering the incompleteness of views and the memory requirement. None of previous works have addressed all these challenges simultaneously. In this paper, we propose an online multi-view clustering algorithm, OMVC, which deals with large-scale incomplete views. We model the multi-view clustering problem as a joint weighted nonnegative matrix factorization problem and process the multi-view data chunk by chunk to reduce the memory requirement. OMVC learns the latent feature matrices for all the views and pushes them towards a consensus. We further increase the robustness of the learned latent feature matrices in OMVC via lasso regularization. To minimize the influence of incompleteness, dynamic weight setting is introduced to give lower weights to the incoming missing instances in different views. More importantly, to reduce the computational time, we incorporate a faster projected gradient descent by utilizing the Hessian matrices in OMVC. Extensive experiments conducted on four real data demonstrate the effectiveness of the proposed OMVC method.
Online Unsupervised Multi-view Feature Selection
Sep 27, 2016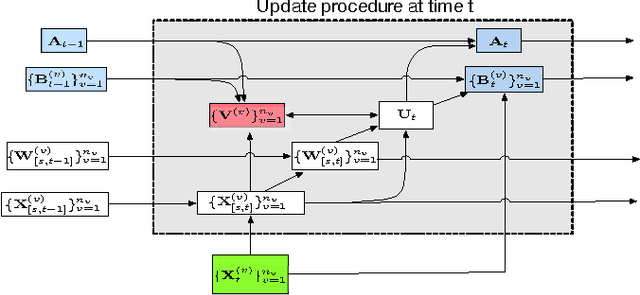
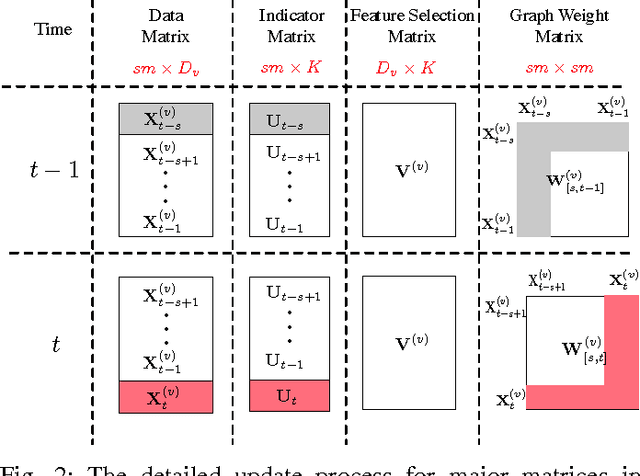
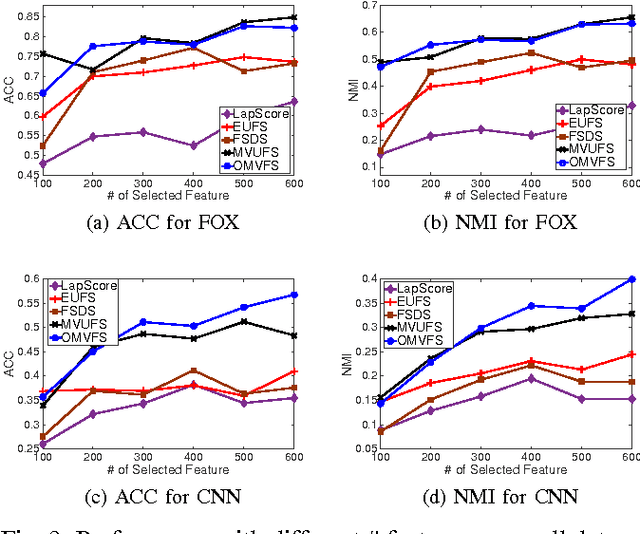
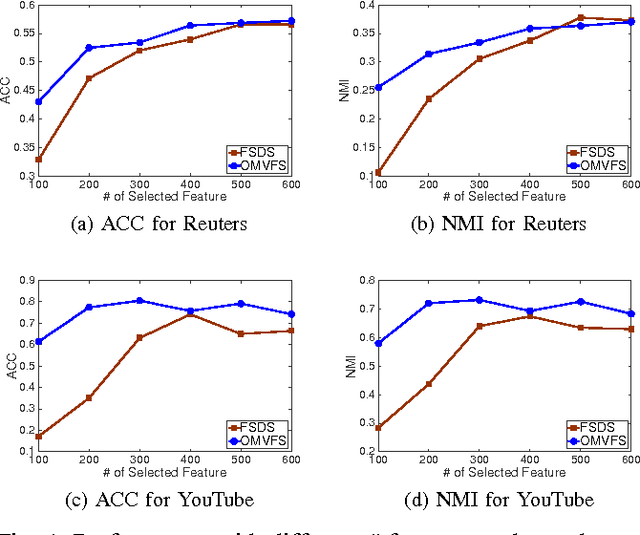
In the era of big data, it is becoming common to have data with multiple modalities or coming from multiple sources, known as "multi-view data". Multi-view data are usually unlabeled and come from high-dimensional spaces (such as language vocabularies), unsupervised multi-view feature selection is crucial to many applications. However, it is nontrivial due to the following challenges. First, there are too many instances or the feature dimensionality is too large. Thus, the data may not fit in memory. How to select useful features with limited memory space? Second, how to select features from streaming data and handles the concept drift? Third, how to leverage the consistent and complementary information from different views to improve the feature selection in the situation when the data are too big or come in as streams? To the best of our knowledge, none of the previous works can solve all the challenges simultaneously. In this paper, we propose an Online unsupervised Multi-View Feature Selection, OMVFS, which deals with large-scale/streaming multi-view data in an online fashion. OMVFS embeds unsupervised feature selection into a clustering algorithm via NMF with sparse learning. It further incorporates the graph regularization to preserve the local structure information and help select discriminative features. Instead of storing all the historical data, OMVFS processes the multi-view data chunk by chunk and aggregates all the necessary information into several small matrices. By using the buffering technique, the proposed OMVFS can reduce the computational and storage cost while taking advantage of the structure information. Furthermore, OMVFS can capture the concept drifts in the data streams. Extensive experiments on four real-world datasets show the effectiveness and efficiency of the proposed OMVFS method. More importantly, OMVFS is about 100 times faster than the off-line methods.
Clustering on Multiple Incomplete Datasets via Collective Kernel Learning
May 06, 2016
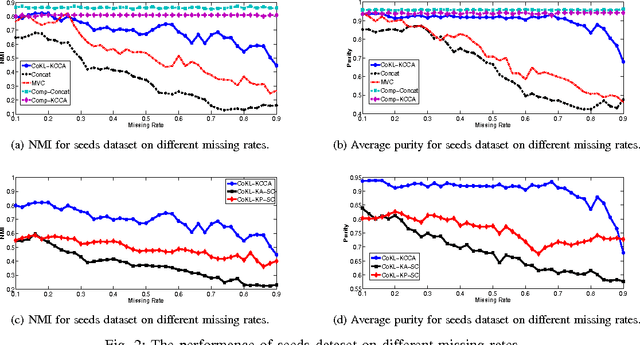
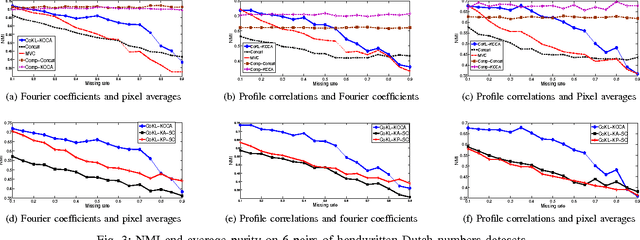
Multiple datasets containing different types of features may be available for a given task. For instance, users' profiles can be used to group users for recommendation systems. In addition, a model can also use users' historical behaviors and credit history to group users. Each dataset contains different information and suffices for learning. A number of clustering algorithms on multiple datasets were proposed during the past few years. These algorithms assume that at least one dataset is complete. So far as we know, all the previous methods will not be applicable if there is no complete dataset available. However, in reality, there are many situations where no dataset is complete. As in building a recommendation system, some new users may not have a profile or historical behaviors, while some may not have a credit history. Hence, no available dataset is complete. In order to solve this problem, we propose an approach called Collective Kernel Learning to infer hidden sample similarity from multiple incomplete datasets. The idea is to collectively completes the kernel matrices of incomplete datasets by optimizing the alignment of the shared instances of the datasets. Furthermore, a clustering algorithm is proposed based on the kernel matrix. The experiments on both synthetic and real datasets demonstrate the effectiveness of the proposed approach. The proposed clustering algorithm outperforms the comparison algorithms by as much as two times in normalized mutual information.
Multi-Source Multi-View Clustering via Discrepancy Penalty
Apr 19, 2016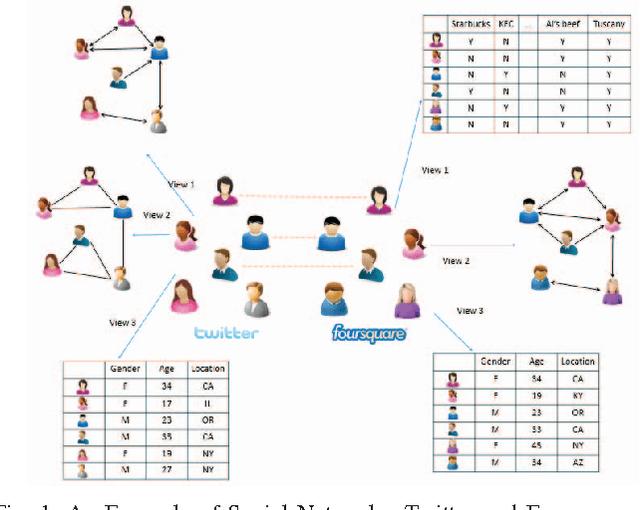
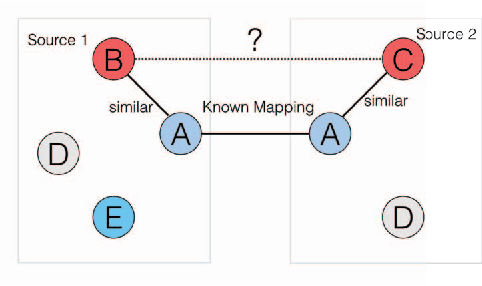
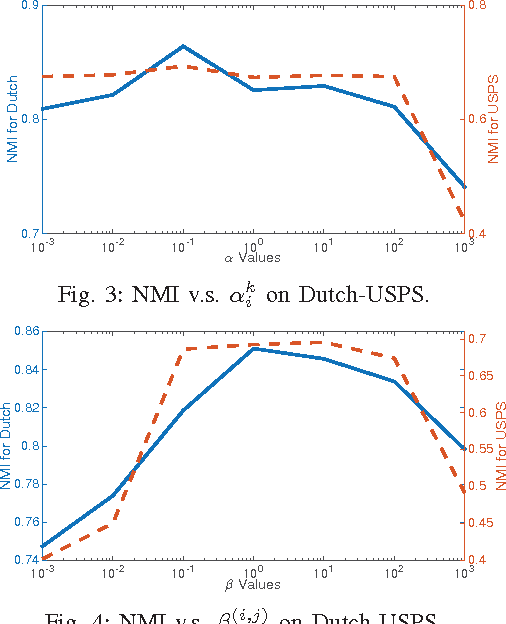

With the advance of technology, entities can be observed in multiple views. Multiple views containing different types of features can be used for clustering. Although multi-view clustering has been successfully applied in many applications, the previous methods usually assume the complete instance mapping between different views. In many real-world applications, information can be gathered from multiple sources, while each source can contain multiple views, which are more cohesive for learning. The views under the same source are usually fully mapped, but they can be very heterogeneous. Moreover, the mappings between different sources are usually incomplete and partially observed, which makes it more difficult to integrate all the views across different sources. In this paper, we propose MMC (Multi-source Multi-view Clustering), which is a framework based on collective spectral clustering with a discrepancy penalty across sources, to tackle these challenges. MMC has several advantages compared with other existing methods. First, MMC can deal with incomplete mapping between sources. Second, it considers the disagreements between sources while treating views in the same source as a cohesive set. Third, MMC also tries to infer the instance similarities across sources to enhance the clustering performance. Extensive experiments conducted on real-world data demonstrate the effectiveness of the proposed approach.