 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering on Multiple Incomplete Datasets via Collective Kernel Learning
Paper and Code

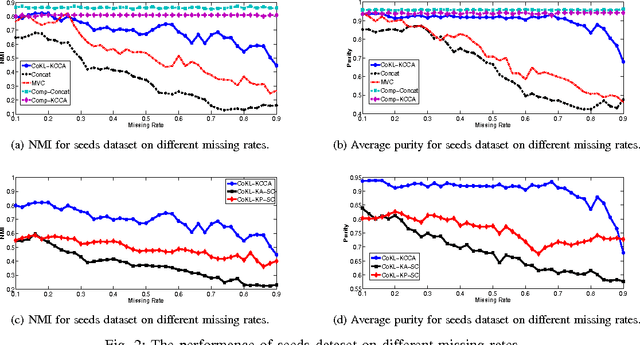
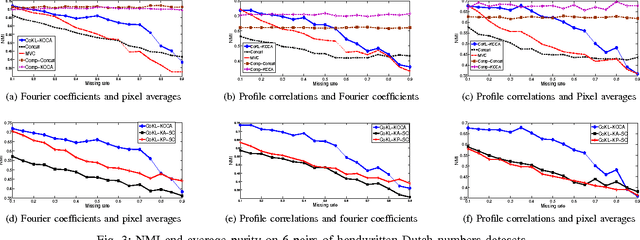
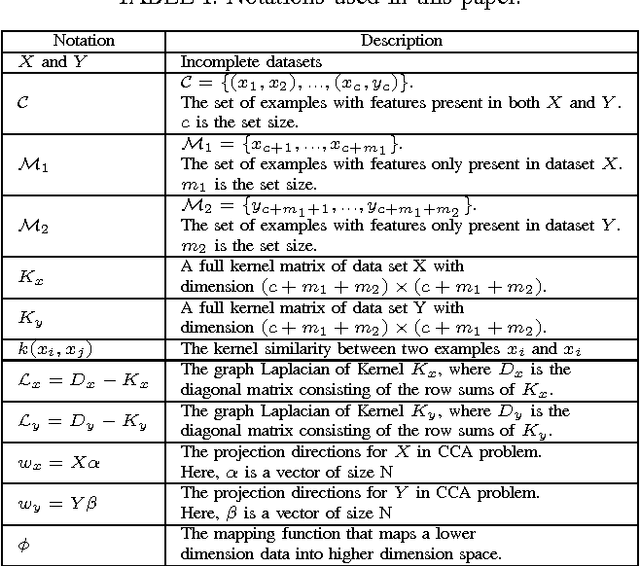
Multiple datasets containing different types of features may be available for a given task. For instance, users' profiles can be used to group users for recommendation systems. In addition, a model can also use users' historical behaviors and credit history to group users. Each dataset contains different information and suffices for learning. A number of clustering algorithms on multiple datasets were proposed during the past few years. These algorithms assume that at least one dataset is complete. So far as we know, all the previous methods will not be applicable if there is no complete dataset available. However, in reality, there are many situations where no dataset is complete. As in building a recommendation system, some new users may not have a profile or historical behaviors, while some may not have a credit history. Hence, no available dataset is complete. In order to solve this problem, we propose an approach called Collective Kernel Learning to infer hidden sample similarity from multiple incomplete datasets. The idea is to collectively completes the kernel matrices of incomplete datasets by optimizing the alignment of the shared instances of the datasets. Furthermore, a clustering algorithm is proposed based on the kernel matrix. The experiments on both synthetic and real datasets demonstrate the effectiveness of the proposed approach. The proposed clustering algorithm outperforms the comparison algorithms by as much as two times in normalized mutual information.