 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Unsupervised Multi-view Feature Selection
Paper and Code
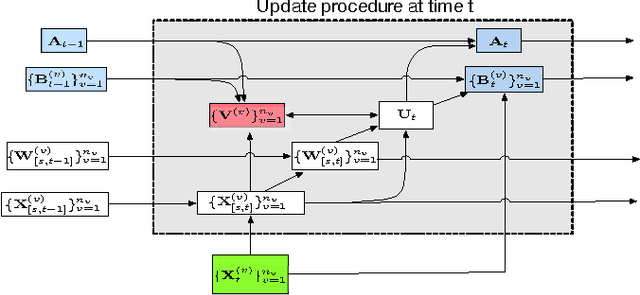
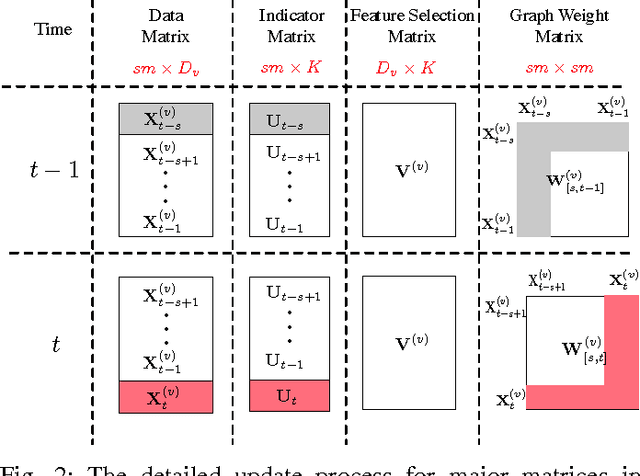
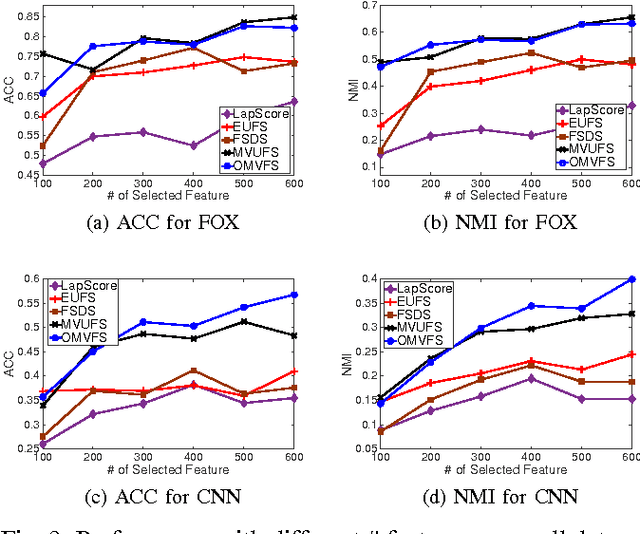
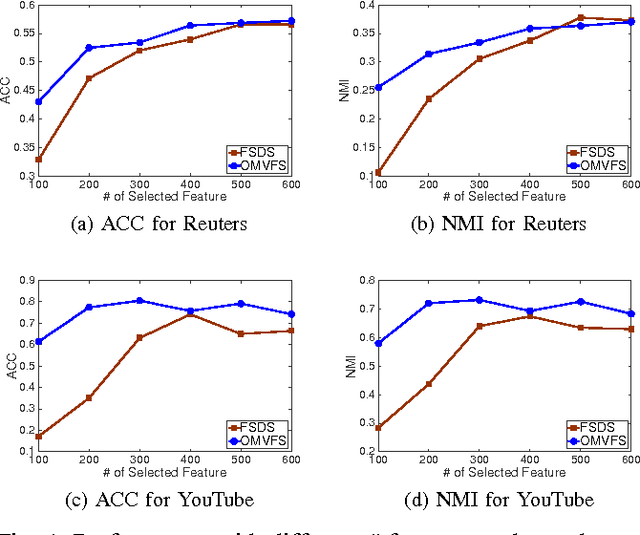
In the era of big data, it is becoming common to have data with multiple modalities or coming from multiple sources, known as "multi-view data". Multi-view data are usually unlabeled and come from high-dimensional spaces (such as language vocabularies), unsupervised multi-view feature selection is crucial to many applications. However, it is nontrivial due to the following challenges. First, there are too many instances or the feature dimensionality is too large. Thus, the data may not fit in memory. How to select useful features with limited memory space? Second, how to select features from streaming data and handles the concept drift? Third, how to leverage the consistent and complementary information from different views to improve the feature selection in the situation when the data are too big or come in as streams? To the best of our knowledge, none of the previous works can solve all the challenges simultaneously. In this paper, we propose an Online unsupervised Multi-View Feature Selection, OMVFS, which deals with large-scale/streaming multi-view data in an online fashion. OMVFS embeds unsupervised feature selection into a clustering algorithm via NMF with sparse learning. It further incorporates the graph regularization to preserve the local structure information and help select discriminative features. Instead of storing all the historical data, OMVFS processes the multi-view data chunk by chunk and aggregates all the necessary information into several small matrices. By using the buffering technique, the proposed OMVFS can reduce the computational and storage cost while taking advantage of the structure information. Furthermore, OMVFS can capture the concept drifts in the data streams. Extensive experiments on four real-world datasets show the effectiveness and efficiency of the proposed OMVFS method. More importantly, OMVFS is about 100 times faster than the off-line methods.