 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryCD: Benchmarking Long-Context User Memory of LLM Agents for Lifelong Cross-Domain Personalization
Mar 26, 2026Recent advancements in Large Language Models (LLMs) have expanded context windows to million-token scales, yet benchmarks for evaluating memory remain limited to short-session synthetic dialogues. We introduce \textsc{MemoryCD}, the first large-scale, user-centric, cross-domain memory benchmark derived from lifelong real-world behaviors in the Amazon Review dataset. Unlike existing memory datasets that rely on scripted personas to generate synthetic user data, \textsc{MemoryCD} tracks authentic user interactions across years and multiple domains. We construct a multi-faceted long-context memory evaluation pipeline of 14 state-of-the-art LLM base models with 6 memory method baselines on 4 distinct personalization tasks over 12 diverse domains to evaluate an agent's ability to simulate real user behaviors in both single and cross-domain settings. Our analysis reveals that existing memory methods are far from user satisfaction in various domains, offering the first testbed for cross-domain life-long personalization evaluation.
Rotate Both Ways: Time-and-Order RoPE for Generative Recommendation
Oct 23, 2025Generative recommenders, typically transformer-based autoregressive models, predict the next item or action from a user's interaction history. Their effectiveness depends on how the model represents where an interaction event occurs in the sequence (discrete index) and when it occurred in wall-clock time. Prevailing approaches inject time via learned embeddings or relative attention biases. In this paper, we argue that RoPE-based approaches, if designed properly, can be a stronger alternative for jointly modeling temporal and sequential information in user behavior sequences. While vanilla RoPE in LLMs considers only token order, generative recommendation requires incorporating both event time and token index. To address this, we propose Time-and-Order RoPE (TO-RoPE), a family of rotary position embedding designs that treat index and time as angle sources shaping the query-key geometry directly. We present three instantiations: early fusion, split-by-dim, and split-by-head. Extensive experiments on both publicly available datasets and a proprietary industrial dataset show that TO-RoPE variants consistently improve accuracy over existing methods for encoding time and index. These results position rotary embeddings as a simple, principled, and deployment-friendly foundation for generative recommendation.
MATCHA: Can Multi-Agent Collaboration Build a Trustworthy Conversational Recommender?
Apr 26, 2025



In this paper, we propose a multi-agent collaboration framework called MATCHA for conversational recommendation system, leveraging large language models (LLMs) to enhance personalization and user engagement. Users can request recommendations via free-form text and receive curated lists aligned with their interests, preferences, and constraints. Our system introduces specialized agents for intent analysis, candidate generation, ranking, re-ranking, explainability, and safeguards. These agents collaboratively improve recommendations accuracy, diversity, and safety. On eight metrics, our model achieves superior or comparable performance to the current state-of-the-art. Through comparisons with six baseline models, our approach addresses key challenges in conversational recommendation systems for game recommendations, including: (1) handling complex, user-specific requests, (2) enhancing personalization through multi-agent collaboration, (3) empirical evaluation and deployment, and (4) ensuring safe and trustworthy interactions.
OMuleT: Orchestrating Multiple Tools for Practicable Conversational Recommendation
Nov 28, 2024



In this paper, we present a systematic effort to design, evaluate, and implement a realistic conversational recommender system (CRS). The objective of our system is to allow users to input free-form text to request recommendations, and then receive a list of relevant and diverse items. While previous work on synthetic queries augments large language models (LLMs) with 1-3 tools, we argue that a more extensive toolbox is necessary to effectively handle real user requests. As such, we propose a novel approach that equips LLMs with over 10 tools, providing them access to the internal knowledge base and API calls used in production. We evaluate our model on a dataset of real users and show that it generates relevant, novel, and diverse recommendations compared to vanilla LLMs. Furthermore, we conduct ablation studies to demonstrate the effectiveness of using the full range of tools in our toolbox. We share our designs and lessons learned from deploying the system for internal alpha release. Our contribution is the addressing of all four key aspects of a practicable CRS: (1) real user requests, (2) augmenting LLMs with a wide variety of tools, (3) extensive evaluation, and (4) deployment insights.
Greener yet Powerful: Taming Large Code Generation Models with Quantization
Mar 09, 2023
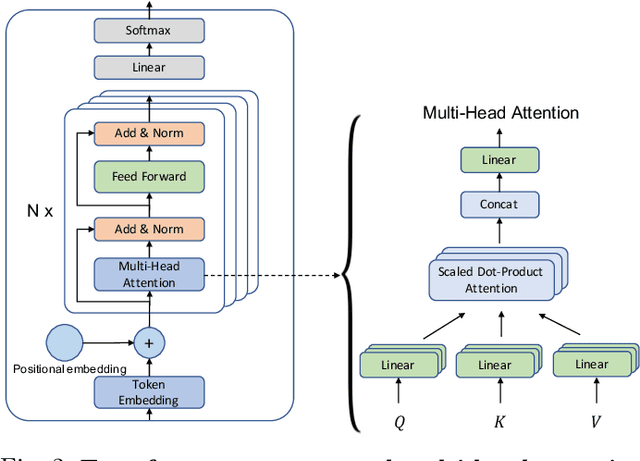
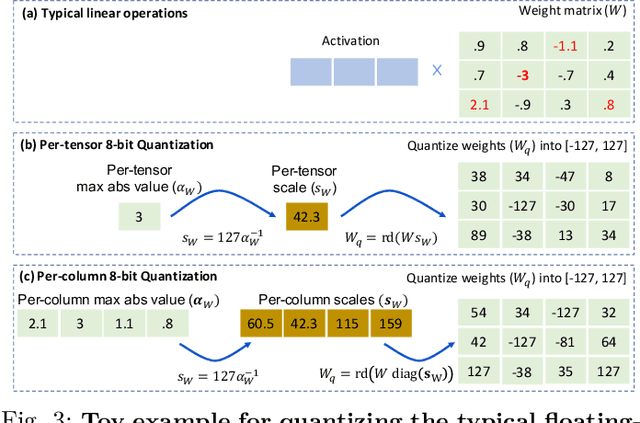
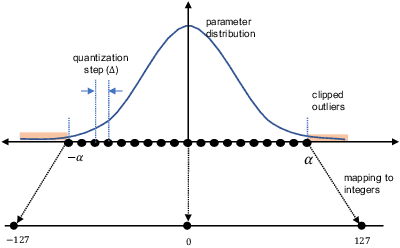
ML-powered code generation aims to assist developers to write code in a more productive manner, by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have substantially pushed the boundary of code generation and achieved impressive performance. Despite their great power, the huge number of model parameters poses a significant threat to adapting them in a regular software development environment, where a developer might use a standard laptop or mid-size server to develop her code. Such large models incur significant resource usage (in terms of memory, latency, and dollars) as well as carbon footprint. Model compression is a promising approach to address these challenges. Several techniques are proposed to compress large pretrained models typically used for vision or textual data. Out of many available compression techniques, we identified that quantization is mostly applicable for code generation task as it does not require significant retraining cost. As quantization represents model parameters with lower-bit integer (e.g., int8), the model size and runtime latency would both benefit from such int representation. We extensively study the impact of quantized model on code generation tasks across different dimension: (i) resource usage and carbon footprint, (ii) accuracy, and (iii) robustness. To this end, through systematic experiments we find a recipe of quantization technique that could run even a $6$B model in a regular laptop without significant accuracy or robustness degradation. We further found the recipe is readily applicable to code summarization task as well.
Debiasing Neural Retrieval via In-batch Balancing Regularization
May 18, 2022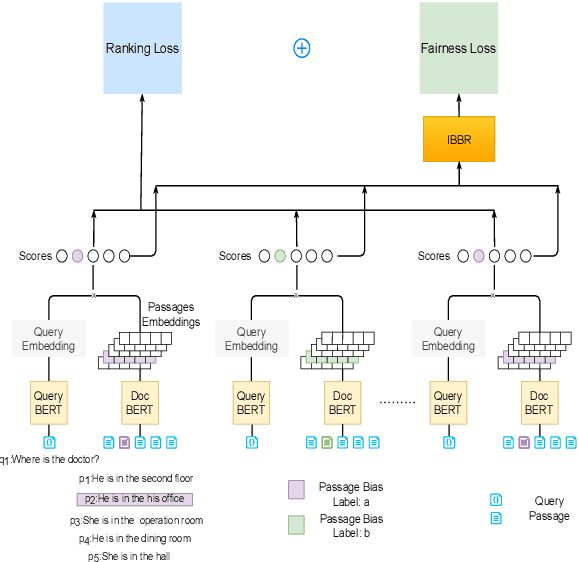
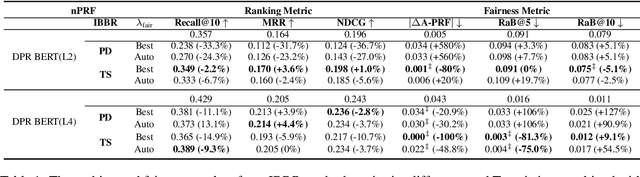
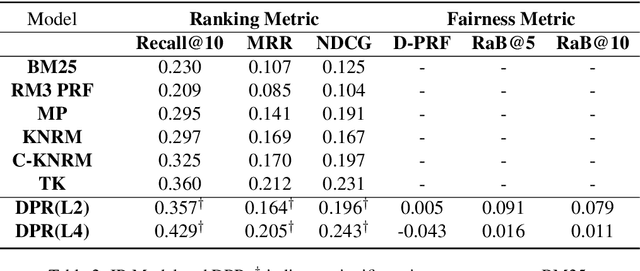
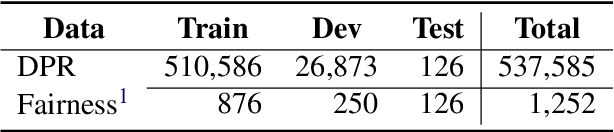
People frequently interact with information retrieval (IR) systems, however, IR models exhibit biases and discrimination towards various demographics. The in-processing fair ranking methods provide a trade-offs between accuracy and fairness through adding a fairness-related regularization term in the loss function. However, there haven't been intuitive objective functions that depend on the click probability and user engagement to directly optimize towards this. In this work, we propose the In-Batch Balancing Regularization (IBBR) to mitigate the ranking disparity among subgroups. In particular, we develop a differentiable \textit{normed Pairwise Ranking Fairness} (nPRF) and leverage the T-statistics on top of nPRF over subgroups as a regularization to improve fairness. Empirical results with the BERT-based neural rankers on the MS MARCO Passage Retrieval dataset with the human-annotated non-gendered queries benchmark \citep{rekabsaz2020neural} show that our IBBR method with nPRF achieves significantly less bias with minimal degradation in ranking performance compared with the baseline.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022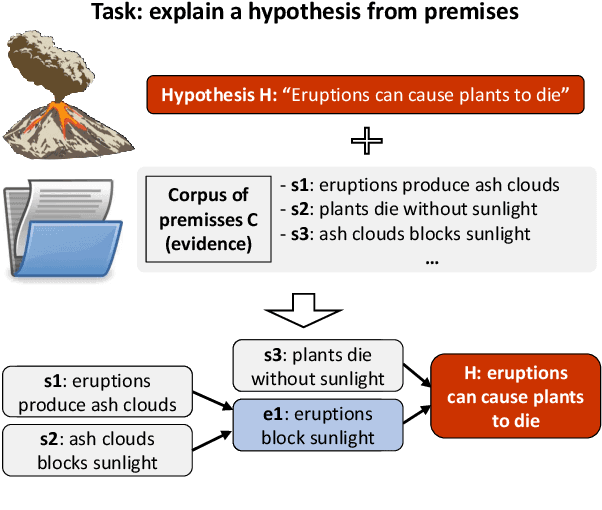
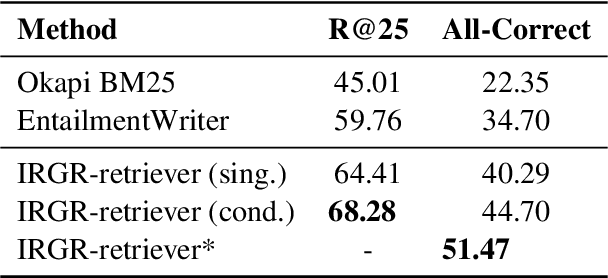
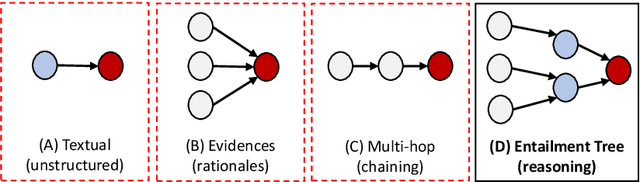
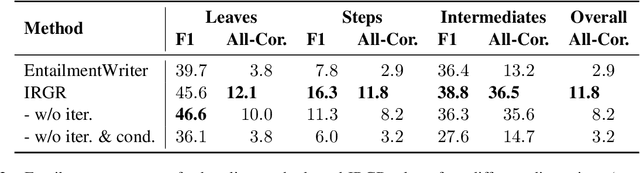
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
Oct 16, 2021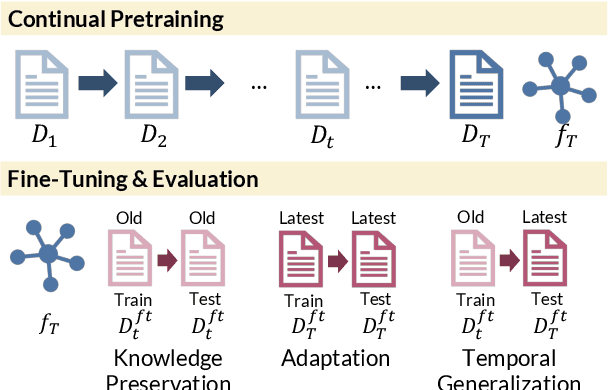
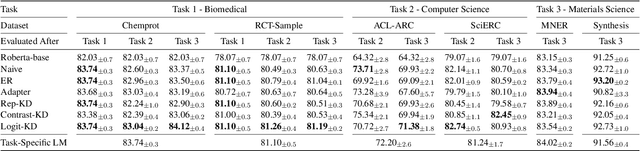
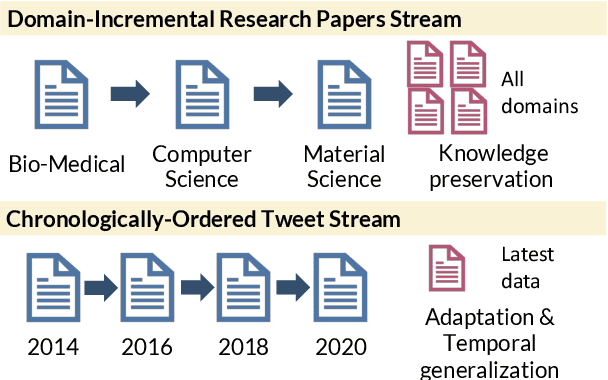
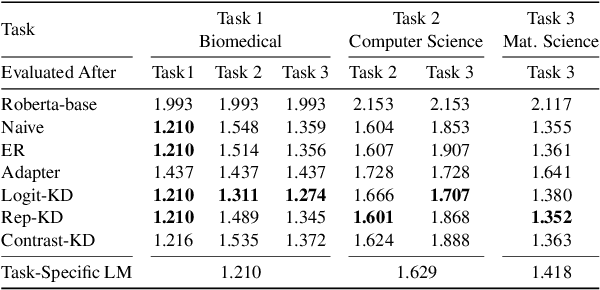
Pretrained language models (PTLMs) are typically learned over a large, static corpus and further fine-tuned for various downstream tasks. However, when deployed in the real world, a PTLM-based model must deal with data from a new domain that deviates from what the PTLM was initially trained on, or newly emerged data that contains out-of-distribution information. In this paper, we study a lifelong language model pretraining challenge where a PTLM is continually updated so as to adapt to emerging data. Over a domain-incremental research paper stream and a chronologically ordered tweet stream, we incrementally pretrain a PTLM with different continual learning algorithms, and keep track of the downstream task performance (after fine-tuning) to analyze its ability of acquiring new knowledge and preserving learned knowledge. Our experiments show continual learning algorithms improve knowledge preservation, with logit distillation being the most effective approach. We further show that continual pretraining improves generalization when training and testing data of downstream tasks are drawn from different time steps, but do not improve when they are from the same time steps. We believe our problem formulation, methods, and analysis will inspire future studies towards continual pretraining of language models.
Knowledge Enhanced Pretrained Language Models: A Compreshensive Survey
Oct 16, 2021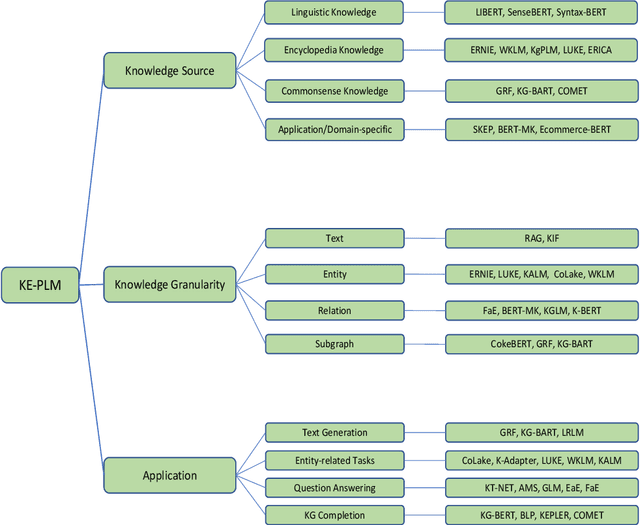

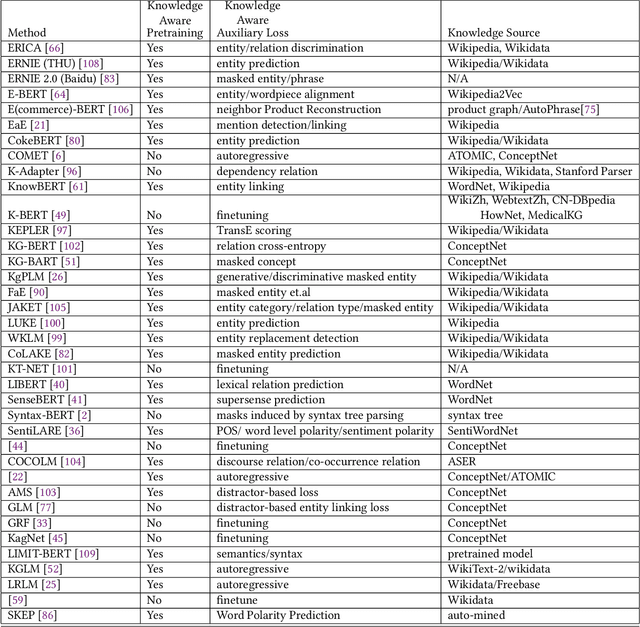
Pretrained Language Models (PLM) have established a new paradigm through learning informative contextualized representations on large-scale text corpus. This new paradigm has revolutionized the entire field of natural language processing, and set the new state-of-the-art performance for a wide variety of NLP tasks. However, though PLMs could store certain knowledge/facts from training corpus, their knowledge awareness is still far from satisfactory. To address this issue, integrating knowledge into PLMs have recently become a very active research area and a variety of approaches have been developed. In this paper, we provide a comprehensive survey of the literature on this emerging and fast-growing field - Knowledge Enhanced Pretrained Language Models (KE-PLMs). We introduce three taxonomies to categorize existing work. Besides, we also survey the various NLU and NLG applications on which KE-PLM has demonstrated superior performance over vanilla PLMs. Finally, we discuss challenges that face KE-PLMs and also promising directions for future research.
Supporting Clustering with Contrastive Learning
Mar 24, 2021
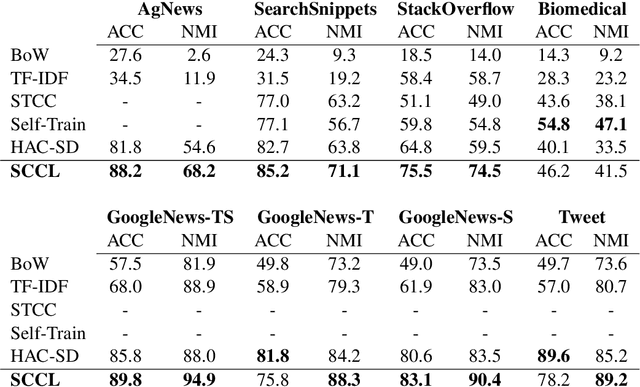
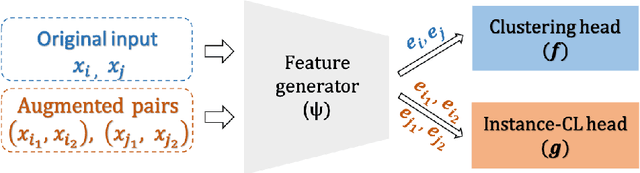
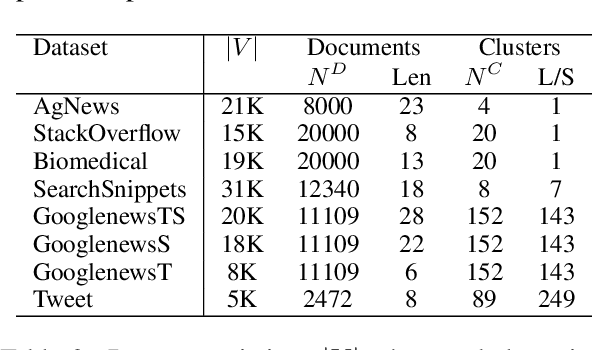
Unsupervised clustering aims at discovering the semantic categories of data according to some distance measured in the representation space. However, different categories often overlap with each other in the representation space at the beginning of the learning process, which poses a significant challenge for distance-based clustering in achieving good separation between different categories. To this end, we propose Supporting Clustering with Contrastive Learning (SCCL) -- a novel framework to leverage contrastive learning to promote better separation. We assess the performance of SCCL on short text clustering and show that SCCL significantly advances the state-of-the-art results on most benchmark datasets with 3%-11% improvement on Accuracy and 4%-15% improvement on Normalized Mutual Information. Furthermore, our quantitative analysis demonstrates the effectiveness of SCCL in leveraging the strengths of both bottom-up instance discrimination and top-down clustering to achieve better intra-cluster and inter-cluster distances when evaluated with the ground truth cluster labels