 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Deep Learning to LLMs: A survey of AI in Quantitative Investment
Mar 27, 2025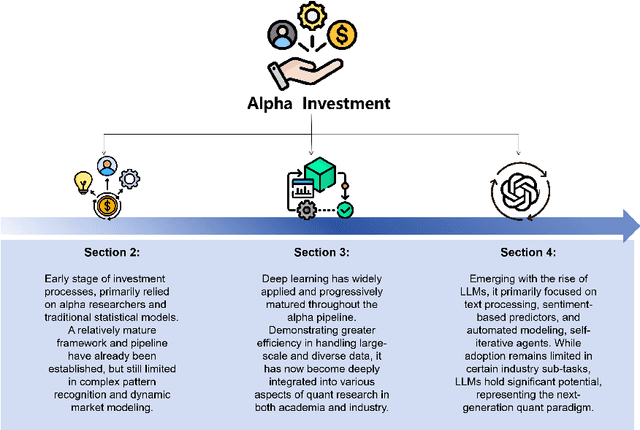
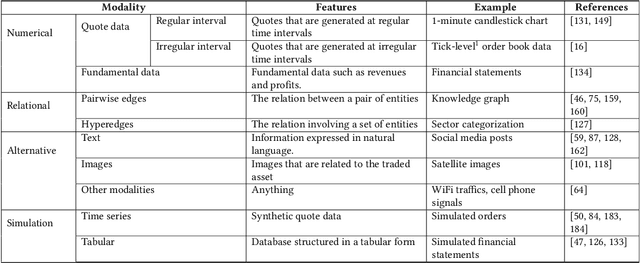
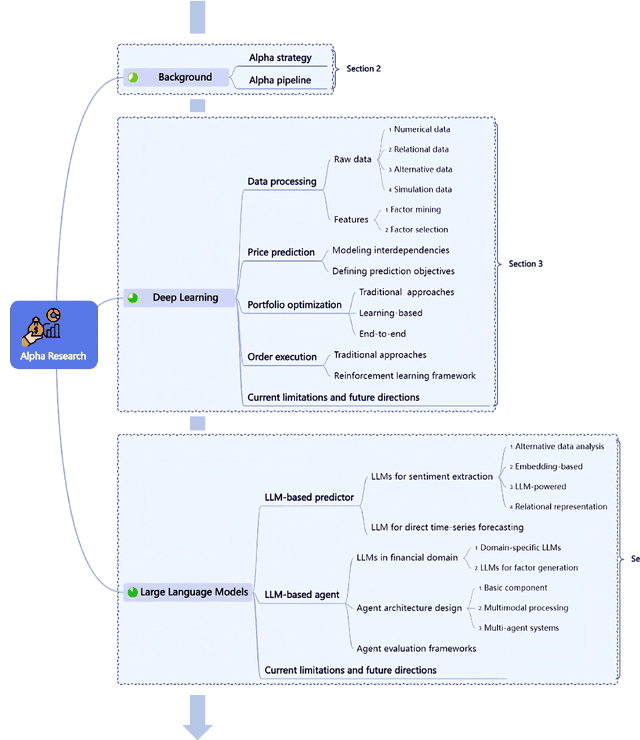
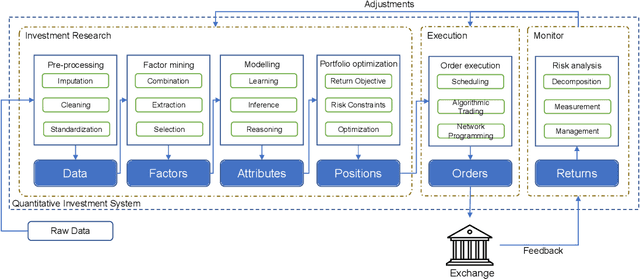
Quantitative investment (quant) is an emerging, technology-driven approach in asset management, increasingy shaped by advancements in artificial intelligence. Recent advances in deep learning and large language models (LLMs) for quant finance have improved predictive modeling and enabled agent-based automation, suggesting a potential paradigm shift in this field. In this survey, taking alpha strategy as a representative example, we explore how AI contributes to the quantitative investment pipeline. We first examine the early stage of quant research, centered on human-crafted features and traditional statistical models with an established alpha pipeline. We then discuss the rise of deep learning, which enabled scalable modeling across the entire pipeline from data processing to order execution. Building on this, we highlight the emerging role of LLMs in extending AI beyond prediction, empowering autonomous agents to process unstructured data, generate alphas, and support self-iterative workflows.
Private Model Compression via Knowledge Distillation
Nov 13, 2018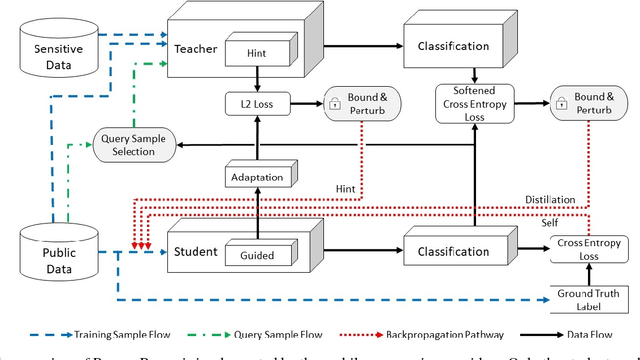
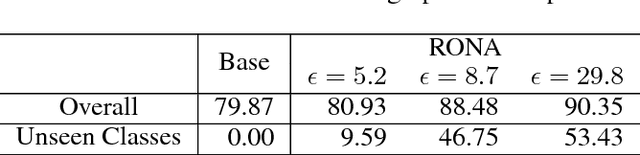
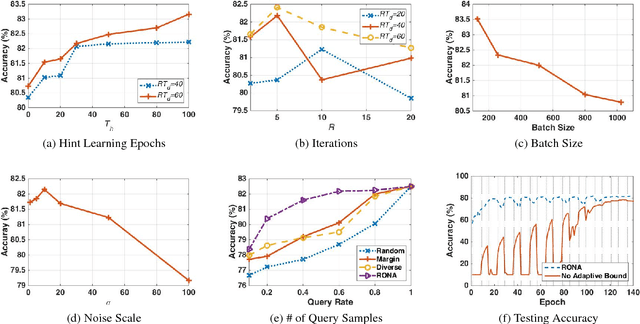
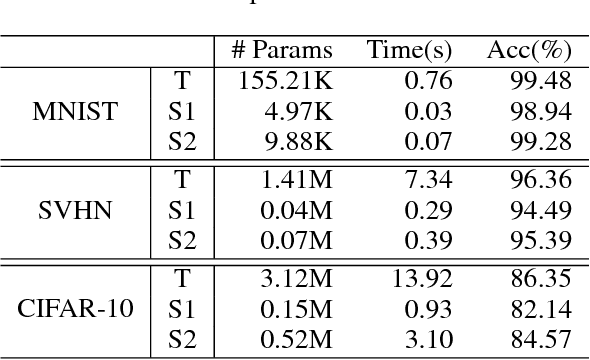
The soaring demand for intelligent mobile applications calls for deploying powerful deep neural networks (DNNs) on mobile devices. However, the outstanding performance of DNNs notoriously relies on increasingly complex models, which in turn is associated with an increase in computational expense far surpassing mobile devices' capacity. What is worse, app service providers need to collect and utilize a large volume of users' data, which contain sensitive information, to build the sophisticated DNN models. Directly deploying these models on public mobile devices presents prohibitive privacy risk. To benefit from the on-device deep learning without the capacity and privacy concerns, we design a private model compression framework RONA. Following the knowledge distillation paradigm, we jointly use hint learning, distillation learning, and self learning to train a compact and fast neural network. The knowledge distilled from the cumbersome model is adaptively bounded and carefully perturbed to enforce differential privacy. We further propose an elegant query sample selection method to reduce the number of queries and control the privacy loss. A series of empirical evaluations as well as the implementation on an Android mobile device show that RONA can not only compress cumbersome models efficiently but also provide a strong privacy guarantee. For example, on SVHN, when a meaningful $(9.83,10^{-6})$-differential privacy is guaranteed, the compact model trained by RONA can obtain 20$\times$ compression ratio and 19$\times$ speed-up with merely 0.97% accuracy loss.
Not Just Privacy: Improving Performance of Private Deep Learning in Mobile Cloud
Sep 19, 2018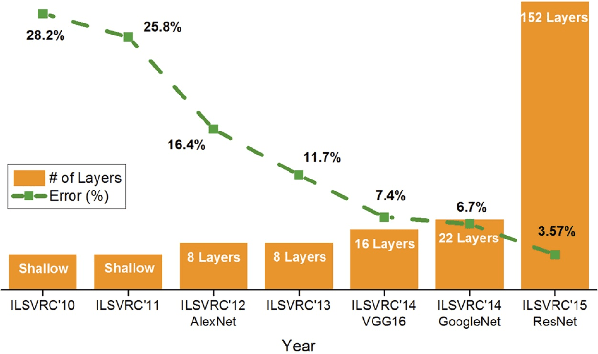
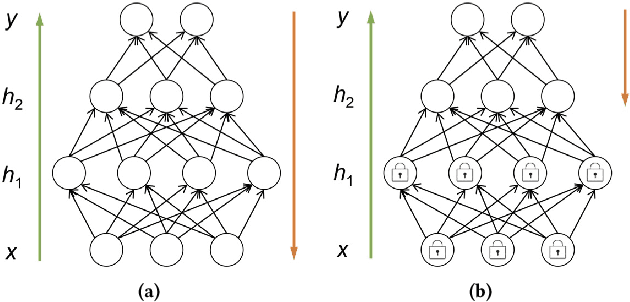
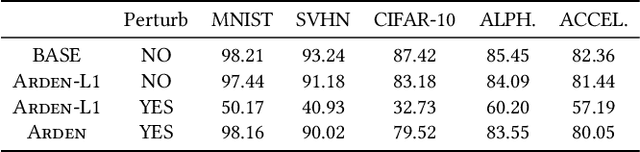
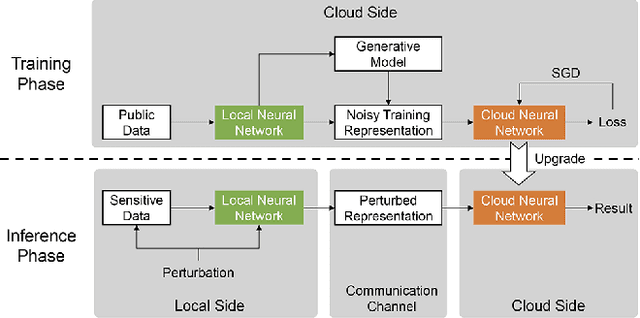
The increasing demand for on-device deep learning services calls for a highly efficient manner to deploy deep neural networks (DNNs) on mobile devices with limited capacity. The cloud-based solution is a promising approach to enabling deep learning applications on mobile devices where the large portions of a DNN are offloaded to the cloud. However, revealing data to the cloud leads to potential privacy risk. To benefit from the cloud data center without the privacy risk, we design, evaluate, and implement a cloud-based framework ARDEN which partitions the DNN across mobile devices and cloud data centers. A simple data transformation is performed on the mobile device, while the resource-hungry training and the complex inference rely on the cloud data center. To protect the sensitive information, a lightweight privacy-preserving mechanism consisting of arbitrary data nullification and random noise addition is introduced, which provides strong privacy guarantee. A rigorous privacy budget analysis is given. Nonetheless, the private perturbation to the original data inevitably has a negative impact on the performance of further inference on the cloud side. To mitigate this influence, we propose a noisy training method to enhance the cloud-side network robustness to perturbed data. Through the sophisticated design, ARDEN can not only preserve privacy but also improve the inference performance. To validate the proposed ARDEN, a series of experiments based on three image datasets and a real mobile application are conducted. The experimental results demonstrate the effectiveness of ARDEN. Finally, we implement ARDEN on a demo system to verify its practicality.
Joint Embedding of Meta-Path and Meta-Graph for Heterogeneous Information Networks
Sep 11, 2018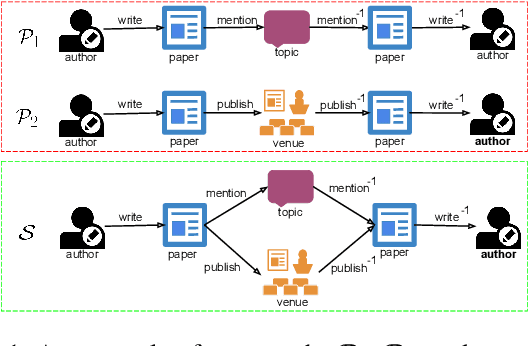
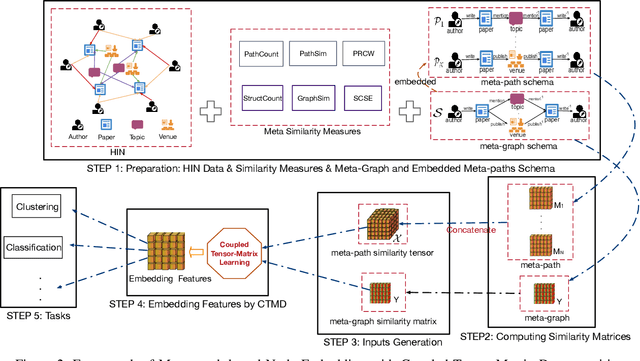

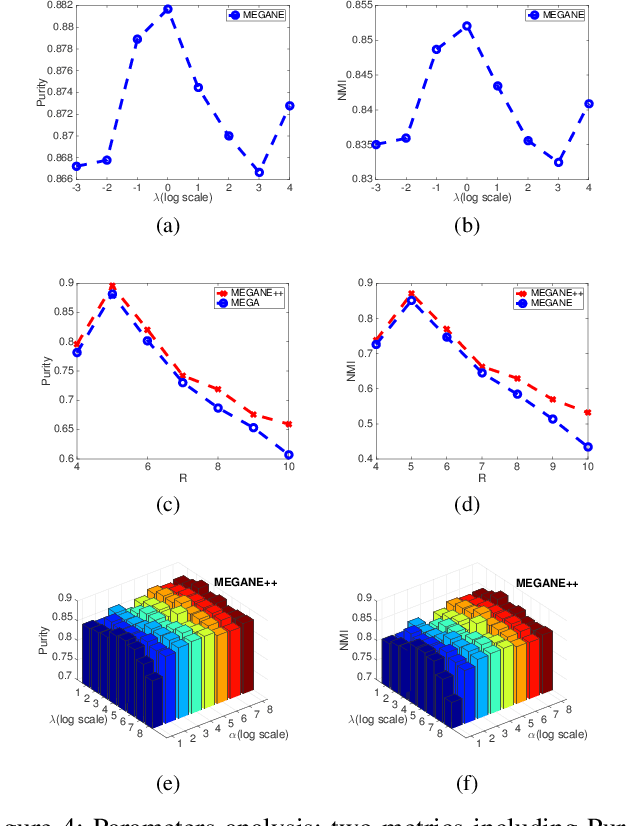
Meta-graph is currently the most powerful tool for similarity search on heterogeneous information networks,where a meta-graph is a composition of meta-paths that captures the complex structural information. However, current relevance computing based on meta-graph only considers the complex structural information, but ignores its embedded meta-paths information. To address this problem, we proposeMEta-GrAph-based network embedding models, called MEGA and MEGA++, respectively. The MEGA model uses normalized relevance or similarity measures that are derived from a meta-graph and its embedded meta-paths between nodes simultaneously, and then leverages tensor decomposition method to perform node embedding. The MEGA++ further facilitates the use of coupled tensor-matrix decomposition method to obtain a joint embedding for nodes, which simultaneously considers the hidden relations of all meta information of a meta-graph.Extensive experiments on two real datasets demonstrate thatMEGA and MEGA++ are more effective than state-of-the-art approaches.
Deep Learning Towards Mobile Applications
Sep 10, 2018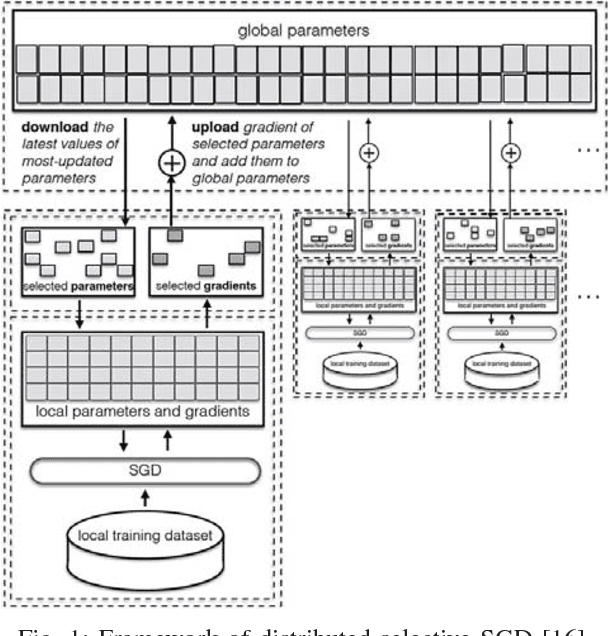
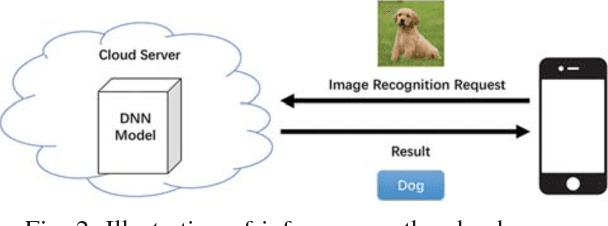
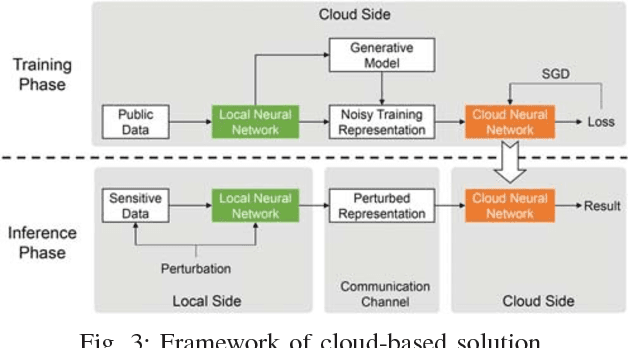
Recent years have witnessed an explosive growth of mobile devices. Mobile devices are permeating every aspect of our daily lives. With the increasing usage of mobile devices and intelligent applications, there is a soaring demand for mobile applications with machine learning services. Inspired by the tremendous success achieved by deep learning in many machine learning tasks, it becomes a natural trend to push deep learning towards mobile applications. However, there exist many challenges to realize deep learning in mobile applications, including the contradiction between the miniature nature of mobile devices and the resource requirement of deep neural networks, the privacy and security concerns about individuals' data, and so on. To resolve these challenges, during the past few years, great leaps have been made in this area. In this paper, we provide an overview of the current challenges and representative achievements about pushing deep learning on mobile devices from three aspects: training with mobile data, efficient inference on mobile devices, and applications of mobile deep learning. The former two aspects cover the primary tasks of deep learning. Then, we go through our two recent applications that apply the data collected by mobile devices to inferring mood disturbance and user identification. Finally, we conclude this paper with the discussion of the future of this area.
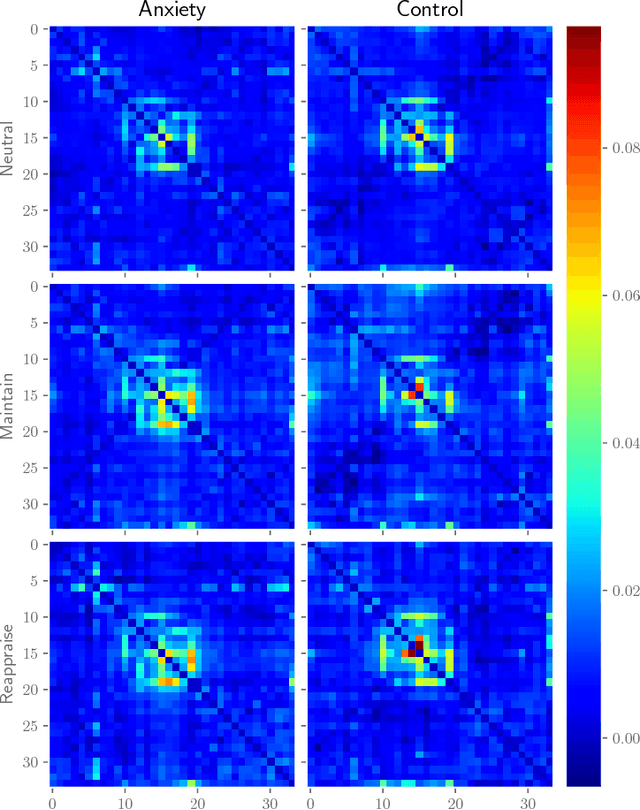
Multi-View Multi-Graph Embedding for Brain Network Clustering Analysis
Jun 19, 2018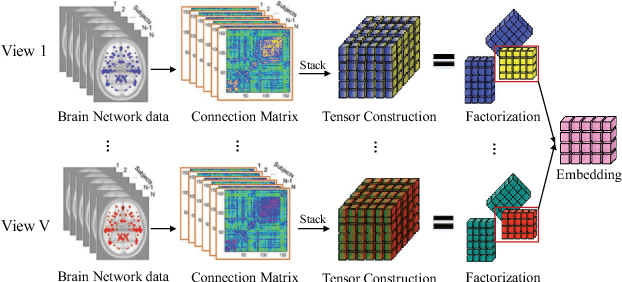

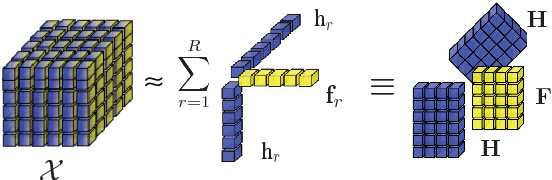
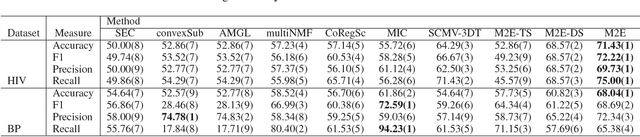
Network analysis of human brain connectivity is critically important for understanding brain function and disease states. Embedding a brain network as a whole graph instance into a meaningful low-dimensional representation can be used to investigate disease mechanisms and inform therapeutic interventions. Moreover, by exploiting information from multiple neuroimaging modalities or views, we are able to obtain an embedding that is more useful than the embedding learned from an individual view. Therefore, multi-view multi-graph embedding becomes a crucial task. Currently, only a few studies have been devoted to this topic, and most of them focus on the vector-based strategy which will cause structural information contained in the original graphs lost. As a novel attempt to tackle this problem, we propose Multi-view Multi-graph Embedding (M2E) by stacking multi-graphs into multiple partially-symmetric tensors and using tensor techniques to simultaneously leverage the dependencies and correlations among multi-view and multi-graph brain networks. Extensive experiments on real HIV and bipolar disorder brain network datasets demonstrate the superior performance of M2E on clustering brain networks by leveraging the multi-view multi-graph interactions.
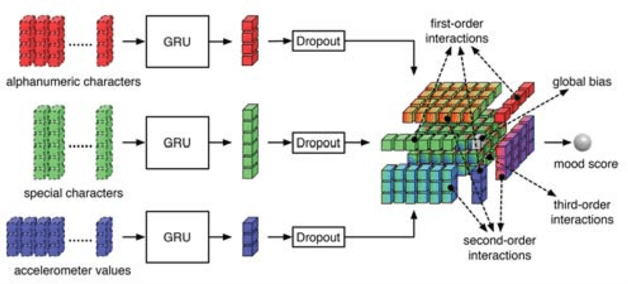
DeepMood: Modeling Mobile Phone Typing Dynamics for Mood Detection
Mar 23, 2018
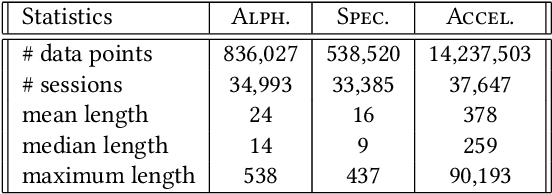
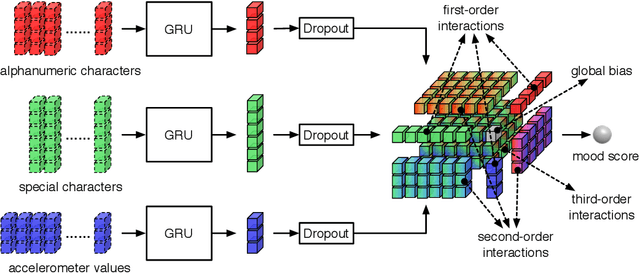
The increasing use of electronic forms of communication presents new opportunities in the study of mental health, including the ability to investigate the manifestations of psychiatric diseases unobtrusively and in the setting of patients' daily lives. A pilot study to explore the possible connections between bipolar affective disorder and mobile phone usage was conducted. In this study, participants were provided a mobile phone to use as their primary phone. This phone was loaded with a custom keyboard that collected metadata consisting of keypress entry time and accelerometer movement. Individual character data with the exceptions of the backspace key and space bar were not collected due to privacy concerns. We propose an end-to-end deep architecture based on late fusion, named DeepMood, to model the multi-view metadata for the prediction of mood scores. Experimental results show that 90.31% prediction accuracy on the depression score can be achieved based on session-level mobile phone typing dynamics which is typically less than one minute. It demonstrates the feasibility of using mobile phone metadata to infer mood disturbance and severity.
Multi-View Factorization Machines
Mar 23, 2018
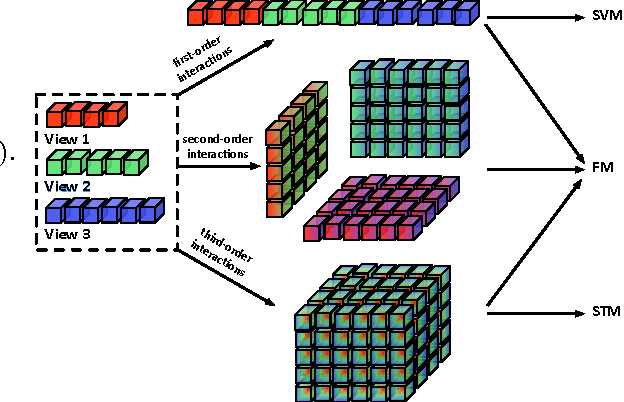


For a learning task, data can usually be collected from different sources or be represented from multiple views. For example, laboratory results from different medical examinations are available for disease diagnosis, and each of them can only reflect the health state of a person from a particular aspect/view. Therefore, different views provide complementary information for learning tasks. An effective integration of the multi-view information is expected to facilitate the learning performance. In this paper, we propose a general predictor, named multi-view machines (MVMs), that can effectively include all the possible interactions between features from multiple views. A joint factorization is embedded for the full-order interaction parameters which allows parameter estimation under sparsity. Moreover, MVMs can work in conjunction with different loss functions for a variety of machine learning tasks. A stochastic gradient descent method is presented to learn the MVM model. We further illustrate the advantages of MVMs through comparison with other methods for multi-view classification, including support vector machines (SVMs), support tensor machines (STMs) and factorization machines (FMs).
Broad Learning for Healthcare
Mar 23, 2018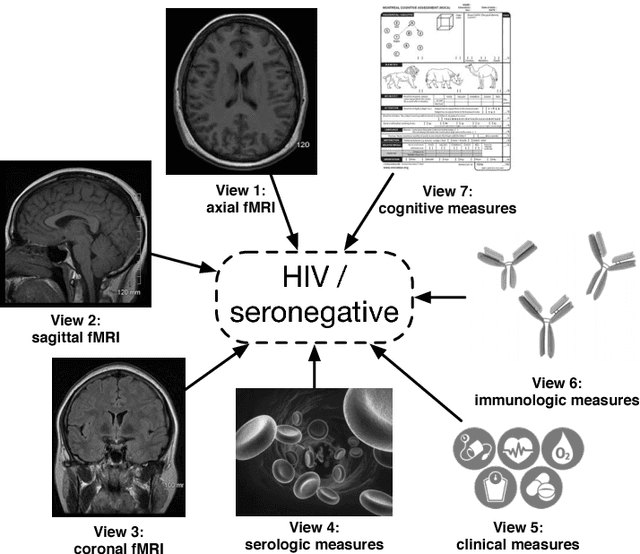
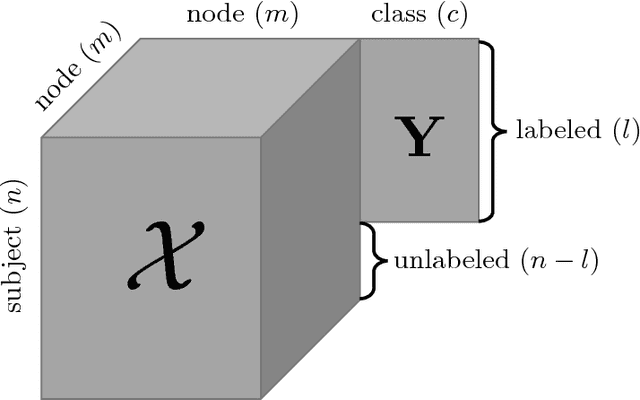
A broad spectrum of data from different modalities are generated in the healthcare domain every day, including scalar data (e.g., clinical measures collected at hospitals), tensor data (e.g., neuroimages analyzed by research institutes), graph data (e.g., brain connectivity networks), and sequence data (e.g., digital footprints recorded on smart sensors). Capability for modeling information from these heterogeneous data sources is potentially transformative for investigating disease mechanisms and for informing therapeutic interventions. Our works in this thesis attempt to facilitate healthcare applications in the setting of broad learning which focuses on fusing heterogeneous data sources for a variety of synergistic knowledge discovery and machine learning tasks. We are generally interested in computer-aided diagnosis, precision medicine, and mobile health by creating accurate user profiles which include important biomarkers, brain connectivity patterns, and latent representations. In particular, our works involve four different data mining problems with application to the healthcare domain: multi-view feature selection, subgraph pattern mining, brain network embedding, and multi-view sequence prediction.
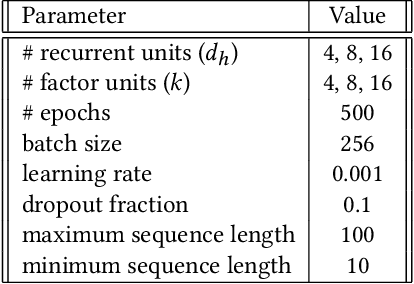
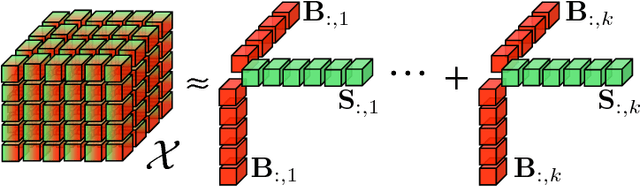
Learning from Multi-View Multi-Way Data via Structural Factorization Machines
Feb 15, 2018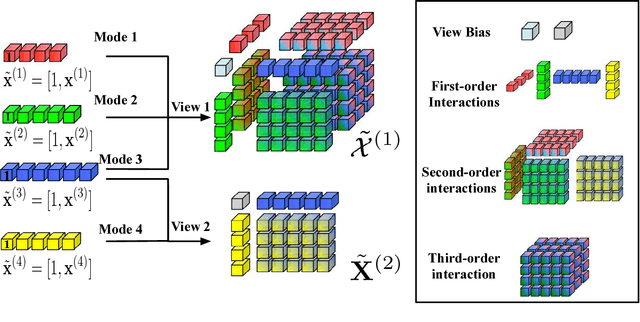

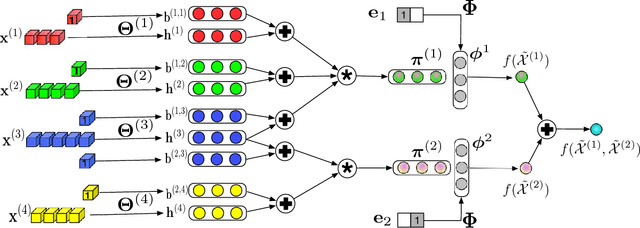
Real-world relations among entities can often be observed and determined by different perspectives/views. For example, the decision made by a user on whether to adopt an item relies on multiple aspects such as the contextual information of the decision, the item's attributes, the user's profile and the reviews given by other users. Different views may exhibit multi-way interactions among entities and provide complementary information. In this paper, we introduce a multi-tensor-based approach that can preserve the underlying structure of multi-view data in a generic predictive model. Specifically, we propose structural factorization machines (SFMs) that learn the common latent spaces shared by multi-view tensors and automatically adjust the importance of each view in the predictive model. Furthermore, the complexity of SFMs is linear in the number of parameters, which make SFMs suitable to large-scale problems. Extensive experiments on real-world datasets demonstrate that the proposed SFMs outperform several state-of-the-art methods in terms of prediction accuracy and computational cost.