 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Aware Evolution of Heuristic Programs from Learned Optimization Policies
May 11, 2026LLM-based automatic heuristic design has shown promise for generating executable heuristics for combinatorial optimization, but existing methods mainly rely on delayed endpoint performance. We propose a \emph{teacher-aware evolutionary framework} that uses independently trained learned optimization policies as behavioral teachers. Instead of deploying or imitating the teacher, our method queries it on states visited by candidate heuristic programs and uses its action preferences as local feedback for evolution. The resulting search discovers static executable heuristics guided by both task performance and teacher-derived behavioral signals. Experiments on scheduling, routing, and graph optimization benchmarks show that our method improves over performance-driven LLM heuristic evolution baselines while requiring no neural inference at deployment. These results suggest that learned optimization policies can be repurposed as behavioral feedback sources for automatic heuristic discovery.
SimCert: Probabilistic Certification for Behavioral Similarity in Deep Neural Network Compression
Mar 16, 2026Deploying Deep Neural Networks (DNNs) on resource-constrained embedded systems requires aggressive model compression techniques like quantization and pruning. However, ensuring that the compressed model preserves the behavioral fidelity of the original design is a critical challenge in the safety-critical system design flow. Existing verification methods often lack scalability or fail to handle the architectural heterogeneity introduced by pruning. In this work, we propose SimCert, a probabilistic certification framework for verifying the behavioral similarity of compressed neural networks. Unlike worst-case analysis, SimCert provides quantitative safety guarantees with adjustable confidence levels. Our framework features: (1) A dual-network symbolic propagation method supporting both quantization and pruning; (2) A variance-aware bounding technique using Bernstein's inequality to tighten safety certificates; and (3) An automated verification toolchain. Experimental results on ACAS Xu and computer vision benchmarks demonstrate that SimCert outperforms state-of-the-art baselines.
OT-Drive: Out-of-Distribution Off-Road Traversable Area Segmentation via Optimal Transport
Jan 15, 2026Reliable traversable area segmentation in unstructured environments is critical for planning and decision-making in autonomous driving. However, existing data-driven approaches often suffer from degraded segmentation performance in out-of-distribution (OOD) scenarios, consequently impairing downstream driving tasks. To address this issue, we propose OT-Drive, an Optimal Transport--driven multi-modal fusion framework. The proposed method formulates RGB and surface normal fusion as a distribution transport problem. Specifically, we design a novel Scene Anchor Generator (SAG) to decompose scene information into the joint distribution of weather, time-of-day, and road type, thereby constructing semantic anchors that can generalize to unseen scenarios. Subsequently, we design an innovative Optimal Transport-based multi-modal fusion module (OT Fusion) to transport RGB and surface normal features onto the manifold defined by the semantic anchors, enabling robust traversable area segmentation under OOD scenarios. Experimental results demonstrate that our method achieves 95.16% mIoU on ORFD OOD scenarios, outperforming prior methods by 6.35%, and 89.79% mIoU on cross-dataset transfer tasks, surpassing baselines by 13.99%.These results indicate that the proposed model can attain strong OOD generalization with only limited training data, substantially enhancing its practicality and efficiency for real-world deployment.
DaSAThco: Data-Aware SAT Heuristics Combinations Optimization via Large Language Models
Sep 16, 2025The performance of Conflict-Driven Clause Learning solvers hinges on internal heuristics, yet the heterogeneity of SAT problems makes a single, universally optimal configuration unattainable. While prior automated methods can find specialized configurations for specific problem families, this dataset-specific approach lacks generalizability and requires costly re-optimization for new problem types. We introduce DaSAThco, a framework that addresses this challenge by learning a generalizable mapping from instance features to tailored heuristic ensembles, enabling a train-once, adapt-broadly model. Our framework uses a Large Language Model, guided by systematically defined Problem Archetypes, to generate a diverse portfolio of specialized heuristic ensembles and subsequently learns an adaptive selection mechanism to form the final mapping. Experiments show that DaSAThco achieves superior performance and, most notably, demonstrates robust out-of-domain generalization where non-adaptive methods show limitations. Our work establishes a more scalable and practical path toward automated algorithm design for complex, configurable systems.
Large Language Model guided Deep Reinforcement Learning for Decision Making in Autonomous Driving
Dec 24, 2024Deep reinforcement learning (DRL) shows promising potential for autonomous driving decision-making. However, DRL demands extensive computational resources to achieve a qualified policy in complex driving scenarios due to its low learning efficiency. Moreover, leveraging expert guidance from human to enhance DRL performance incurs prohibitively high labor costs, which limits its practical application. In this study, we propose a novel large language model (LLM) guided deep reinforcement learning (LGDRL) framework for addressing the decision-making problem of autonomous vehicles. Within this framework, an LLM-based driving expert is integrated into the DRL to provide intelligent guidance for the learning process of DRL. Subsequently, in order to efficiently utilize the guidance of the LLM expert to enhance the performance of DRL decision-making policies, the learning and interaction process of DRL is enhanced through an innovative expert policy constrained algorithm and a novel LLM-intervened interaction mechanism. Experimental results demonstrate that our method not only achieves superior driving performance with a 90\% task success rate but also significantly improves the learning efficiency and expert guidance utilization efficiency compared to state-of-the-art baseline algorithms. Moreover, the proposed method enables the DRL agent to maintain consistent and reliable performance in the absence of LLM expert guidance. The code and supplementary videos are available at https://bitmobility.github.io/LGDRL/.
Enhancing Automated Loop Invariant Generation for Complex Programs with Large Language Models
Dec 13, 2024



Automated program verification has always been an important component of building trustworthy software. While the analysis of real-world programs remains a theoretical challenge, the automation of loop invariant analysis has effectively resolved the problem. However, real-world programs that often mix complex data structures and control flows pose challenges to traditional loop invariant generation tools. To enhance the applicability of invariant generation techniques, we proposed ACInv, an Automated Complex program loop Invariant generation tool, which combines static analysis with Large Language Models (LLMs) to generate the proper loop invariants. We utilize static analysis to extract the necessary information for each loop and embed it into prompts for the LLM to generate invariants for each loop. Subsequently, we employ an LLM-based evaluator to assess the generated invariants, refining them by either strengthening, weakening, or rejecting them based on their correctness, ultimately obtaining enhanced invariants. We conducted experiments on ACInv, which showed that ACInv outperformed previous tools on data sets with data structures, and maintained similar performance to the state-of-the-art tool AutoSpec on numerical programs without data structures. For the total data set, ACInv can solve 21% more examples than AutoSpec and can generate reference data structure templates.
Can Language Models Pretend Solvers? Logic Code Simulation with LLMs
Mar 28, 2024



Transformer-based large language models (LLMs) have demonstrated significant potential in addressing logic problems. capitalizing on the great capabilities of LLMs for code-related activities, several frameworks leveraging logical solvers for logic reasoning have been proposed recently. While existing research predominantly focuses on viewing LLMs as natural language logic solvers or translators, their roles as logic code interpreters and executors have received limited attention. This study delves into a novel aspect, namely logic code simulation, which forces LLMs to emulate logical solvers in predicting the results of logical programs. To further investigate this novel task, we formulate our three research questions: Can LLMs efficiently simulate the outputs of logic codes? What strength arises along with logic code simulation? And what pitfalls? To address these inquiries, we curate three novel datasets tailored for the logic code simulation task and undertake thorough experiments to establish the baseline performance of LLMs in code simulation. Subsequently, we introduce a pioneering LLM-based code simulation technique, Dual Chains of Logic (DCoL). This technique advocates a dual-path thinking approach for LLMs, which has demonstrated state-of-the-art performance compared to other LLM prompt strategies, achieving a notable improvement in accuracy by 7.06% with GPT-4-Turbo.
AC4: Algebraic Computation Checker for Circuit Constraints in ZKPs
Mar 23, 2024ZKP systems have surged attention and held a fundamental role in contemporary cryptography. Zk-SNARK protocols dominate the ZKP usage, often implemented through arithmetic circuit programming paradigm. However, underconstrained or overconstrained circuits may lead to bugs. Underconstrained circuits refer to circuits that lack the necessary constraints, resulting in unexpected solutions in the circuit and causing the verifier to accept a bogus witness. Overconstrained circuits refer to circuits that are constrained excessively, resulting in the circuit lacking necessary solutions and causing the verifier to accept no witness, rendering the circuit meaningless. This paper introduces a novel approach for pinpointing two distinct types of bugs in ZKP circuits. The method involves encoding the arithmetic circuit constraints to polynomial equation systems and solving polynomial equation systems over a finite field by algebraic computation. The classification of verification results is refined, greatly enhancing the expressive power of the system. We proposed a tool, AC4, to represent the implementation of this method. Experiments demonstrate that AC4 represents a substantial 29% increase in the checked ratio compared to prior work. Within a solvable range, the checking time of AC4 has also exhibited noticeable improvement, demonstrating a magnitude increase compared to previous efforts.
GPS Attack Detection and Mitigation for Safe Autonomous Driving using Image and Map based Lateral Direction Localization
Oct 09, 2023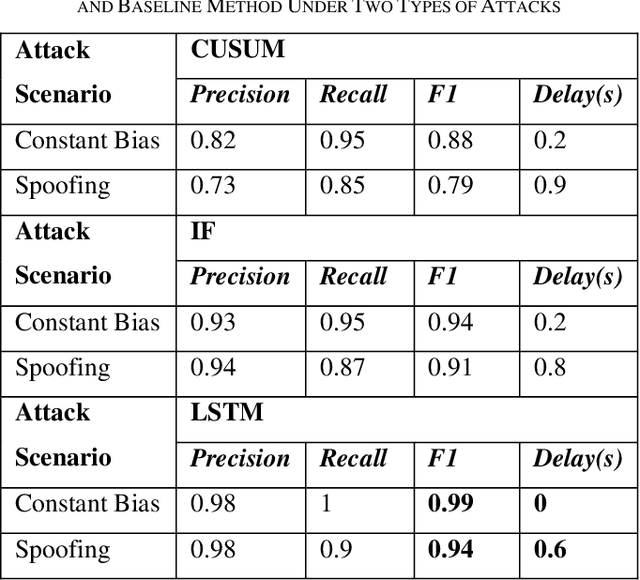
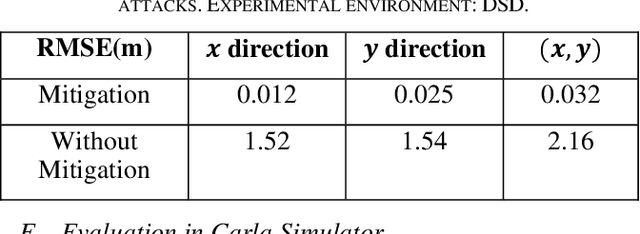
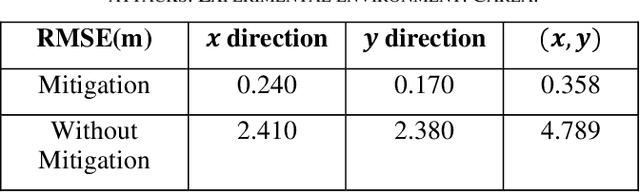
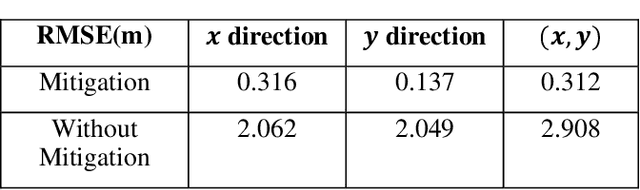
The accuracy and robustness of vehicle localization are critical for achieving safe and reliable high-level autonomy. Recent results show that GPS is vulnerable to spoofing attacks, which is one major threat to autonomous driving. In this paper, a novel anomaly detection and mitigation method against GPS attacks that utilizes onboard camera and high-precision maps is proposed to ensure accurate vehicle localization. First, lateral direction localization in driving lanes is calculated by camera-based lane detection and map matching respectively. Then, a real-time detector for GPS spoofing attack is developed to evaluate the localization data. When the attack is detected, a multi-source fusion-based localization method using Unscented Kalman filter is derived to mitigate GPS attack and improve the localization accuracy. The proposed method is validated in various scenarios in Carla simulator and open-source public dataset to demonstrate its effectiveness in timely GPS attack detection and data recovery.
Differential Newborn Face Morphing Attack Detection using Wavelet Scatter Network
May 02, 2023



Face Recognition System (FRS) are shown to be vulnerable to morphed images of newborns. Detecting morphing attacks stemming from face images of newborn is important to avoid unwanted consequences, both for security and society. In this paper, we present a new reference-based/Differential Morphing Attack Detection (MAD) method to detect newborn morphing images using Wavelet Scattering Network (WSN). We propose a two-layer WSN with 250 $\times$ 250 pixels and six rotations of wavelets per layer, resulting in 577 paths. The proposed approach is validated on a dataset of 852 bona fide images and 2460 morphing images constructed using face images of 42 unique newborns. The obtained results indicate a gain of over 10\% in detection accuracy over other existing D-MAD techniques.