 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARIA: A Framework for Marginal Risk Assessment without Ground Truth in AI Systems
Oct 31, 2025Before deploying an AI system to replace an existing process, it must be compared with the incumbent to ensure improvement without added risk. Traditional evaluation relies on ground truth for both systems, but this is often unavailable due to delayed or unknowable outcomes, high costs, or incomplete data, especially for long-standing systems deemed safe by convention. The more practical solution is not to compute absolute risk but the difference between systems. We therefore propose a marginal risk assessment framework, that avoids dependence on ground truth or absolute risk. It emphasizes three kinds of relative evaluation methodology, including predictability, capability and interaction dominance. By shifting focus from absolute to relative evaluation, our approach equips software teams with actionable guidance: identifying where AI enhances outcomes, where it introduces new risks, and how to adopt such systems responsibly.
FactFlow: Automatic Fact Sheet Generation and Customization from Tabular Dataset via AI Chain Design & Implementation
Feb 25, 2025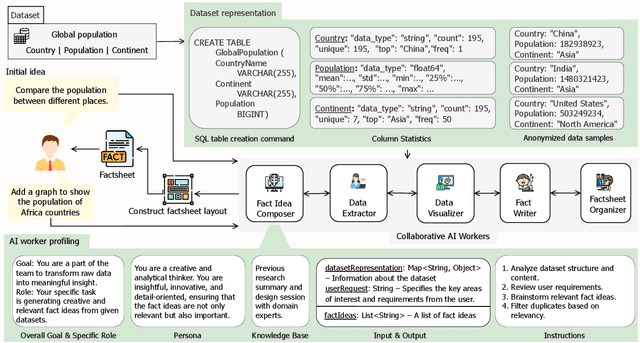
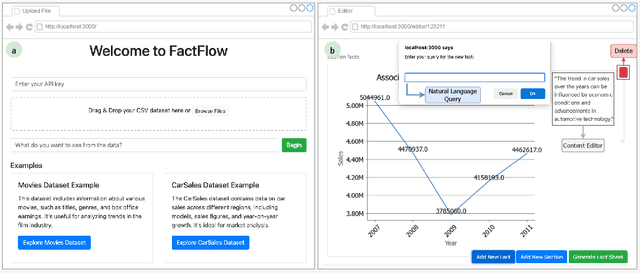
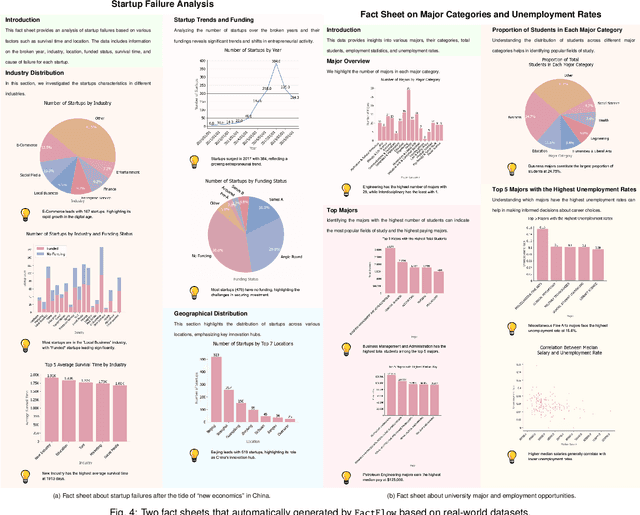
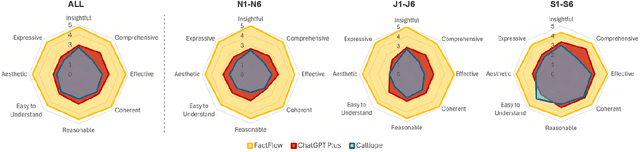
With the proliferation of data across various domains, there is a critical demand for tools that enable non-experts to derive meaningful insights without deep data analysis skills. To address this need, existing automatic fact sheet generation tools offer heuristic-based solutions to extract facts and generate stories. However, they inadequately grasp the semantics of data and struggle to generate narratives that fully capture the semantics of the dataset or align the fact sheet with specific user needs. Addressing these shortcomings, this paper introduces \tool, a novel tool designed for the automatic generation and customisation of fact sheets. \tool applies the concept of collaborative AI workers to transform raw tabular dataset into comprehensive, visually compelling fact sheets. We define effective taxonomy to profile AI worker for specialised tasks. Furthermore, \tool empowers users to refine these fact sheets through intuitive natural language commands, ensuring the final outputs align closely with individual preferences and requirements. Our user evaluation with 18 participants confirms that \tool not only surpasses state-of-the-art baselines in automated fact sheet production but also provides a positive user experience during customization tasks.
From Exploration to Revelation: Detecting Dark Patterns in Mobile Apps
Nov 27, 2024Mobile apps are essential in daily life, yet they often employ dark patterns, such as visual tricks to highlight certain options or linguistic tactics to nag users into making purchases, to manipulate user behavior. Current research mainly uses manual methods to detect dark patterns, a process that is time-consuming and struggles to keep pace with continually updating and emerging apps. While some studies targeted at automated detection, they are constrained to static patterns and still necessitate manual app exploration. To bridge these gaps, we present AppRay, an innovative system that seamlessly blends task-oriented app exploration with automated dark pattern detection, reducing manual efforts. Our approach consists of two steps: First, we harness the commonsense knowledge of large language models for targeted app exploration, supplemented by traditional random exploration to capture a broader range of UI states. Second, we developed a static and dynamic dark pattern detector powered by a contrastive learning-based multi-label classifier and a rule-based refiner to perform detection. We contributed two datasets, AppRay-Dark and AppRay-Light, with 2,185 unique deceptive patterns (including 149 dynamic instances) across 18 types from 876 UIs and 871 benign UIs. These datasets cover both static and dynamic dark patterns while preserving UI relationships. Experimental results confirm that AppRay can efficiently explore the app and identify a wide range of dark patterns with great performance.
A Taxonomy of Architecture Options for Foundation Model-based Agents: Analysis and Decision Model
Aug 06, 2024
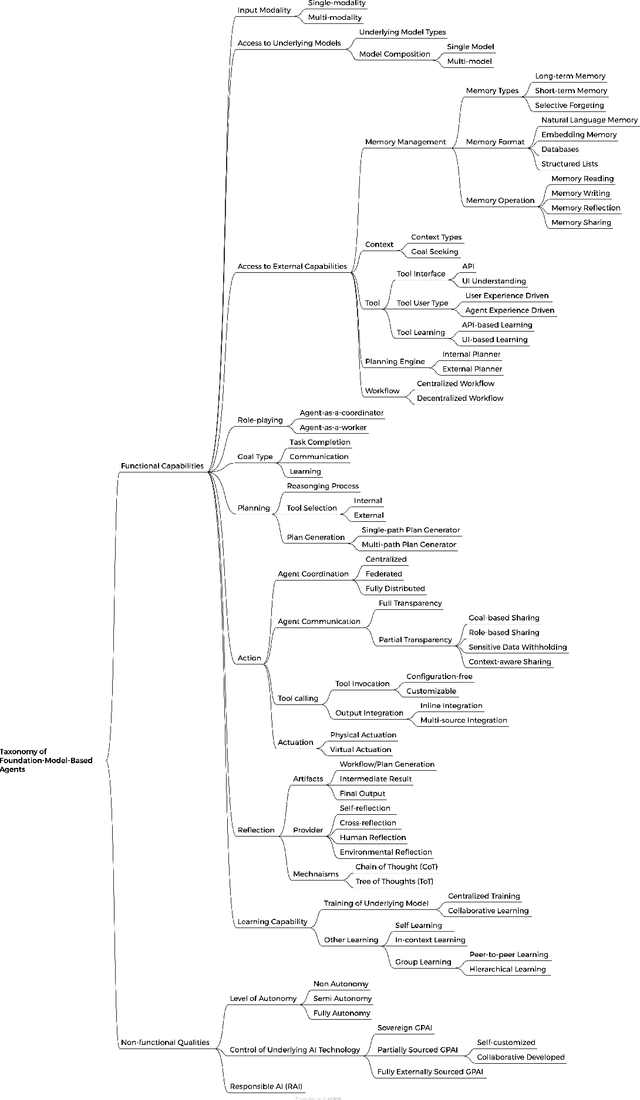
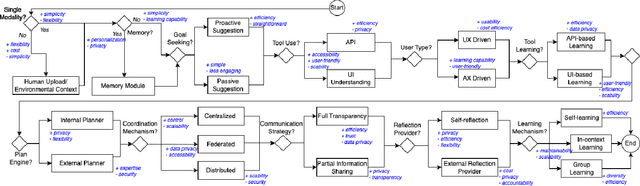
The rapid advancement of AI technology has led to widespread applications of agent systems across various domains. However, the need for detailed architecture design poses significant challenges in designing and operating these systems. This paper introduces a taxonomy focused on the architectures of foundation-model-based agents, addressing critical aspects such as functional capabilities and non-functional qualities. We also discuss the operations involved in both design-time and run-time phases, providing a comprehensive view of architectural design and operational characteristics. By unifying and detailing these classifications, our taxonomy aims to improve the design of foundation-model-based agents. Additionally, the paper establishes a decision model that guides critical design and runtime decisions, offering a structured approach to enhance the development of foundation-model-based agents. Our contributions include providing a structured architecture design option and guiding the development process of foundation-model-based agents, thereby addressing current fragmentation in the field.
Towards Real Smart Apps: Investigating Human-AI Interactions in Smartphone On-Device AI Apps
Jul 03, 2023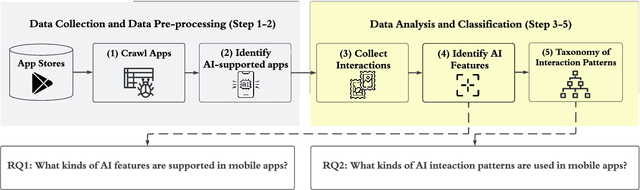
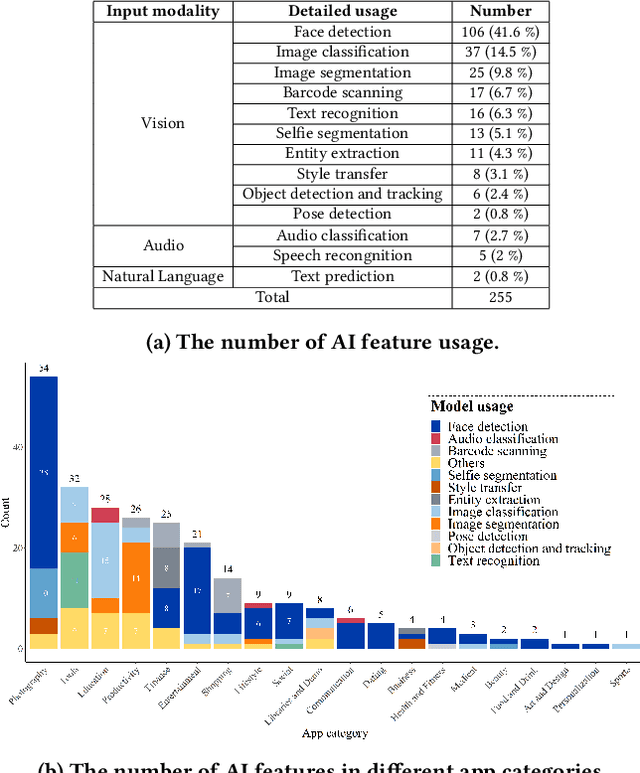
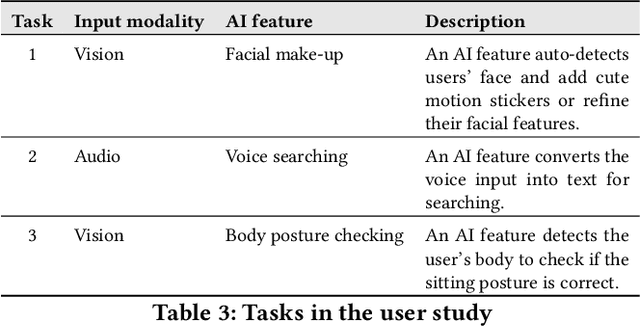
With the emergence of deep learning techniques, smartphone apps are now embedded on-device AI features for enabling advanced tasks like speech translation, to attract users and increase market competitiveness. A good interaction design is important to make an AI feature usable and understandable. However, AI features have their unique challenges like sensitiveness to the input, dynamic behaviours and output uncertainty. Existing guidelines and tools either do not cover AI features or consider mobile apps which are confirmed by our informal interview with professional designers. To address these issues, we conducted the first empirical study to explore user-AI-interaction in mobile apps. We aim to understand the status of on-device AI usage by investigating 176 AI apps from 62,822 apps. We identified 255 AI features and summarised 759 implementations into three primary interaction pattern types. We further implemented our findings into a multi-faceted search-enabled gallery. The results of the user study demonstrate the usefulness of our findings.
Enhancing Virtual Assistant Intelligence: Precise Area Targeting for Instance-level User Intents beyond Metadata
Jun 07, 2023Virtual assistants have been widely used by mobile phone users in recent years. Although their capabilities of processing user intents have been developed rapidly, virtual assistants in most platforms are only capable of handling pre-defined high-level tasks supported by extra manual efforts of developers. However, instance-level user intents containing more detailed objectives with complex practical situations, are yet rarely studied so far. In this paper, we explore virtual assistants capable of processing instance-level user intents based on pixels of application screens, without the requirements of extra extensions on the application side. We propose a novel cross-modal deep learning pipeline, which understands the input vocal or textual instance-level user intents, predicts the targeting operational area, and detects the absolute button area on screens without any metadata of applications. We conducted a user study with 10 participants to collect a testing dataset with instance-level user intents. The testing dataset is then utilized to evaluate the performance of our model, which demonstrates that our model is promising with the achievement of 64.43% accuracy on our testing dataset.
Object Detection for Graphical User Interface: Old Fashioned or Deep Learning or a Combination?
Sep 07, 2020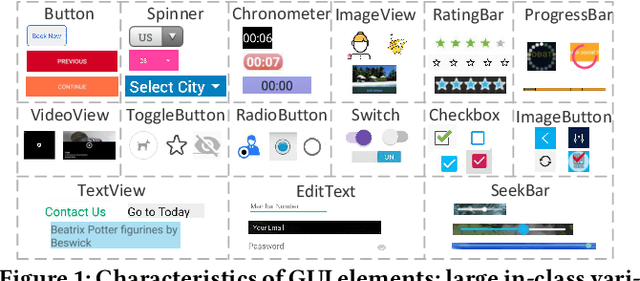

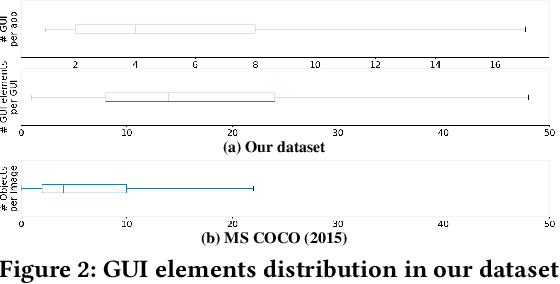
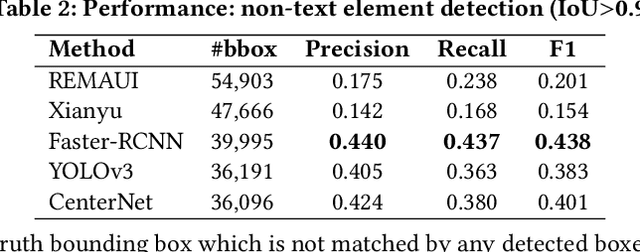
Detecting Graphical User Interface (GUI) elements in GUI images is a domain-specific object detection task. It supports many software engineering tasks, such as GUI animation and testing, GUI search and code generation. Existing studies for GUI element detection directly borrow the mature methods from computer vision (CV) domain, including old fashioned ones that rely on traditional image processing features (e.g., canny edge, contours), and deep learning models that learn to detect from large-scale GUI data. Unfortunately, these CV methods are not originally designed with the awareness of the unique characteristics of GUIs and GUI elements and the high localization accuracy of the GUI element detection task. We conduct the first large-scale empirical study of seven representative GUI element detection methods on over 50k GUI images to understand the capabilities, limitations and effective designs of these methods. This study not only sheds the light on the technical challenges to be addressed but also informs the design of new GUI element detection methods. We accordingly design a new GUI-specific old-fashioned method for non-text GUI element detection which adopts a novel top-down coarse-to-fine strategy, and incorporate it with the mature deep learning model for GUI text detection.Our evaluation on 25,000 GUI images shows that our method significantly advances the start-of-the-art performance in GUI element detection.
Unblind Your Apps: Predicting Natural-Language Labels for Mobile GUI Components by Deep Learning
Mar 01, 2020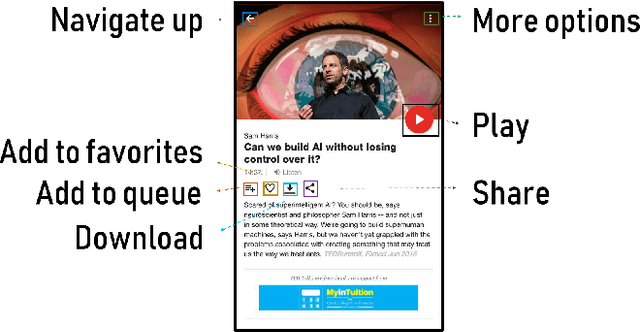

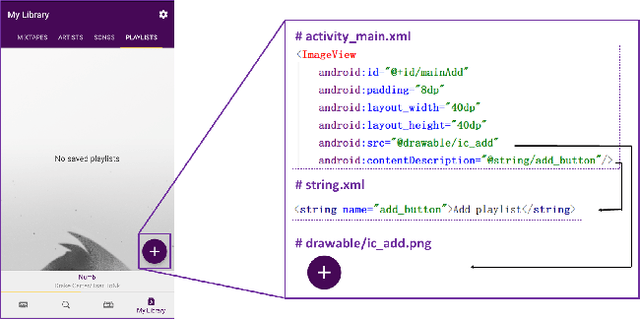
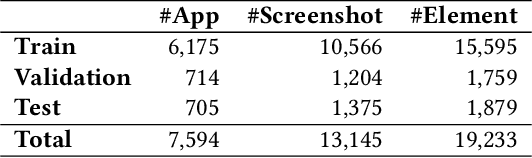
According to the World Health Organization(WHO), it is estimated that approximately 1.3 billion people live with some forms of vision impairment globally, of whom 36 million are blind. Due to their disability, engaging these minority into the society is a challenging problem. The recent rise of smart mobile phones provides a new solution by enabling blind users' convenient access to the information and service for understanding the world. Users with vision impairment can adopt the screen reader embedded in the mobile operating systems to read the content of each screen within the app, and use gestures to interact with the phone. However, the prerequisite of using screen readers is that developers have to add natural-language labels to the image-based components when they are developing the app. Unfortunately, more than 77% apps have issues of missing labels, according to our analysis of 10,408 Android apps. Most of these issues are caused by developers' lack of awareness and knowledge in considering the minority. And even if developers want to add the labels to UI components, they may not come up with concise and clear description as most of them are of no visual issues. To overcome these challenges, we develop a deep-learning based model, called LabelDroid, to automatically predict the labels of image-based buttons by learning from large-scale commercial apps in Google Play. The experimental results show that our model can make accurate predictions and the generated labels are of higher quality than that from real Android developers.