 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHEMIS: Towards Practical Intellectual Property Protection for Post-Deployment On-Device Deep Learning Models
Mar 31, 2025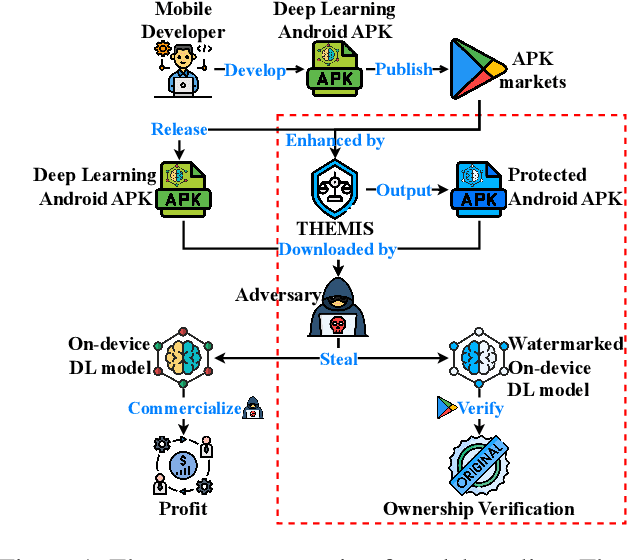

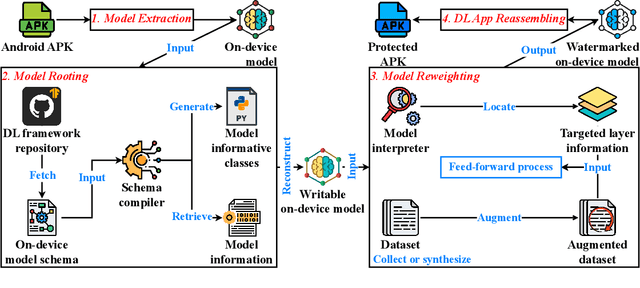
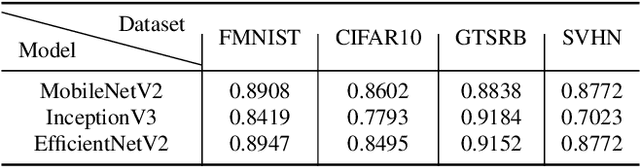
On-device deep learning (DL) has rapidly gained adoption in mobile apps, offering the benefits of offline model inference and user privacy preservation over cloud-based approaches. However, it inevitably stores models on user devices, introducing new vulnerabilities, particularly model-stealing attacks and intellectual property infringement. While system-level protections like Trusted Execution Environments (TEEs) provide a robust solution, practical challenges remain in achieving scalable on-device DL model protection, including complexities in supporting third-party models and limited adoption in current mobile solutions. Advancements in TEE-enabled hardware, such as NVIDIA's GPU-based TEEs, may address these obstacles in the future. Currently, watermarking serves as a common defense against model theft but also faces challenges here as many mobile app developers lack corresponding machine learning expertise and the inherent read-only and inference-only nature of on-device DL models prevents third parties like app stores from implementing existing watermarking techniques in post-deployment models. To protect the intellectual property of on-device DL models, in this paper, we propose THEMIS, an automatic tool that lifts the read-only restriction of on-device DL models by reconstructing their writable counterparts and leverages the untrainable nature of on-device DL models to solve watermark parameters and protect the model owner's intellectual property. Extensive experimental results across various datasets and model structures show the superiority of THEMIS in terms of different metrics. Further, an empirical investigation of 403 real-world DL mobile apps from Google Play is performed with a success rate of 81.14%, showing the practicality of THEMIS.
A Data-Driven Real-Time Optimal Power Flow Algorithm Using Local Feedback
Feb 21, 2025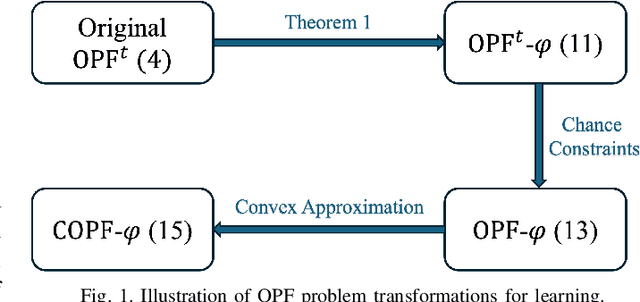
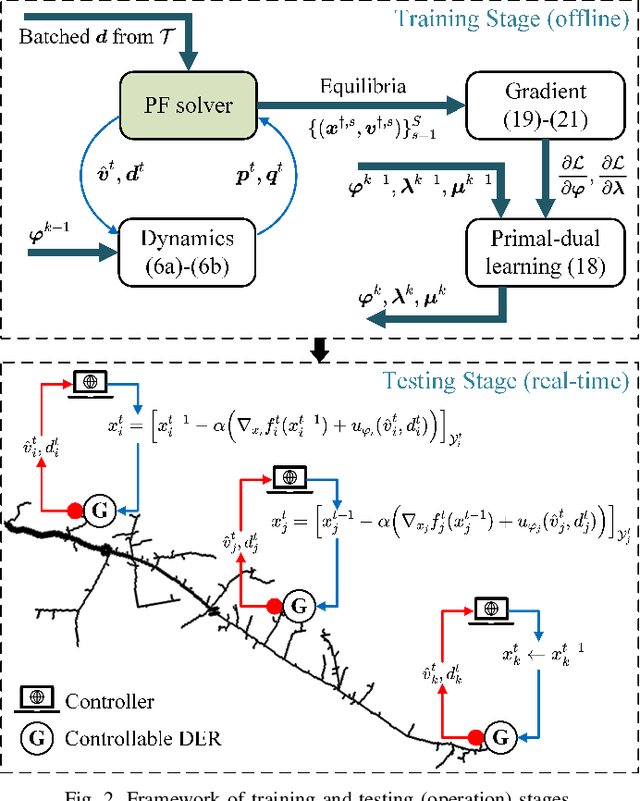
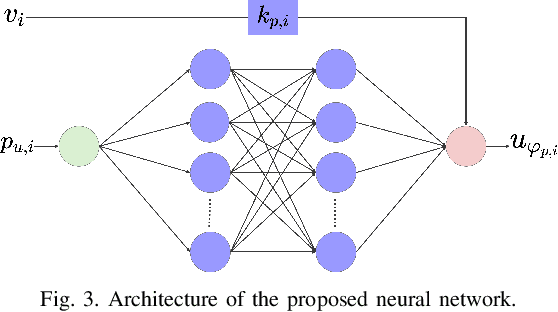
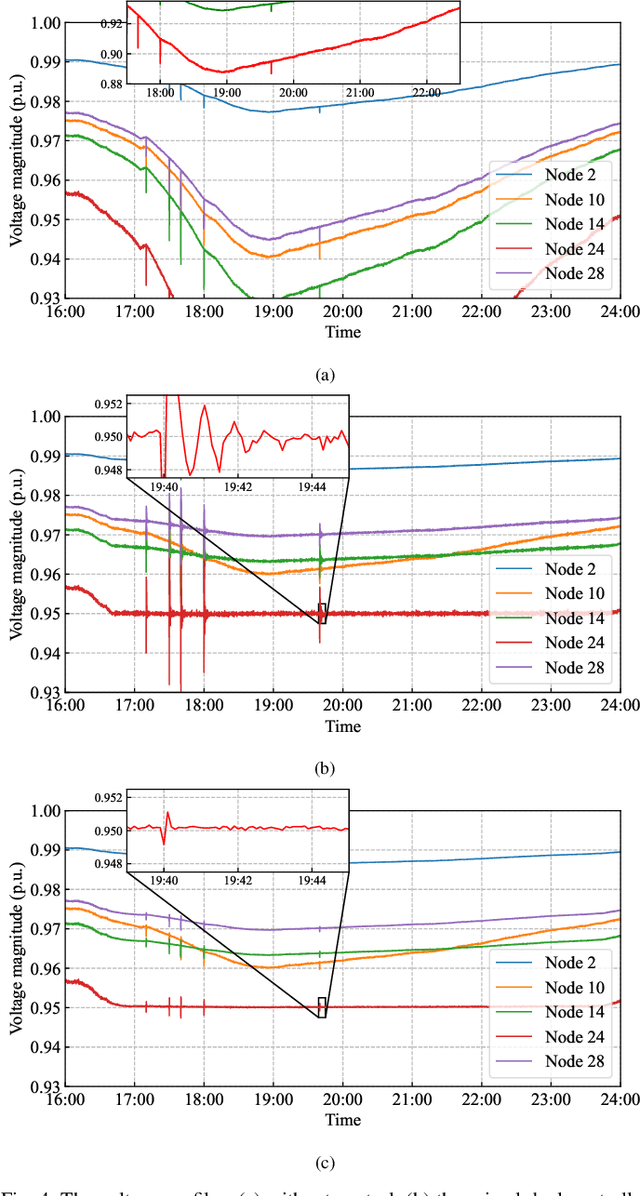
The increasing penetration of distributed energy resources (DERs) adds variability as well as fast control capabilities to power networks. Dispatching the DERs based on local information to provide real-time optimal network operation is the desideratum. In this paper, we propose a data-driven real-time algorithm that uses only the local measurements to solve time-varying AC optimal power flow (OPF). Specifically, we design a learnable function that takes the local feedback as input in the algorithm. The learnable function, under certain conditions, will result in a unique stationary point of the algorithm, which in turn transfers the OPF problems to be optimized over the parameters of the function. We then develop a stochastic primal-dual update to solve the variant of the OPF problems based on a deep neural network (DNN) parametrization of the learnable function, which is referred to as the training stage. We also design a gradient-free alternative to bypass the cumbersome gradient calculation of the nonlinear power flow model. The OPF solution-tracking error bound is established in the sense of universal approximation of DNN. Numerical results on the IEEE 37-bus test feeder show that the proposed method can track the time-varying OPF solutions with higher accuracy and faster computation compared to benchmark methods.
Causal Discovery Inspired Unsupervised Domain Adaptation for Emotion-Cause Pair Extraction
Jun 18, 2024
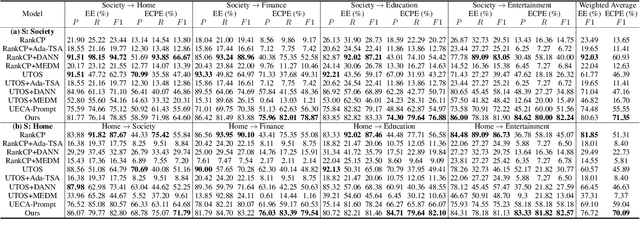
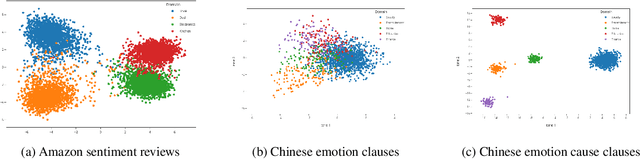
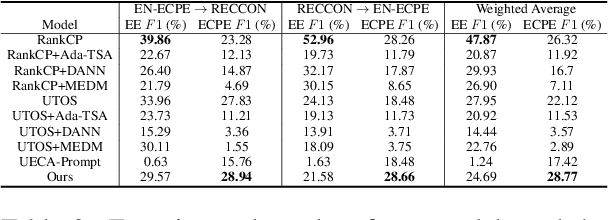
This paper tackles the task of emotion-cause pair extraction in the unsupervised domain adaptation setting. The problem is challenging as the distributions of the events causing emotions in target domains are dramatically different than those in source domains, despite the distributions of emotional expressions between domains are overlapped. Inspired by causal discovery, we propose a novel deep latent model in the variational autoencoder (VAE) framework, which not only captures the underlying latent structures of data but also utilizes the easily transferable knowledge of emotions as the bridge to link the distributions of events in different domains. To facilitate knowledge transfer across domains, we also propose a novel variational posterior regularization technique to disentangle the latent representations of emotions from those of events in order to mitigate the damage caused by the spurious correlations related to the events in source domains. Through extensive experiments, we demonstrate that our model outperforms the strongest baseline by approximately 11.05% on a Chinese benchmark and 2.45% on a English benchmark in terms of weighted-average F1 score. The source code will be publicly available upon acceptance.
Pairwise GUI Dataset Construction Between Android Phones and Tablets
Oct 12, 2023In the current landscape of pervasive smartphones and tablets, apps frequently exist across both platforms. Although apps share most graphic user interfaces (GUIs) and functionalities across phones and tablets, developers often rebuild from scratch for tablet versions, escalating costs and squandering existing design resources. Researchers are attempting to collect data and employ deep learning in automated GUIs development to enhance developers' productivity. There are currently several publicly accessible GUI page datasets for phones, but none for pairwise GUIs between phones and tablets. This poses a significant barrier to the employment of deep learning in automated GUI development. In this paper, we introduce the Papt dataset, a pioneering pairwise GUI dataset tailored for Android phones and tablets, encompassing 10,035 phone-tablet GUI page pairs sourced from 5,593 unique app pairs. We propose novel pairwise GUI collection approaches for constructing this dataset and delineate its advantages over currently prevailing datasets in the field. Through preliminary experiments on this dataset, we analyze the present challenges of utilizing deep learning in automated GUI development.
Towards Real Smart Apps: Investigating Human-AI Interactions in Smartphone On-Device AI Apps
Jul 03, 2023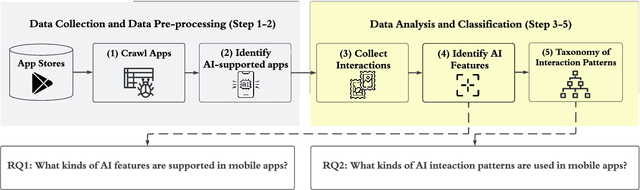
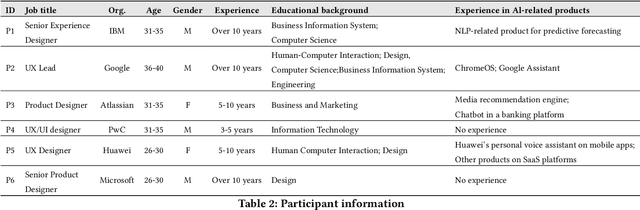
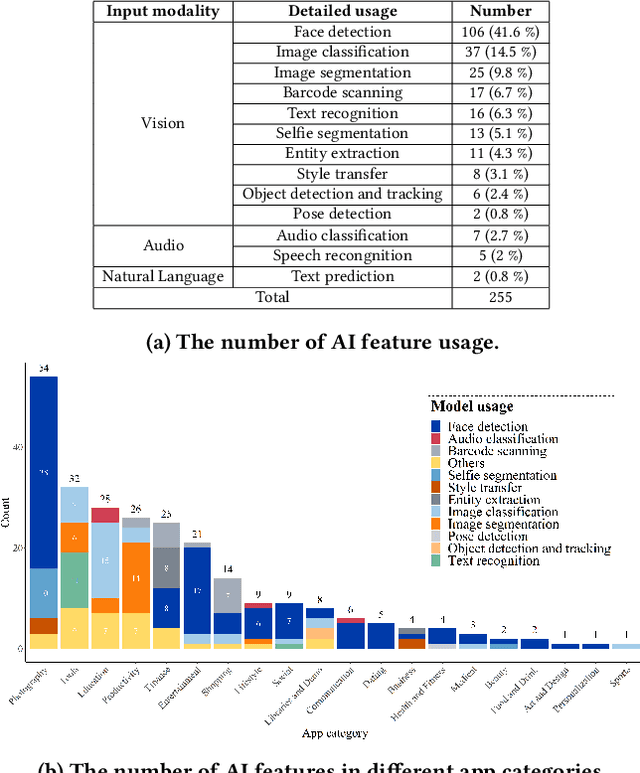
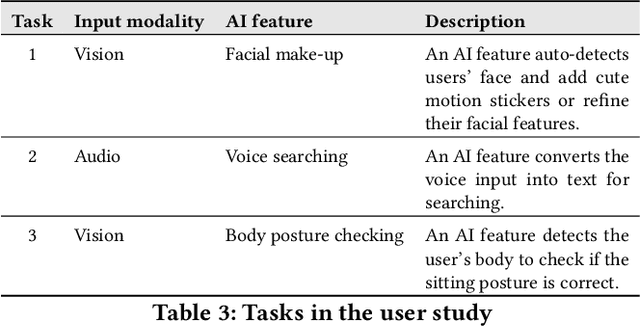
With the emergence of deep learning techniques, smartphone apps are now embedded on-device AI features for enabling advanced tasks like speech translation, to attract users and increase market competitiveness. A good interaction design is important to make an AI feature usable and understandable. However, AI features have their unique challenges like sensitiveness to the input, dynamic behaviours and output uncertainty. Existing guidelines and tools either do not cover AI features or consider mobile apps which are confirmed by our informal interview with professional designers. To address these issues, we conducted the first empirical study to explore user-AI-interaction in mobile apps. We aim to understand the status of on-device AI usage by investigating 176 AI apps from 62,822 apps. We identified 255 AI features and summarised 759 implementations into three primary interaction pattern types. We further implemented our findings into a multi-faceted search-enabled gallery. The results of the user study demonstrate the usefulness of our findings.
Energy-Latency Attacks to On-Device Neural Networks via Sponge Poisoning
May 11, 2023In recent years, on-device deep learning has gained attention as a means of developing affordable deep learning applications for mobile devices. However, on-device models are constrained by limited energy and computation resources. In the mean time, a poisoning attack known as sponge poisoning has been developed.This attack involves feeding the model with poisoned examples to increase the energy consumption during inference. As previous work is focusing on server hardware accelerators, in this work, we extend the sponge poisoning attack to an on-device scenario to evaluate the vulnerability of mobile device processors. We present an on-device sponge poisoning attack pipeline to simulate the streaming and consistent inference scenario to bridge the knowledge gap in the on-device setting. Our exclusive experimental analysis with processors and on-device networks shows that sponge poisoning attacks can effectively pollute the modern processor with its built-in accelerator. We analyze the impact of different factors in the sponge poisoning algorithm and highlight the need for improved defense mechanisms to prevent such attacks on on-device deep learning applications.
Beyond the Model: Data Pre-processing Attack to Deep Learning Models in Android Apps
May 11, 2023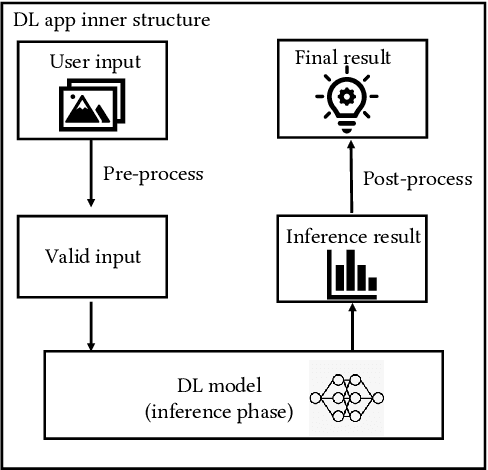
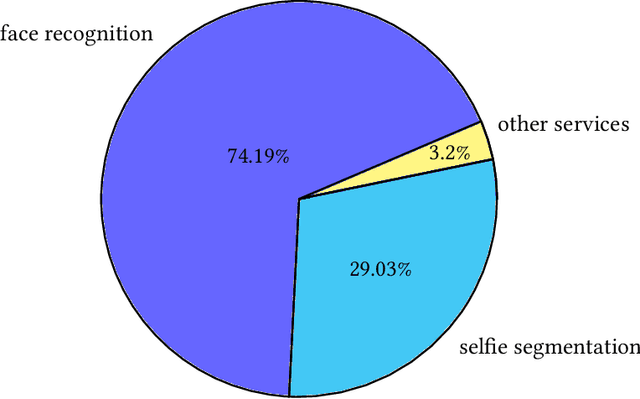

The increasing popularity of deep learning (DL) models and the advantages of computing, including low latency and bandwidth savings on smartphones, have led to the emergence of intelligent mobile applications, also known as DL apps, in recent years. However, this technological development has also given rise to several security concerns, including adversarial examples, model stealing, and data poisoning issues. Existing works on attacks and countermeasures for on-device DL models have primarily focused on the models themselves. However, scant attention has been paid to the impact of data processing disturbance on the model inference. This knowledge disparity highlights the need for additional research to fully comprehend and address security issues related to data processing for on-device models. In this paper, we introduce a data processing-based attacks against real-world DL apps. In particular, our attack could influence the performance and latency of the model without affecting the operation of a DL app. To demonstrate the effectiveness of our attack, we carry out an empirical study on 517 real-world DL apps collected from Google Play. Among 320 apps utilizing MLkit, we find that 81.56\% of them can be successfully attacked. The results emphasize the importance of DL app developers being aware of and taking actions to secure on-device models from the perspective of data processing.
Training-free Lexical Backdoor Attacks on Language Models
Feb 08, 2023



Large-scale language models have achieved tremendous success across various natural language processing (NLP) applications. Nevertheless, language models are vulnerable to backdoor attacks, which inject stealthy triggers into models for steering them to undesirable behaviors. Most existing backdoor attacks, such as data poisoning, require further (re)training or fine-tuning language models to learn the intended backdoor patterns. The additional training process however diminishes the stealthiness of the attacks, as training a language model usually requires long optimization time, a massive amount of data, and considerable modifications to the model parameters. In this work, we propose Training-Free Lexical Backdoor Attack (TFLexAttack) as the first training-free backdoor attack on language models. Our attack is achieved by injecting lexical triggers into the tokenizer of a language model via manipulating its embedding dictionary using carefully designed rules. These rules are explainable to human developers which inspires attacks from a wider range of hackers. The sparse manipulation of the dictionary also habilitates the stealthiness of our attack. We conduct extensive experiments on three dominant NLP tasks based on nine language models to demonstrate the effectiveness and universality of our attack. The code of this work is available at https://github.com/Jinxhy/TFLexAttack.
On Robustness of Prompt-based Semantic Parsing with Large Pre-trained Language Model: An Empirical Study on Codex
Feb 06, 2023



Semantic parsing is a technique aimed at constructing a structured representation of the meaning of a natural-language question. Recent advancements in few-shot language models trained on code have demonstrated superior performance in generating these representations compared to traditional unimodal language models, which are trained on downstream tasks. Despite these advancements, existing fine-tuned neural semantic parsers are susceptible to adversarial attacks on natural-language inputs. While it has been established that the robustness of smaller semantic parsers can be enhanced through adversarial training, this approach is not feasible for large language models in real-world scenarios, as it requires both substantial computational resources and expensive human annotation on in-domain semantic parsing data. This paper presents the first empirical study on the adversarial robustness of a large prompt-based language model of code, \codex. Our results demonstrate that the state-of-the-art (SOTA) code-language models are vulnerable to carefully crafted adversarial examples. To address this challenge, we propose methods for improving robustness without the need for significant amounts of labeled data or heavy computational resources.
Exploring AI Ethics of ChatGPT: A Diagnostic Analysis
Jan 30, 2023



Recent breakthroughs in natural language processing (NLP) have permitted the synthesis and comprehension of coherent text in an open-ended way, therefore translating the theoretical algorithms into practical applications. The large language-model (LLM) has significantly impacted businesses such as report summarization softwares and copywriters. Observations indicate, however, that LLMs may exhibit social prejudice and toxicity, posing ethical and societal dangers of consequences resulting from irresponsibility. Large-scale benchmarks for accountable LLMs should consequently be developed. Although several empirical investigations reveal the existence of a few ethical difficulties in advanced LLMs, there is no systematic examination and user study of the ethics of current LLMs use. To further educate future efforts on constructing ethical LLMs responsibly, we perform a qualitative research method on OpenAI's ChatGPT to better understand the practical features of ethical dangers in recent LLMs. We analyze ChatGPT comprehensively from four perspectives: 1) \textit{Bias} 2) \textit{Reliability} 3) \textit{Robustness} 4) \textit{Toxicity}. In accordance with our stated viewpoints, we empirically benchmark ChatGPT on multiple sample datasets. We find that a significant number of ethical risks cannot be addressed by existing benchmarks, and hence illustrate them via additional case studies. In addition, we examine the implications of our findings on the AI ethics of ChatGPT, as well as future problems and practical design considerations for LLMs. We believe that our findings may give light on future efforts to determine and mitigate the ethical hazards posed by machines in LLM applications.