 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Weight Tying: Pseudo-Inverse Tying for Stable LM Training and Updates
Feb 04, 2026Weight tying is widely used in compact language models to reduce parameters by sharing the token table between the input embedding and the output projection. However, weight sharing does not guarantee a stable token interface: during training, the correspondence between encoding tokens into hidden states and decoding hidden states into logits can drift, worsening optimization sensitivity and making post-training interventions such as editing, patching, and lightweight adaptation less predictable. We propose Pseudo-Inverse Tying (PIT), which synchronizes embedding and unembedding as coupled projections of a shared latent token memory, guaranteeing a pseudo-inverse-consistent interface throughout training. PIT maintains an orthonormal shared memory, obtained by thin polar decomposition for teacher initialization or random orthonormal initialization from scratch, and introduces a fully learned symmetric positive definite hidden-space transform parameterized via a Cholesky factor. The output head applies this transform to hidden states before the vocabulary projection, while the embedding applies the inverse transform to token vectors using stable triangular solves, avoiding explicit pseudo-inverse recomputation and any vocabulary-sized auxiliary parameters. We evaluate PIT on on-device models spanning 256M-1.3B parameters across pretraining and adaptation, and consistently observe improved training stability, stronger layerwise semantic consistency, and substantially reduced side effects.
Adoption of Generative Artificial Intelligence in the German Software Engineering Industry: An Empirical Study
Jan 23, 2026Generative artificial intelligence (GenAI) tools have seen rapid adoption among software developers. While adoption rates in the industry are rising, the underlying factors influencing the effective use of these tools, including the depth of interaction, organizational constraints, and experience-related considerations, have not been thoroughly investigated. This issue is particularly relevant in environments with stringent regulatory requirements, such as Germany, where practitioners must address the GDPR and the EU AI Act while balancing productivity gains with intellectual property considerations. Despite the significant impact of GenAI on software engineering, to the best of our knowledge, no empirical study has systematically examined the adoption dynamics of GenAI tools within the German context. To address this gap, we present a comprehensive mixed-methods study on GenAI adoption among German software engineers. Specifically, we conducted 18 exploratory interviews with practitioners, followed by a developer survey with 109 participants. We analyze patterns of tool adoption, prompting strategies, and organizational factors that influence effectiveness. Our results indicate that experience level moderates the perceived benefits of GenAI tools, and productivity gains are not evenly distributed among developers. Further, organizational size affects both tool selection and the intensity of tool use. Limited awareness of the project context is identified as the most significant barrier. We summarize a set of actionable implications for developers, organizations, and tool vendors seeking to advance artificial intelligence (AI) assisted software development.
SeMe: Training-Free Language Model Merging via Semantic Alignment
May 26, 2025Despite the remarkable capabilities of Language Models (LMs) across diverse tasks, no single model consistently outperforms others, necessitating efficient methods to combine their strengths without expensive retraining. Existing model merging techniques, such as parameter averaging and task-guided fusion, often rely on data-dependent computations or fail to preserve internal knowledge, limiting their robustness and scalability. We introduce SeMe (Semantic-based Merging), a novel, data-free, and training-free approach that leverages latent semantic alignment to merge LMs at a fine-grained, layer-wise level. Unlike prior work, SeMe not only preserves model behaviors but also explicitly stabilizes internal knowledge, addressing a critical gap in LM fusion. Through extensive experiments across diverse architectures and tasks, we demonstrate that SeMe outperforms existing methods in both performance and efficiency while eliminating reliance on external data. Our work establishes a new paradigm for knowledge-aware model merging and provides insights into the semantic structure of LMs, paving the way for more scalable and interpretable model composition.
THEMIS: Towards Practical Intellectual Property Protection for Post-Deployment On-Device Deep Learning Models
Mar 31, 2025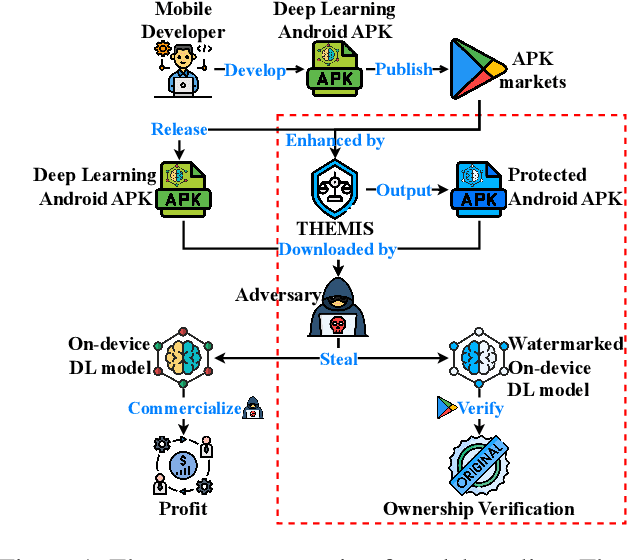

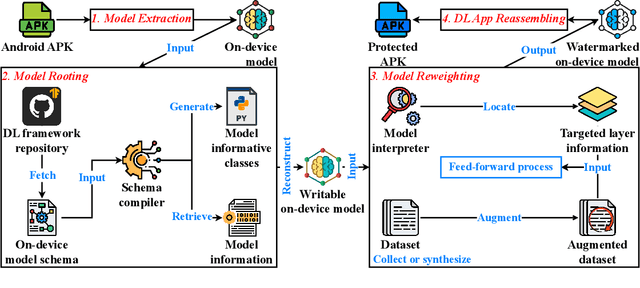
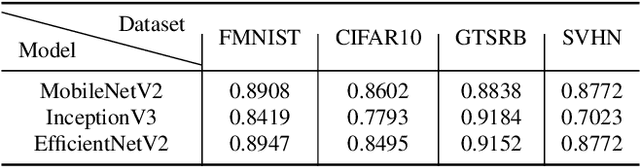
On-device deep learning (DL) has rapidly gained adoption in mobile apps, offering the benefits of offline model inference and user privacy preservation over cloud-based approaches. However, it inevitably stores models on user devices, introducing new vulnerabilities, particularly model-stealing attacks and intellectual property infringement. While system-level protections like Trusted Execution Environments (TEEs) provide a robust solution, practical challenges remain in achieving scalable on-device DL model protection, including complexities in supporting third-party models and limited adoption in current mobile solutions. Advancements in TEE-enabled hardware, such as NVIDIA's GPU-based TEEs, may address these obstacles in the future. Currently, watermarking serves as a common defense against model theft but also faces challenges here as many mobile app developers lack corresponding machine learning expertise and the inherent read-only and inference-only nature of on-device DL models prevents third parties like app stores from implementing existing watermarking techniques in post-deployment models. To protect the intellectual property of on-device DL models, in this paper, we propose THEMIS, an automatic tool that lifts the read-only restriction of on-device DL models by reconstructing their writable counterparts and leverages the untrainable nature of on-device DL models to solve watermark parameters and protect the model owner's intellectual property. Extensive experimental results across various datasets and model structures show the superiority of THEMIS in terms of different metrics. Further, an empirical investigation of 403 real-world DL mobile apps from Google Play is performed with a success rate of 81.14%, showing the practicality of THEMIS.
A Semantic-based Optimization Approach for Repairing LLMs: Case Study on Code Generation
Mar 17, 2025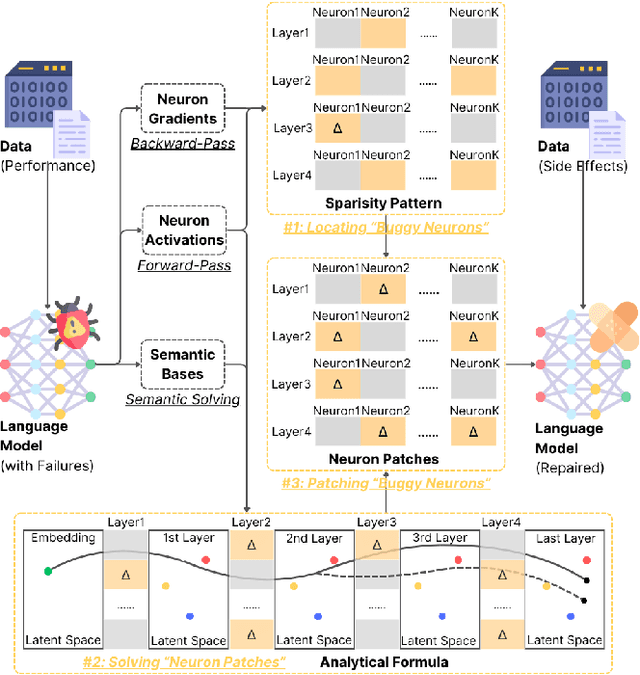
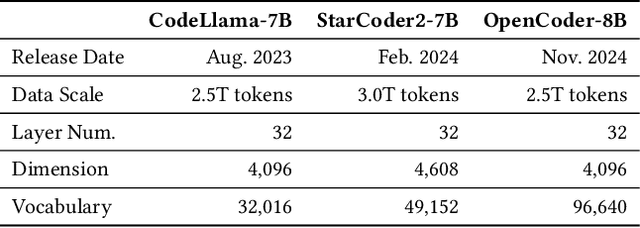
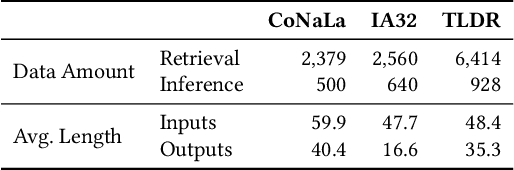
Language Models (LMs) are widely used in software engineering for code generation, but they may produce code with errors. Rather than repairing the generated code, an alternative way is to address the underlying failures of models. LM repair offers a lightweight solution to this challenge: it requires minimal data, reduces computational costs, and reduces the side effects. Unlike retraining, LM repair focuses on applying tailored updates to targeted neurons, making it ideal for scenarios with limited resources, high-performance demands, or strict safety requirements. In this paper, we propose \ul{S}emantic \ul{T}argeting for \ul{A}nalytical \ul{R}epair (\textsc{STAR}), a pioneering and novel semantic-based optimization approach for repairing LLMs. \textsc{STAR} realizes main operations in LM repair methods in an optimization process, including locating ``buggy neurons'', solving ``neuron patches'', and patching ``buggy neurons''. Correspondingly, it computes the deltas of weight matrix as the prior information to guide optimization; and attributes the targeted layers and neurons leveraging statistical insights. The neuron patches are computed with a solid semantic-based analytical formula, which directly bridges the changes to logits with the deltas of neurons, by steering latent representations. Compared to the prior work of LM repair (\textsc{MINT}) and optimization methods (\textsc{SGD}), \textsc{STAR} integrates their strengths while mitigating their limitations. \textsc{STAR} supports solving multiple failures together, significantly improving the usefulness. Evaluated on three code generation tasks using popular code LMs, \textsc{STAR} demonstrates superior effectiveness. Additionally, \textsc{STAR} exhibits better efficiency. In terms of side effects, namely the balance between generalization and specificity, \textsc{STAR} outperforms prior work by a significant margin.
A Semantic-based Layer Freezing Approach to Efficient Fine-Tuning of Language Models
Jun 17, 2024



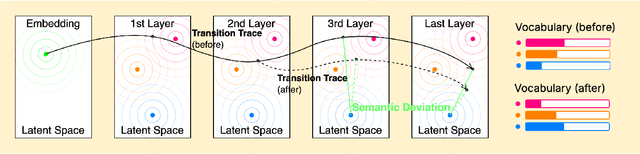
Finetuning language models (LMs) is crucial for adapting the models to downstream data and tasks. However, full finetuning is usually costly. Existing work, such as parameter-efficient finetuning (PEFT), often focuses on \textit{how to finetune} but neglects the issue of \textit{where to finetune}. As a pioneering work on answering where to finetune (at the layer level), we conduct a semantic analysis of the LM inference process. We first propose a virtual transition of the latent representation and then trace its factual transition. Based on the deviation in transitions, we estimate the gain of finetuning each model layer, and further, narrow down the scope for finetuning. We perform extensive experiments across well-known LMs and datasets. The results show that our approach is effective and efficient, and outperforms the existing baselines. Our approach is orthogonal to existing efficient techniques, such as PEFT methods, offering practical values on LM finetuning.
Beyond Accuracy: An Empirical Study on Unit Testing in Open-source Deep Learning Projects
Feb 26, 2024



Deep Learning (DL) models have rapidly advanced, focusing on achieving high performance through testing model accuracy and robustness. However, it is unclear whether DL projects, as software systems, are tested thoroughly or functionally correct when there is a need to treat and test them like other software systems. Therefore, we empirically study the unit tests in open-source DL projects, analyzing 9,129 projects from GitHub. We find that: 1) unit tested DL projects have positive correlation with the open-source project metrics and have a higher acceptance rate of pull requests, 2) 68% of the sampled DL projects are not unit tested at all, 3) the layer and utilities (utils) of DL models have the most unit tests. Based on these findings and previous research outcomes, we built a mapping taxonomy between unit tests and faults in DL projects. We discuss the implications of our findings for developers and researchers and highlight the need for unit testing in open-source DL projects to ensure their reliability and stability. The study contributes to this community by raising awareness of the importance of unit testing in DL projects and encouraging further research in this area.
On the Semantics of LM Latent Space: A Vocabulary-defined Approach
Feb 02, 2024



Understanding the latent space of language models (LM) is crucial to refining their performance and interpretability. Existing analyses often fall short in providing disentangled (model-centric) insights into LM semantics, and neglect essential aspects of LM adaption. In response, we introduce a pioneering method called vocabulary-defined semantics, which establishes a reference frame within the LM latent space, ensuring disentangled semantic analysis grounded in LM vocabulary. Our approach transcends prior entangled analysis, leveraging LM vocabulary for model-centric insights. Furthermore, we propose a novel technique to compute logits, emphasising differentiability and local isotropy, and introduce a neural clustering module for semantically calibrating data representations during LM adaptation. Through extensive experiments across diverse text understanding datasets, our approach outperforms state-of-the-art methods of retrieval-augmented generation and parameter-efficient finetuning, showcasing its efficacy and broad applicability. Our findings not only shed light on LM mechanics, but also offer practical solutions to enhance LM performance and interpretability.
Neuron Patching: Neuron-level Model Editing on Code Generation and LLMs
Dec 08, 2023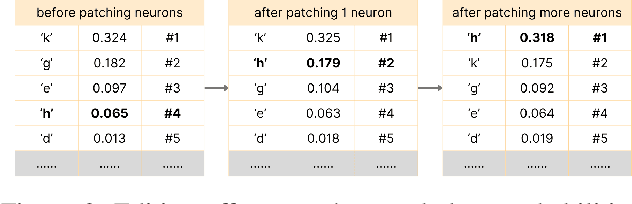
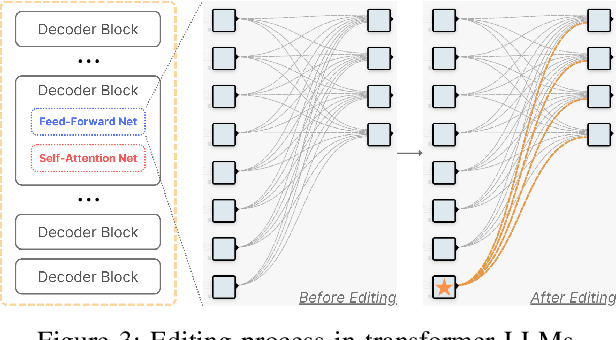
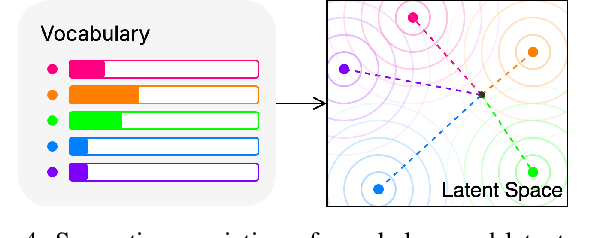
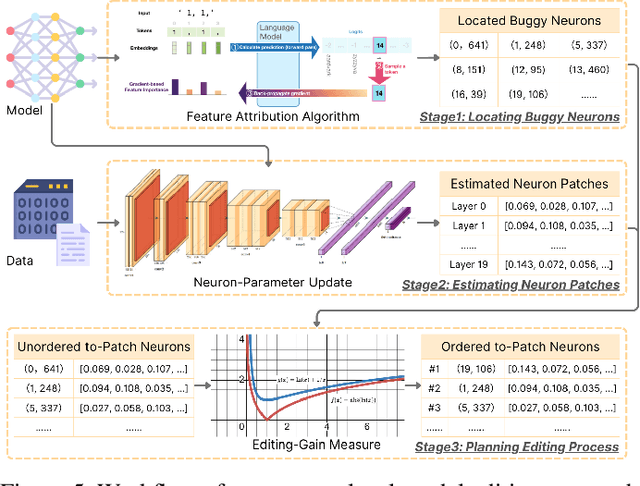
Large Language Models are successfully adopted in software engineering, especially in code generation. Updating these models with new knowledge is very expensive, and is often required to fully realize their value. In this paper, we propose a novel and effective model editing approach, \textsc{MENT}, to patch LLMs in coding tasks. Based on the mechanism of generative LLMs, \textsc{MENT} enables model editing in next-token predictions, and further supports common coding tasks. \textsc{MENT} is effective, efficient, and reliable. It can correct a neural model by patching 1 or 2 neurons. As the pioneer work on neuron-level model editing of generative models, we formalize the editing process and introduce the involved concepts. Besides, we also introduce new measures to evaluate its generalization ability, and build a benchmark for further study. Our approach is evaluated on three coding tasks, including API-seq recommendation, line-level code generation, and pseudocode-to-code transaction. It outperforms the state-of-the-art by a significant margin on both effectiveness and efficiency measures. In addition, we demonstrate the usages of \textsc{MENT} for LLM reasoning in software engineering. By editing the LLM knowledge with \textsc{MENT}, the directly or indirectly dependent behaviors in the chain-of-thought change accordingly and automatically.
GNNEvaluator: Evaluating GNN Performance On Unseen Graphs Without Labels
Oct 26, 2023



Evaluating the performance of graph neural networks (GNNs) is an essential task for practical GNN model deployment and serving, as deployed GNNs face significant performance uncertainty when inferring on unseen and unlabeled test graphs, due to mismatched training-test graph distributions. In this paper, we study a new problem, GNN model evaluation, that aims to assess the performance of a specific GNN model trained on labeled and observed graphs, by precisely estimating its performance (e.g., node classification accuracy) on unseen graphs without labels. Concretely, we propose a two-stage GNN model evaluation framework, including (1) DiscGraph set construction and (2) GNNEvaluator training and inference. The DiscGraph set captures wide-range and diverse graph data distribution discrepancies through a discrepancy measurement function, which exploits the outputs of GNNs related to latent node embeddings and node class predictions. Under the effective training supervision from the DiscGraph set, GNNEvaluator learns to precisely estimate node classification accuracy of the to-be-evaluated GNN model and makes an accurate inference for evaluating GNN model performance. Extensive experiments on real-world unseen and unlabeled test graphs demonstrate the effectiveness of our proposed method for GNN model evaluation.