 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStill Manual? Automated Linter Configuration via DSL-Based LLM Compilation of Coding Standards
Feb 08, 2026Coding standards are essential for maintaining consistent and high-quality code across teams and projects. Linters help developers enforce these standards by detecting code violations. However, manual linter configuration is complex and expertise-intensive, and the diversity and evolution of programming languages, coding standards, and linters lead to repetitive and maintenance-intensive configuration work. To reduce manual effort, we propose LintCFG, a domain-specific language (DSL)-driven, LLM-based compilation approach to automate linter configuration generation for coding standards, independent of programming languages, coding standards, and linters. Inspired by compiler design, we first design a DSL to express coding rules in a tool-agnostic, structured, readable, and precise manner. Then, we build linter configurations into DSL configuration instructions. For a given natural language coding standard, the compilation process parses it into DSL coding standards, matches them with the DSL configuration instructions to set configuration names, option names and values, verifies consistency between the standards and configurations, and finally generates linter-specific configurations. Experiments with Checkstyle for Java coding standard show that our approach achieves over 90% precision and recall in DSL representation, with accuracy, precision, recall, and F1-scores close to 70% (with some exceeding 70%) in fine-grained linter configuration generation. Notably, our approach outperforms baselines by over 100% in precision. A user study further shows that our approach improves developers' efficiency in configuring linters for coding standards. Finally, we demonstrate the generality of the approach by generating ESLint configurations for JavaScript coding standards, showcasing its broad applicability across other programming languages, coding standards, and linters.
Improving Methodologies for LLM Evaluations Across Global Languages
Jan 22, 2026As frontier AI models are deployed globally, it is essential that their behaviour remains safe and reliable across diverse linguistic and cultural contexts. To examine how current model safeguards hold up in such settings, participants from the International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the EU, France, Kenya, South Korea and the UK conducted a joint multilingual evaluation exercise. Led by Singapore AISI, two open-weight models were tested across ten languages spanning high and low resourced groups: Cantonese English, Farsi, French, Japanese, Korean, Kiswahili, Malay, Mandarin Chinese and Telugu. Over 6,000 newly translated prompts were evaluated across five harm categories (privacy, non-violent crime, violent crime, intellectual property and jailbreak robustness), using both LLM-as-a-judge and human annotation. The exercise shows how safety behaviours can vary across languages. These include differences in safeguard robustness across languages and harm types and variation in evaluator reliability (LLM-as-judge vs. human review). Further, it also generated methodological insights for improving multilingual safety evaluations, such as the need for culturally contextualised translations, stress-tested evaluator prompts and clearer human annotation guidelines. This work represents an initial step toward a shared framework for multilingual safety testing of advanced AI systems and calls for continued collaboration with the wider research community and industry.
Improving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
MARIA: A Framework for Marginal Risk Assessment without Ground Truth in AI Systems
Oct 31, 2025Before deploying an AI system to replace an existing process, it must be compared with the incumbent to ensure improvement without added risk. Traditional evaluation relies on ground truth for both systems, but this is often unavailable due to delayed or unknowable outcomes, high costs, or incomplete data, especially for long-standing systems deemed safe by convention. The more practical solution is not to compute absolute risk but the difference between systems. We therefore propose a marginal risk assessment framework, that avoids dependence on ground truth or absolute risk. It emphasizes three kinds of relative evaluation methodology, including predictability, capability and interaction dominance. By shifting focus from absolute to relative evaluation, our approach equips software teams with actionable guidance: identifying where AI enhances outcomes, where it introduces new risks, and how to adopt such systems responsibly.
Bi-level Personalization for Federated Foundation Models: A Task-vector Aggregation Approach
Sep 16, 2025Federated foundation models represent a new paradigm to jointly fine-tune pre-trained foundation models across clients. It is still a challenge to fine-tune foundation models for a small group of new users or specialized scenarios, which typically involve limited data compared to the large-scale data used in pre-training. In this context, the trade-off between personalization and federation becomes more sensitive. To tackle these, we proposed a bi-level personalization framework for federated fine-tuning on foundation models. Specifically, we conduct personalized fine-tuning on the client-level using its private data, and then conduct a personalized aggregation on the server-level using similar users measured by client-specific task vectors. Given the personalization information gained from client-level fine-tuning, the server-level personalized aggregation can gain group-wise personalization information while mitigating the disturbance of irrelevant or interest-conflict clients with non-IID data. The effectiveness of the proposed algorithm has been demonstrated by extensive experimental analysis in benchmark datasets.
OASIS: Harnessing Diffusion Adversarial Network for Ocean Salinity Imputation using Sparse Drifter Trajectories
Aug 29, 2025Ocean salinity plays a vital role in circulation, climate, and marine ecosystems, yet its measurement is often sparse, irregular, and noisy, especially in drifter-based datasets. Traditional approaches, such as remote sensing and optimal interpolation, rely on linearity and stationarity, and are limited by cloud cover, sensor drift, and low satellite revisit rates. While machine learning models offer flexibility, they often fail under severe sparsity and lack principled ways to incorporate physical covariates without specialized sensors. In this paper, we introduce the OceAn Salinity Imputation System (OASIS), a novel diffusion adversarial framework designed to address these challenges.
Reality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects
May 24, 2025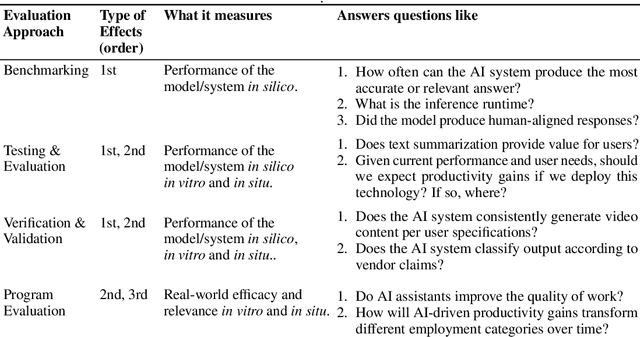
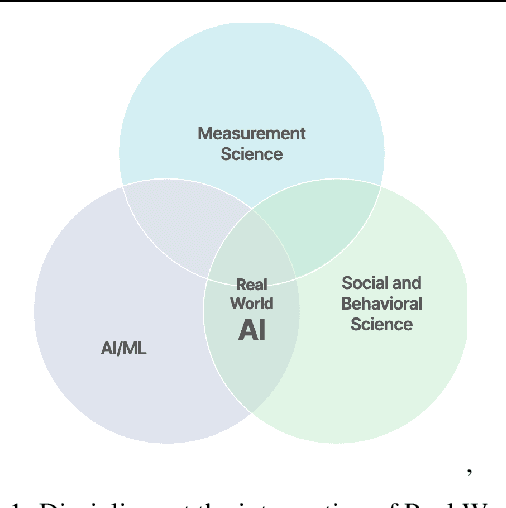

Conventional AI evaluation approaches concentrated within the AI stack exhibit systemic limitations for exploring, navigating and resolving the human and societal factors that play out in real world deployment such as in education, finance, healthcare, and employment sectors. AI capability evaluations can capture detail about first-order effects, such as whether immediate system outputs are accurate, or contain toxic, biased or stereotypical content, but AI's second-order effects, i.e. any long-term outcomes and consequences that may result from AI use in the real world, have become a significant area of interest as the technology becomes embedded in our daily lives. These secondary effects can include shifts in user behavior, societal, cultural and economic ramifications, workforce transformations, and long-term downstream impacts that may result from a broad and growing set of risks. This position paper argues that measuring the indirect and secondary effects of AI will require expansion beyond static, single-turn approaches conducted in silico to include testing paradigms that can capture what actually materializes when people use AI technology in context. Specifically, we describe the need for data and methods that can facilitate contextual awareness and enable downstream interpretation and decision making about AI's secondary effects, and recommend requirements for a new ecosystem.
Federated Adapter on Foundation Models: An Out-Of-Distribution Approach
May 02, 2025As foundation models gain prominence, Federated Foundation Models (FedFM) have emerged as a privacy-preserving approach to collaboratively fine-tune models in federated learning (FL) frameworks using distributed datasets across clients. A key challenge for FedFM, given the versatile nature of foundation models, is addressing out-of-distribution (OOD) generalization, where unseen tasks or clients may exhibit distribution shifts leading to suboptimal performance. Although numerous studies have explored OOD generalization in conventional FL, these methods are inadequate for FedFM due to the challenges posed by large parameter scales and increased data heterogeneity. To address these, we propose FedOA, which employs adapter-based parameter-efficient fine-tuning methods for efficacy and introduces personalized adapters with feature distance-based regularization to align distributions and guarantee OOD generalization for each client. Theoretically, we demonstrate that the conventional aggregated global model in FedFM inherently retains OOD generalization capabilities, and our proposed method enhances the personalized model's OOD generalization through regularization informed by the global model, with proven convergence under general non-convex settings. Empirically, the effectiveness of the proposed method is validated on benchmark datasets across various NLP tasks.
FactFlow: Automatic Fact Sheet Generation and Customization from Tabular Dataset via AI Chain Design & Implementation
Feb 25, 2025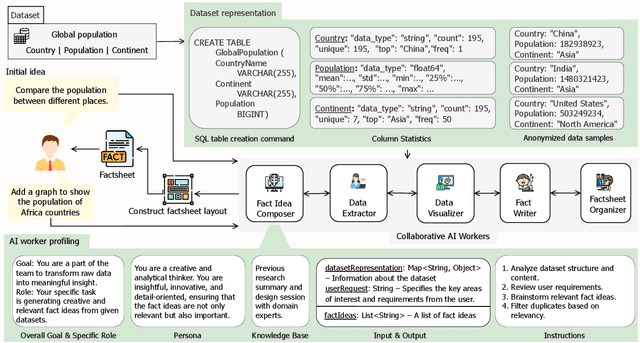
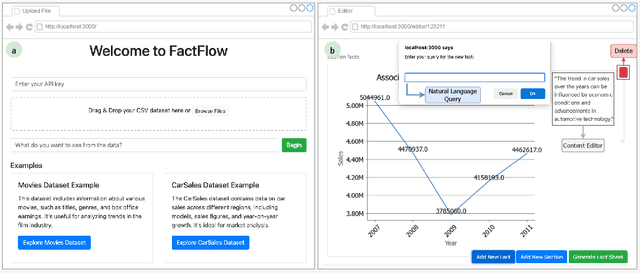
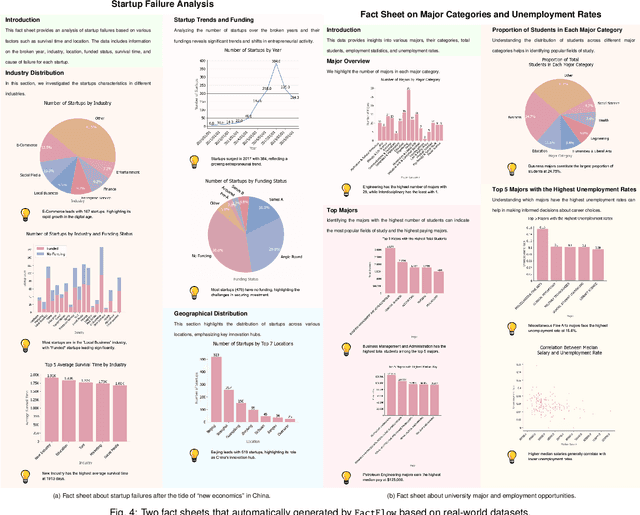
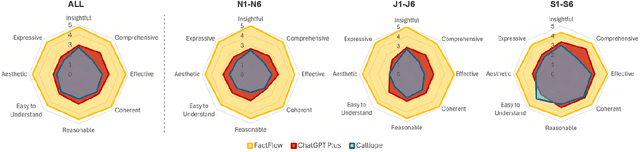
With the proliferation of data across various domains, there is a critical demand for tools that enable non-experts to derive meaningful insights without deep data analysis skills. To address this need, existing automatic fact sheet generation tools offer heuristic-based solutions to extract facts and generate stories. However, they inadequately grasp the semantics of data and struggle to generate narratives that fully capture the semantics of the dataset or align the fact sheet with specific user needs. Addressing these shortcomings, this paper introduces \tool, a novel tool designed for the automatic generation and customisation of fact sheets. \tool applies the concept of collaborative AI workers to transform raw tabular dataset into comprehensive, visually compelling fact sheets. We define effective taxonomy to profile AI worker for specialised tasks. Furthermore, \tool empowers users to refine these fact sheets through intuitive natural language commands, ensuring the final outputs align closely with individual preferences and requirements. Our user evaluation with 18 participants confirms that \tool not only surpasses state-of-the-art baselines in automated fact sheet production but also provides a positive user experience during customization tasks.
Towards Advancing Code Generation with Large Language Models: A Research Roadmap
Jan 20, 2025Recently, we have witnessed the rapid development of large language models, which have demonstrated excellent capabilities in the downstream task of code generation. However, despite their potential, LLM-based code generation still faces numerous technical and evaluation challenges, particularly when embedded in real-world development. In this paper, we present our vision for current research directions, and provide an in-depth analysis of existing studies on this task. We propose a six-layer vision framework that categorizes code generation process into distinct phases, namely Input Phase, Orchestration Phase, Development Phase, and Validation Phase. Additionally, we outline our vision workflow, which reflects on the currently prevalent frameworks. We systematically analyse the challenges faced by large language models, including those LLM-based agent frameworks, in code generation tasks. With these, we offer various perspectives and actionable recommendations in this area. Our aim is to provide guidelines for improving the reliability, robustness and usability of LLM-based code generation systems. Ultimately, this work seeks to address persistent challenges and to provide practical suggestions for a more pragmatic LLM-based solution for future code generation endeavors.