 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIRCLE: A Framework for Evaluating AI from a Real-World Lens
Mar 03, 2026This paper proposes CIRCLE, a six-stage, lifecycle-based framework to bridge the reality gap between model-centric performance metrics and AI's materialized outcomes in deployment. While existing frameworks like MLOps focus on system stability and benchmarks measure abstract capabilities, decision-makers outside the AI stack lack systematic evidence about the behavior of AI technologies under real-world user variability and constraints. CIRCLE operationalizes the Validation phase of TEVV (Test, Evaluation, Verification, and Validation) by formalizing the translation of stakeholder concerns outside the stack into measurable signals. Unlike participatory design, which often remains localized, or algorithmic audits, which are often retrospective, CIRCLE provides a structured, prospective protocol for linking context-sensitive qualitative insights to scalable quantitative metrics. By integrating methods such as field testing, red teaming, and longitudinal studies into a coordinated pipeline, CIRCLE produces systematic knowledge: evidence that is comparable across sites yet sensitive to local context. This can enable governance based on materialized downstream effects rather than theoretical capabilities.
Reality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects
May 24, 2025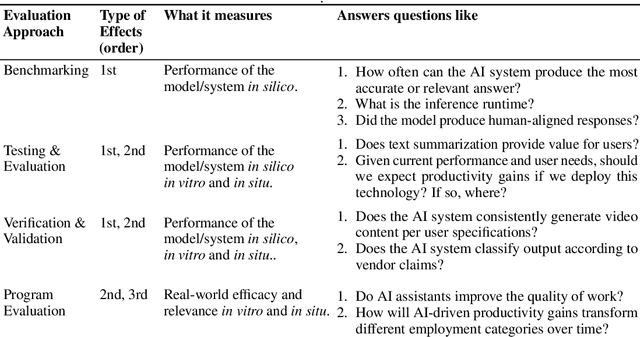
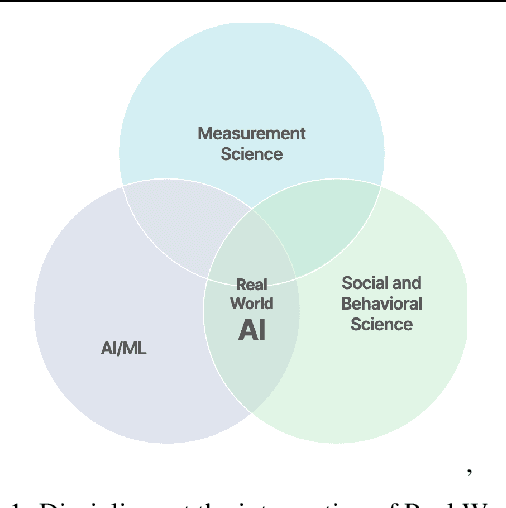

Conventional AI evaluation approaches concentrated within the AI stack exhibit systemic limitations for exploring, navigating and resolving the human and societal factors that play out in real world deployment such as in education, finance, healthcare, and employment sectors. AI capability evaluations can capture detail about first-order effects, such as whether immediate system outputs are accurate, or contain toxic, biased or stereotypical content, but AI's second-order effects, i.e. any long-term outcomes and consequences that may result from AI use in the real world, have become a significant area of interest as the technology becomes embedded in our daily lives. These secondary effects can include shifts in user behavior, societal, cultural and economic ramifications, workforce transformations, and long-term downstream impacts that may result from a broad and growing set of risks. This position paper argues that measuring the indirect and secondary effects of AI will require expansion beyond static, single-turn approaches conducted in silico to include testing paradigms that can capture what actually materializes when people use AI technology in context. Specifically, we describe the need for data and methods that can facilitate contextual awareness and enable downstream interpretation and decision making about AI's secondary effects, and recommend requirements for a new ecosystem.
Pre-trained Speech Processing Models Contain Human-Like Biases that Propagate to Speech Emotion Recognition
Oct 29, 2023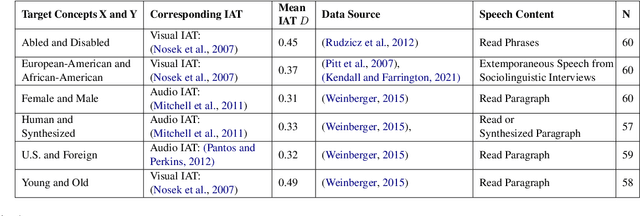
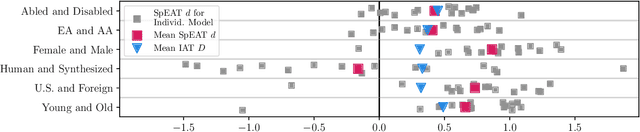
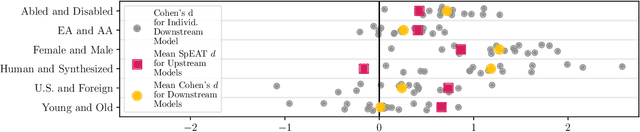
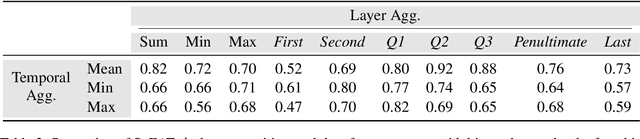
Previous work has established that a person's demographics and speech style affect how well speech processing models perform for them. But where does this bias come from? In this work, we present the Speech Embedding Association Test (SpEAT), a method for detecting bias in one type of model used for many speech tasks: pre-trained models. The SpEAT is inspired by word embedding association tests in natural language processing, which quantify intrinsic bias in a model's representations of different concepts, such as race or valence (something's pleasantness or unpleasantness) and capture the extent to which a model trained on large-scale socio-cultural data has learned human-like biases. Using the SpEAT, we test for six types of bias in 16 English speech models (including 4 models also trained on multilingual data), which come from the wav2vec 2.0, HuBERT, WavLM, and Whisper model families. We find that 14 or more models reveal positive valence (pleasantness) associations with abled people over disabled people, with European-Americans over African-Americans, with females over males, with U.S. accented speakers over non-U.S. accented speakers, and with younger people over older people. Beyond establishing that pre-trained speech models contain these biases, we also show that they can have real world effects. We compare biases found in pre-trained models to biases in downstream models adapted to the task of Speech Emotion Recognition (SER) and find that in 66 of the 96 tests performed (69%), the group that is more associated with positive valence as indicated by the SpEAT also tends to be predicted as speaking with higher valence by the downstream model. Our work provides evidence that, like text and image-based models, pre-trained speech based-models frequently learn human-like biases. Our work also shows that bias found in pre-trained models can propagate to the downstream task of SER.
The Role of Individual User Differences in Interpretable and Explainable Machine Learning Systems
Sep 14, 2020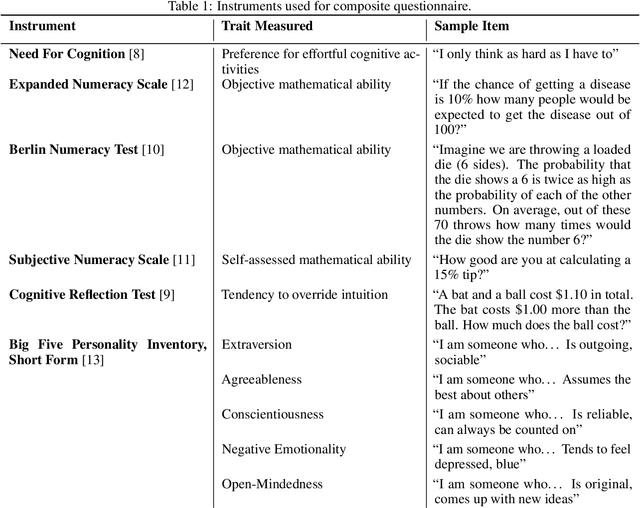
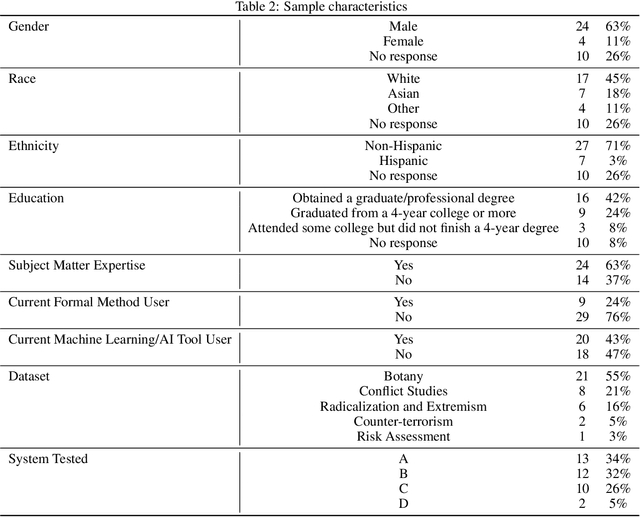
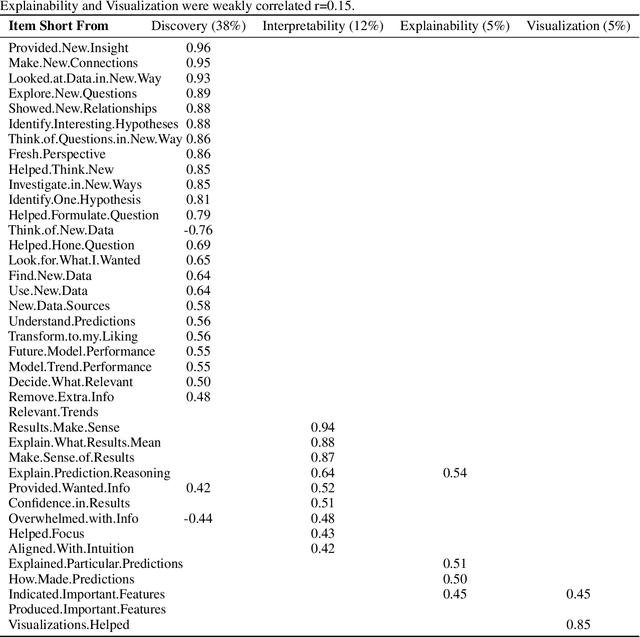

There is increased interest in assisting non-expert audiences to effectively interact with machine learning (ML) tools and understand the complex output such systems produce. Here, we describe user experiments designed to study how individual skills and personality traits predict interpretability, explainability, and knowledge discovery from ML generated model output. Our work relies on Fuzzy Trace Theory, a leading theory of how humans process numerical stimuli, to examine how different end users will interpret the output they receive while interacting with the ML system. While our sample was small, we found that interpretability -- being able to make sense of system output -- and explainability -- understanding how that output was generated -- were distinct aspects of user experience. Additionally, subjects were more able to interpret model output if they possessed individual traits that promote metacognitive monitoring and editing, associated with more detailed, verbatim, processing of ML output. Finally, subjects who are more familiar with ML systems felt better supported by them and more able to discover new patterns in data; however, this did not necessarily translate to meaningful insights. Our work motivates the design of systems that explicitly take users' mental representations into account during the design process to more effectively support end user requirements.