 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive detection of Influence Operations via Graph Learning
May 26, 2023

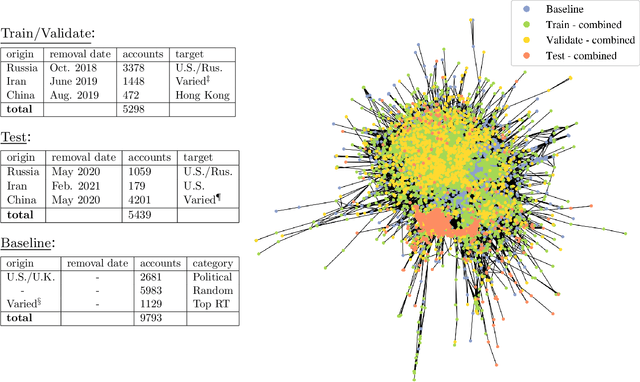

Influence operations are large-scale efforts to manipulate public opinion. The rapid detection and disruption of these operations is critical for healthy public discourse. Emergent AI technologies may enable novel operations which evade current detection methods and influence public discourse on social media with greater scale, reach, and specificity. New methods with inductive learning capacity will be needed to identify these novel operations before they indelibly alter public opinion and events. We develop an inductive learning framework which: 1) determines content- and graph-based indicators that are not specific to any operation; 2) uses graph learning to encode abstract signatures of coordinated manipulation; and 3) evaluates generalization capacity by training and testing models across operations originating from Russia, China, and Iran. We find that this framework enables strong cross-operation generalization while also revealing salient indicators$\unicode{x2013}$illustrating a generic approach which directly complements transductive methodologies, thereby enhancing detection coverage.
GisPy: A Tool for Measuring Gist Inference Score in Text
May 25, 2022



Decision making theories such as Fuzzy-Trace Theory (FTT) suggest that individuals tend to rely on gist, or bottom-line meaning, in the text when making decisions. In this work, we delineate the process of developing GisPy, an open-source tool in Python for measuring the Gist Inference Score (GIS) in text. Evaluation of GisPy on documents in three benchmarks from the news and scientific text domains demonstrates that scores generated by our tool significantly distinguish low vs. high gist documents. Our tool is publicly available to use at: https://github.com/phosseini/GisPy.
Applying Word Embeddings to Measure Valence in Information Operations Targeting Journalists in Brazil
Jan 06, 2022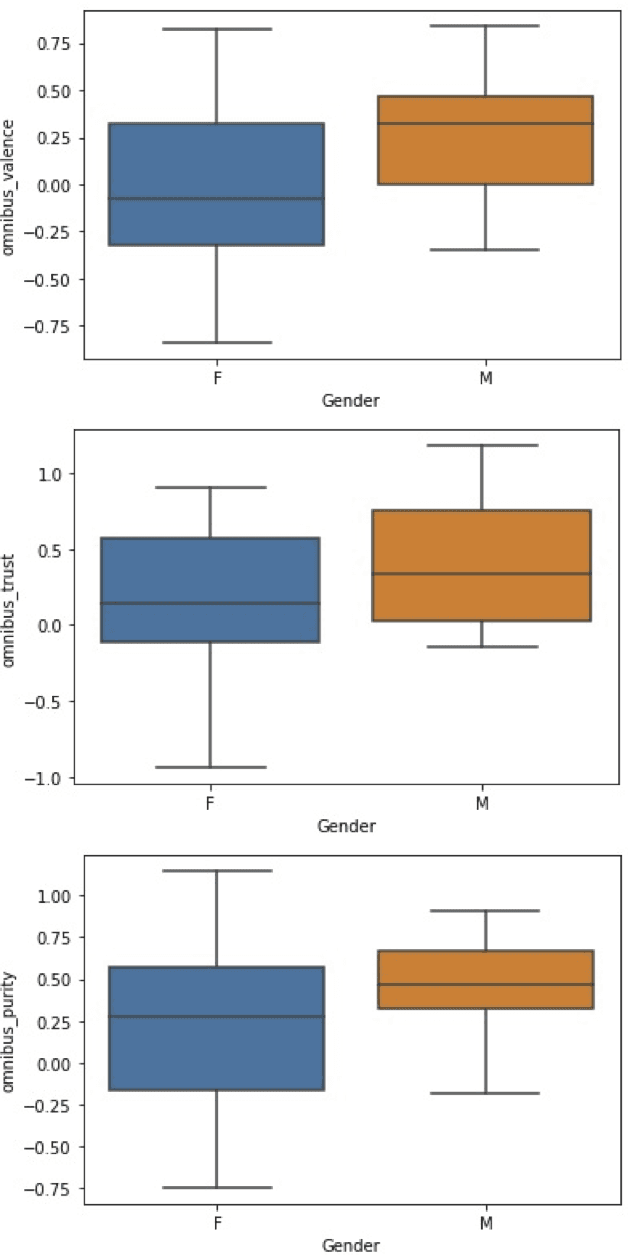
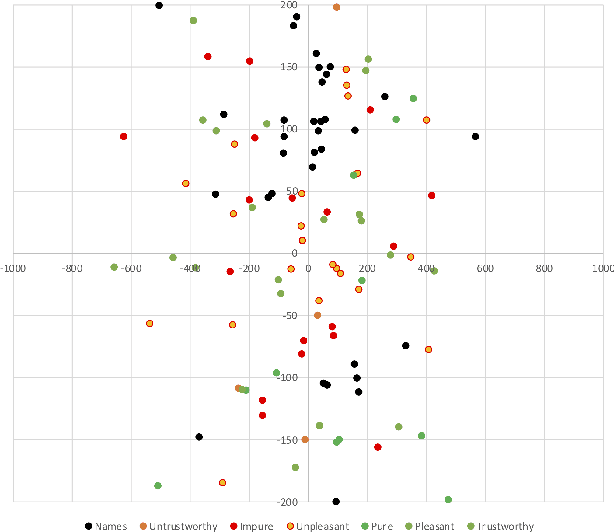
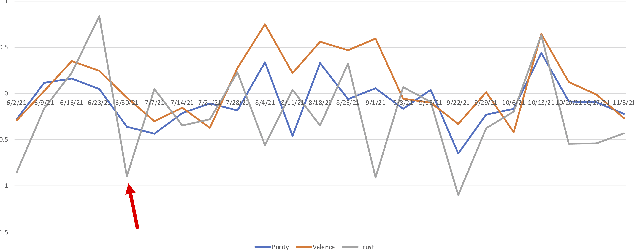
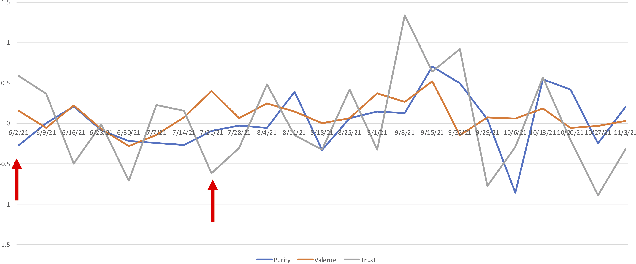
Among the goals of information operations are to change the overall information environment vis-\'a-vis specific actors. For example, "trolling campaigns" seek to undermine the credibility of specific public figures, leading others to distrust them and intimidating these figures into silence. To accomplish these aims, information operations frequently make use of "trolls" -- malicious online actors who target verbal abuse at these figures. In Brazil, in particular, allies of Brazil's current president have been accused of operating a "hate cabinet" -- a trolling operation that targets journalists who have alleged corruption by this politician and other members of his regime. Leading approaches to detecting harmful speech, such as Google's Perspective API, seek to identify specific messages with harmful content. While this approach is helpful in identifying content to downrank, flag, or remove, it is known to be brittle, and may miss attempts to introduce more subtle biases into the discourse. Here, we aim to develop a measure that might be used to assess how targeted information operations seek to change the overall valence, or appraisal, of specific actors. Preliminary results suggest known campaigns target female journalists more so than male journalists, and that these campaigns may leave detectable traces in overall Twitter discourse.
Commonsense Knowledge-Augmented Pretrained Language Models for Causal Reasoning Classification
Dec 16, 2021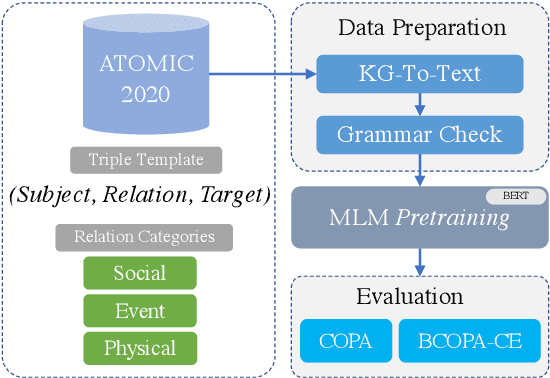
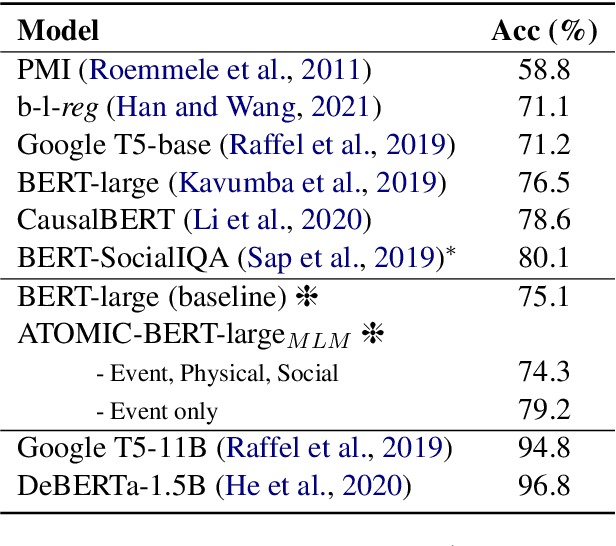
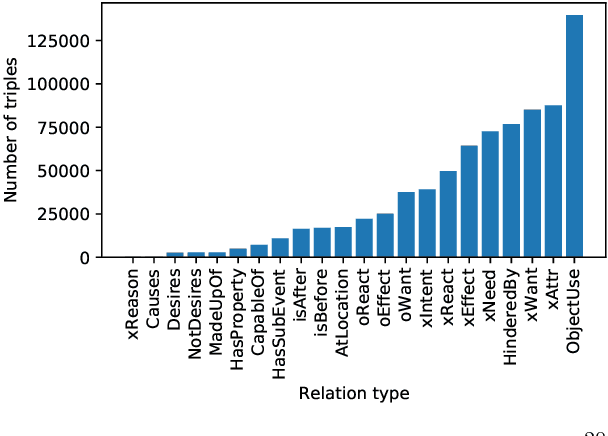
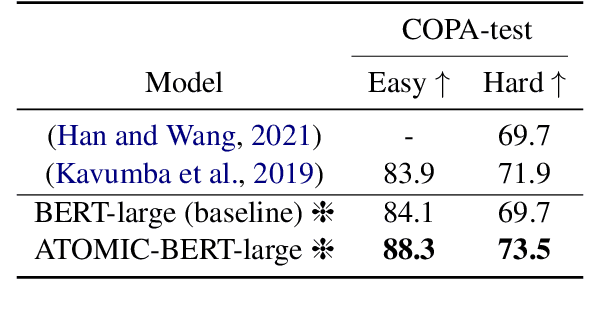
Commonsense knowledge can be leveraged for identifying causal relations in text. In this work, we verbalize triples in ATOMIC2020, a wide coverage commonsense reasoning knowledge graph, to natural language text and continually pretrain a BERT pretrained language model. We evaluate the resulting model on answering commonsense reasoning questions. Our results show that a continually pretrained language model augmented with commonsense reasoning knowledge outperforms our baseline on two commonsense causal reasoning benchmarks, COPA and BCOPA-CE, without additional improvement on the base model or using quality-enhanced data for fine-tuning.
Predicting Directionality in Causal Relations in Text
Mar 25, 2021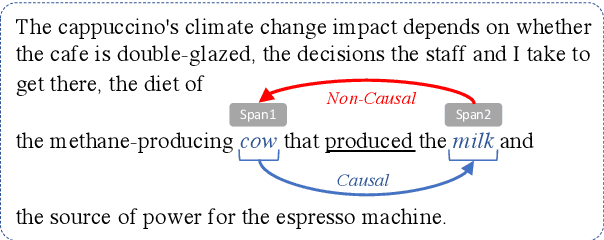
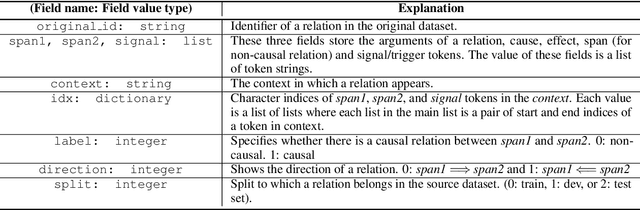
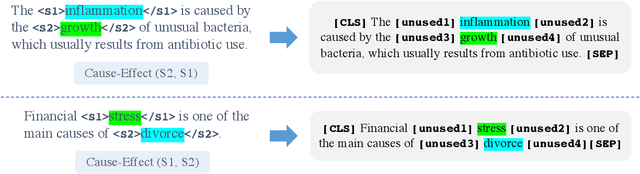
In this work, we test the performance of two bidirectional transformer-based language models, BERT and SpanBERT, on predicting directionality in causal pairs in the textual content. Our preliminary results show that predicting direction for inter-sentence and implicit causal relations is more challenging. And, SpanBERT performs better than BERT on causal samples with longer span length. We also introduce CREST which is a framework for unifying a collection of scattered datasets of causal relations.
A Multi-Modal Method for Satire Detection using Textual and Visual Cues
Oct 13, 2020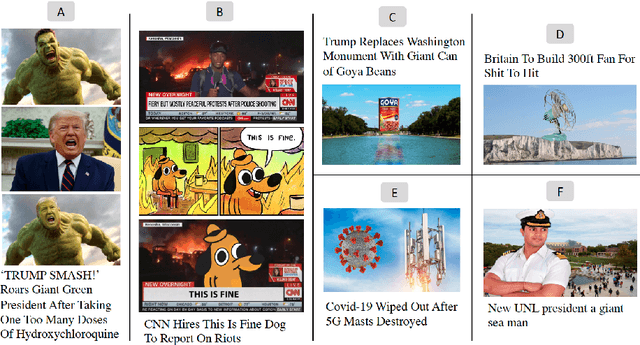
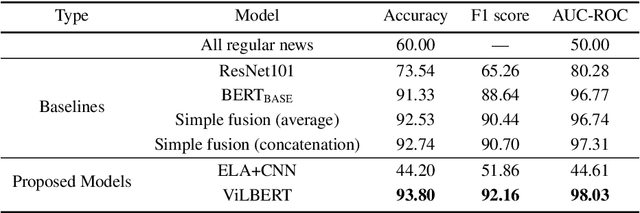

Satire is a form of humorous critique, but it is sometimes misinterpreted by readers as legitimate news, which can lead to harmful consequences. We observe that the images used in satirical news articles often contain absurd or ridiculous content and that image manipulation is used to create fictional scenarios. While previous work have studied text-based methods, in this work we propose a multi-modal approach based on state-of-the-art visiolinguistic model ViLBERT. To this end, we create a new dataset consisting of images and headlines of regular and satirical news for the task of satire detection. We fine-tune ViLBERT on the dataset and train a convolutional neural network that uses an image forensics technique. Evaluation on the dataset shows that our proposed multi-modal approach outperforms image-only, text-only, and simple fusion baselines.
The Role of Individual User Differences in Interpretable and Explainable Machine Learning Systems
Sep 14, 2020
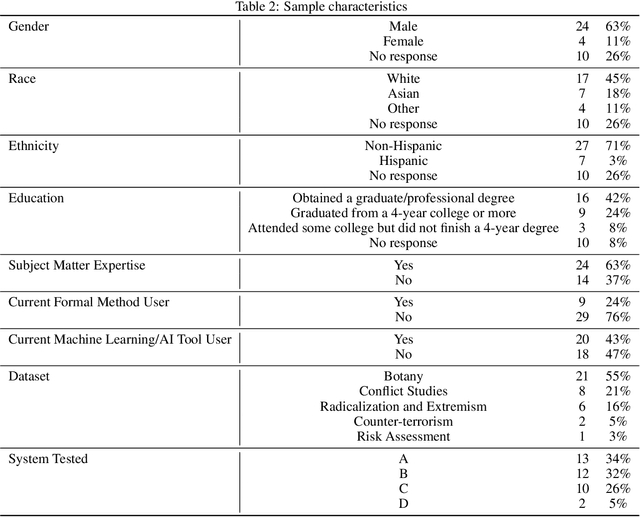
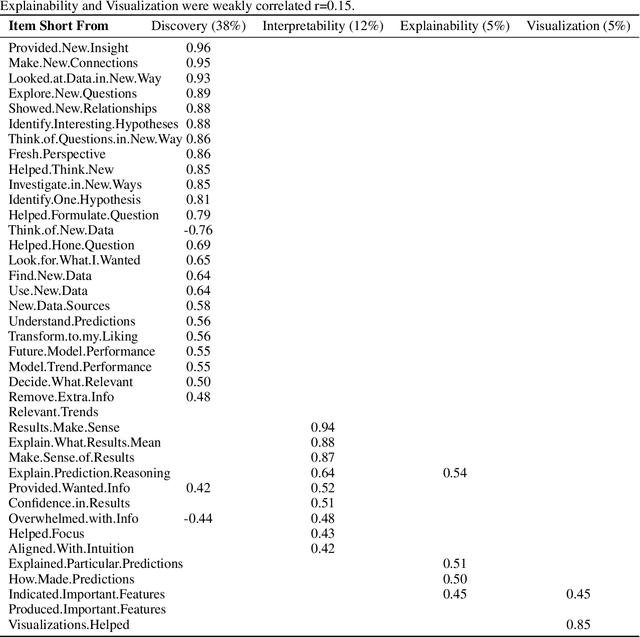

There is increased interest in assisting non-expert audiences to effectively interact with machine learning (ML) tools and understand the complex output such systems produce. Here, we describe user experiments designed to study how individual skills and personality traits predict interpretability, explainability, and knowledge discovery from ML generated model output. Our work relies on Fuzzy Trace Theory, a leading theory of how humans process numerical stimuli, to examine how different end users will interpret the output they receive while interacting with the ML system. While our sample was small, we found that interpretability -- being able to make sense of system output -- and explainability -- understanding how that output was generated -- were distinct aspects of user experience. Additionally, subjects were more able to interpret model output if they possessed individual traits that promote metacognitive monitoring and editing, associated with more detailed, verbatim, processing of ML output. Finally, subjects who are more familiar with ML systems felt better supported by them and more able to discover new patterns in data; however, this did not necessarily translate to meaningful insights. Our work motivates the design of systems that explicitly take users' mental representations into account during the design process to more effectively support end user requirements.
Content analysis of Persian/Farsi Tweets during COVID-19 pandemic in Iran using NLP
May 17, 2020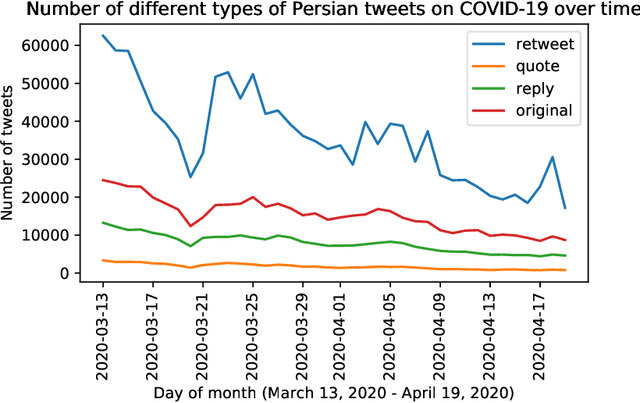
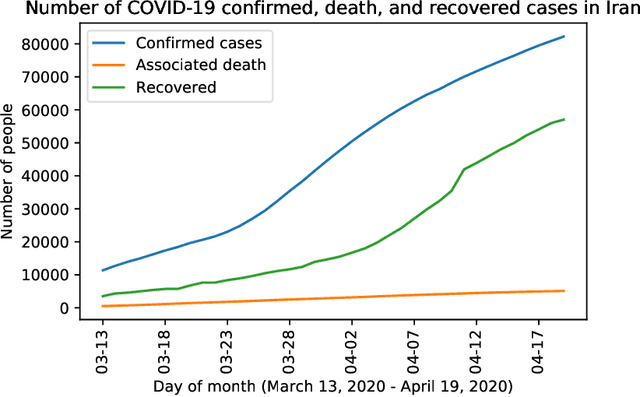


Iran, along with China, South Korea, and Italy was among the countries that were hit hard in the first wave of the COVID-19 spread. Twitter is one of the widely-used online platforms by Iranians inside and abroad for sharing their opinion, thoughts, and feelings about a wide range of issues. In this study, using more than 530,000 original tweets in Persian/Farsi on COVID-19, we analyzed the topics discussed among users, who are mainly Iranians, to gauge and track the response to the pandemic and how it evolved over time. We applied a combination of manual annotation of a random sample of tweets and topic modeling tools to classify the contents and frequency of each category of topics. We identified the top 25 topics among which living experience under home quarantine emerged as a major talking point. We additionally categorized broader content of tweets that shows satire, followed by news, is the dominant tweet type among the Iranian users. While this framework and methodology can be used to track public response to ongoing developments related to COVID-19, a generalization of this framework can become a useful framework to gauge Iranian public reaction to ongoing policy measures or events locally and internationally.
Identifying Nuances in Fake News vs. Satire: Using Semantic and Linguistic Cues
Nov 05, 2019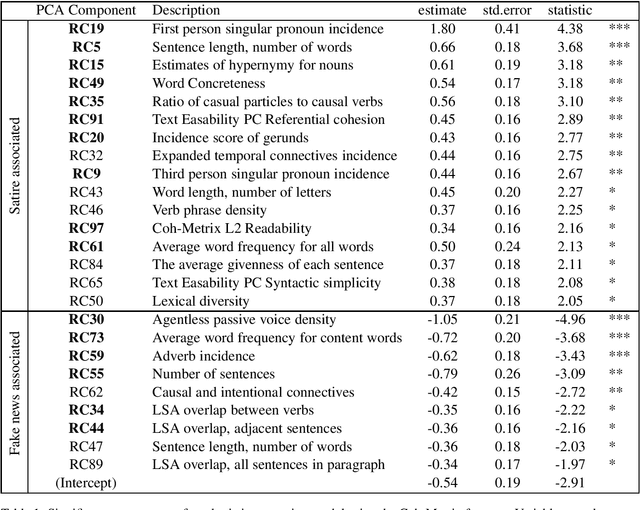
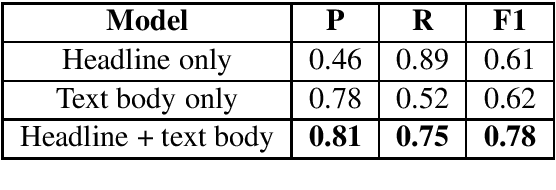
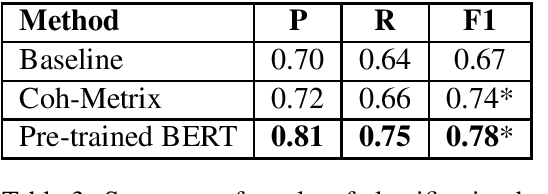
The blurry line between nefarious fake news and protected-speech satire has been a notorious struggle for social media platforms. Further to the efforts of reducing exposure to misinformation on social media, purveyors of fake news have begun to masquerade as satire sites to avoid being demoted. In this work, we address the challenge of automatically classifying fake news versus satire. Previous work have studied whether fake news and satire can be distinguished based on language differences. Contrary to fake news, satire stories are usually humorous and carry some political or social message. We hypothesize that these nuances could be identified using semantic and linguistic cues. Consequently, we train a machine learning method using semantic representation, with a state-of-the-art contextual language model, and with linguistic features based on textual coherence metrics. Empirical evaluation attests to the merits of our approach compared to the language-based baseline and sheds light on the nuances between fake news and satire. As avenues for future work, we consider studying additional linguistic features related to the humor aspect, and enriching the data with current news events, to help identify a political or social message.