 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation
Jul 02, 2025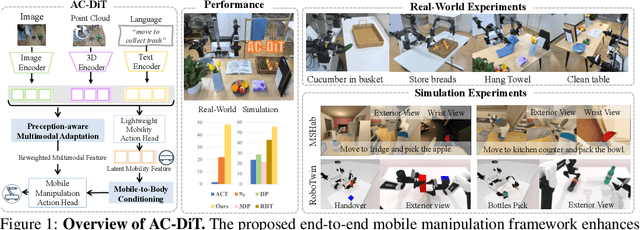
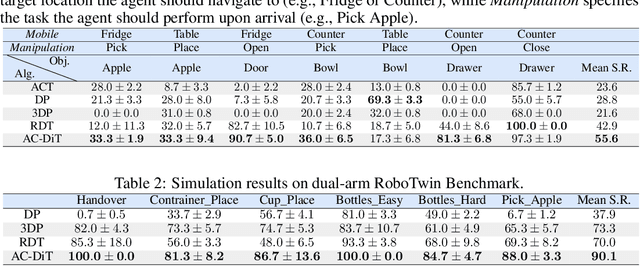
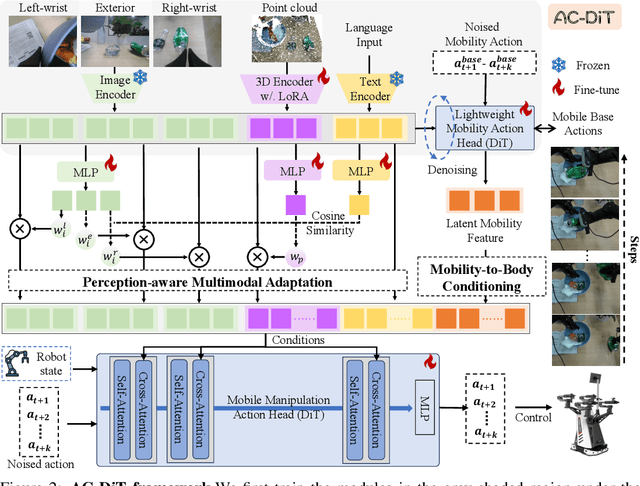

Recently, mobile manipulation has attracted increasing attention for enabling language-conditioned robotic control in household tasks. However, existing methods still face challenges in coordinating mobile base and manipulator, primarily due to two limitations. On the one hand, they fail to explicitly model the influence of the mobile base on manipulator control, which easily leads to error accumulation under high degrees of freedom. On the other hand, they treat the entire mobile manipulation process with the same visual observation modality (e.g., either all 2D or all 3D), overlooking the distinct multimodal perception requirements at different stages during mobile manipulation. To address this, we propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. First, since the motion of the mobile base directly influences the manipulator's actions, we introduce a mobility-to-body conditioning mechanism that guides the model to first extract base motion representations, which are then used as context prior for predicting whole-body actions. This enables whole-body control that accounts for the potential impact of the mobile base's motion. Second, to meet the perception requirements at different stages of mobile manipulation, we design a perception-aware multimodal conditioning strategy that dynamically adjusts the fusion weights between various 2D visual images and 3D point clouds, yielding visual features tailored to the current perceptual needs. This allows the model to, for example, adaptively rely more on 2D inputs when semantic information is crucial for action prediction, while placing greater emphasis on 3D geometric information when precise spatial understanding is required. We validate AC-DiT through extensive experiments on both simulated and real-world mobile manipulation tasks.
Bayesian Optimization of Antibodies Informed by a Generative Model of Evolving Sequences
Dec 10, 2024To build effective therapeutics, biologists iteratively mutate antibody sequences to improve binding and stability. Proposed mutations can be informed by previous measurements or by learning from large antibody databases to predict only typical antibodies. Unfortunately, the space of typical antibodies is enormous to search, and experiments often fail to find suitable antibodies on a budget. We introduce Clone-informed Bayesian Optimization (CloneBO), a Bayesian optimization procedure that efficiently optimizes antibodies in the lab by teaching a generative model how our immune system optimizes antibodies. Our immune system makes antibodies by iteratively evolving specific portions of their sequences to bind their target strongly and stably, resulting in a set of related, evolving sequences known as a clonal family. We train a large language model, CloneLM, on hundreds of thousands of clonal families and use it to design sequences with mutations that are most likely to optimize an antibody within the human immune system. We propose to guide our designs to fit previous measurements with a twisted sequential Monte Carlo procedure. We show that CloneBO optimizes antibodies substantially more efficiently than previous methods in realistic in silico experiments and designs stronger and more stable binders in in vitro wet lab experiments.
A Multi-Modal Method for Satire Detection using Textual and Visual Cues
Oct 13, 2020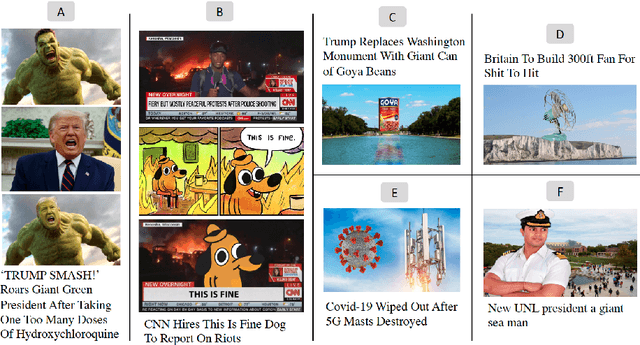
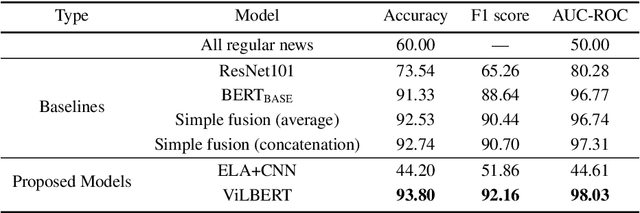

Satire is a form of humorous critique, but it is sometimes misinterpreted by readers as legitimate news, which can lead to harmful consequences. We observe that the images used in satirical news articles often contain absurd or ridiculous content and that image manipulation is used to create fictional scenarios. While previous work have studied text-based methods, in this work we propose a multi-modal approach based on state-of-the-art visiolinguistic model ViLBERT. To this end, we create a new dataset consisting of images and headlines of regular and satirical news for the task of satire detection. We fine-tune ViLBERT on the dataset and train a convolutional neural network that uses an image forensics technique. Evaluation on the dataset shows that our proposed multi-modal approach outperforms image-only, text-only, and simple fusion baselines.