 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation
Jul 02, 2025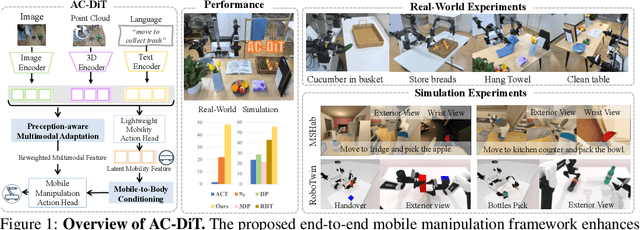
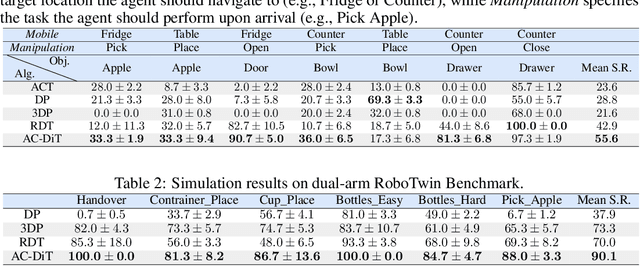
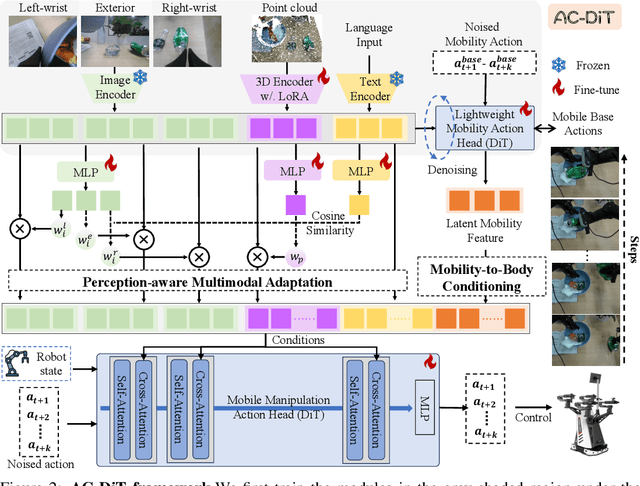

Recently, mobile manipulation has attracted increasing attention for enabling language-conditioned robotic control in household tasks. However, existing methods still face challenges in coordinating mobile base and manipulator, primarily due to two limitations. On the one hand, they fail to explicitly model the influence of the mobile base on manipulator control, which easily leads to error accumulation under high degrees of freedom. On the other hand, they treat the entire mobile manipulation process with the same visual observation modality (e.g., either all 2D or all 3D), overlooking the distinct multimodal perception requirements at different stages during mobile manipulation. To address this, we propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. First, since the motion of the mobile base directly influences the manipulator's actions, we introduce a mobility-to-body conditioning mechanism that guides the model to first extract base motion representations, which are then used as context prior for predicting whole-body actions. This enables whole-body control that accounts for the potential impact of the mobile base's motion. Second, to meet the perception requirements at different stages of mobile manipulation, we design a perception-aware multimodal conditioning strategy that dynamically adjusts the fusion weights between various 2D visual images and 3D point clouds, yielding visual features tailored to the current perceptual needs. This allows the model to, for example, adaptively rely more on 2D inputs when semantic information is crucial for action prediction, while placing greater emphasis on 3D geometric information when precise spatial understanding is required. We validate AC-DiT through extensive experiments on both simulated and real-world mobile manipulation tasks.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024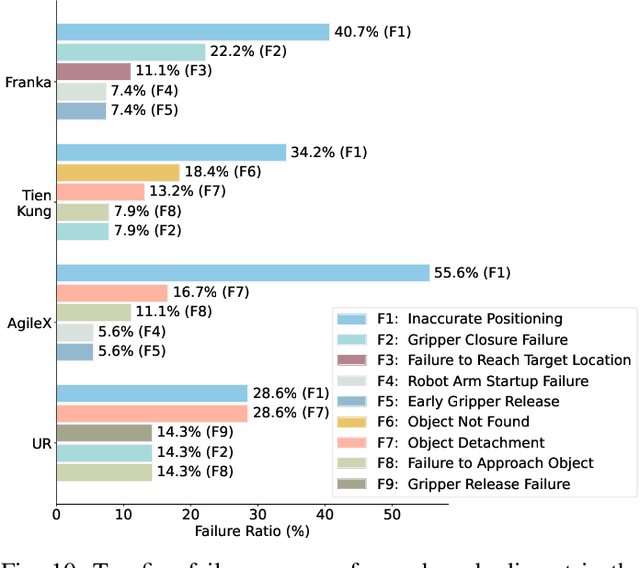
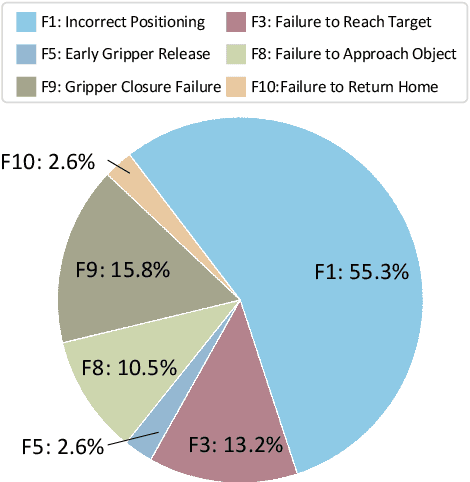
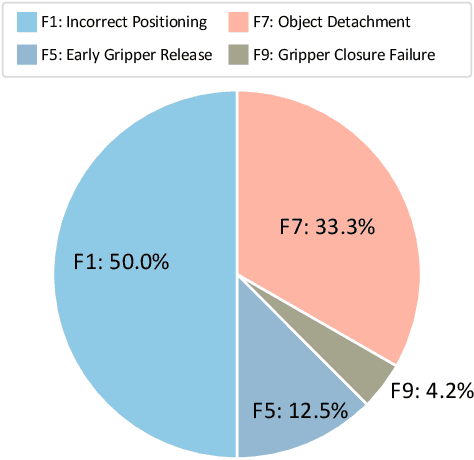
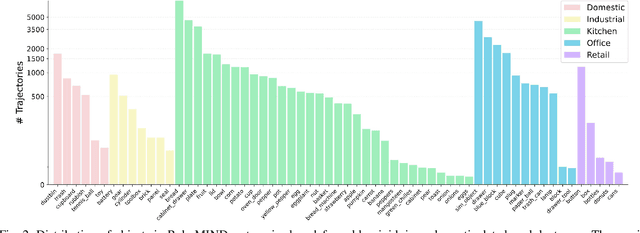
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
Chain of Thought Prompt Tuning in Vision Language Models
Apr 16, 2023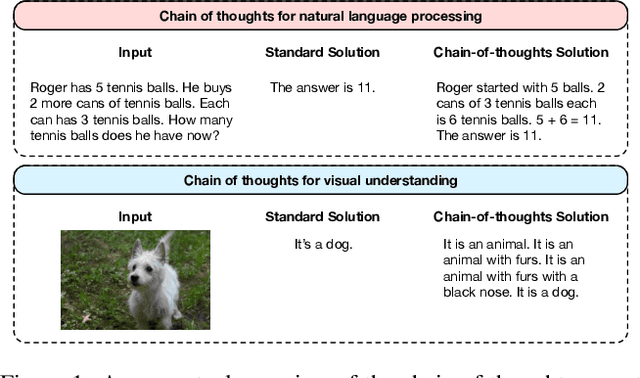
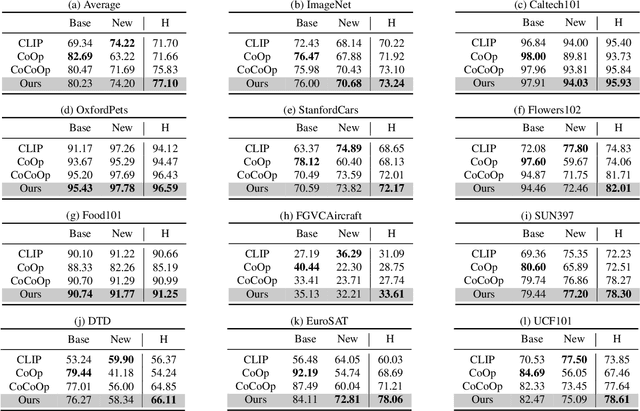
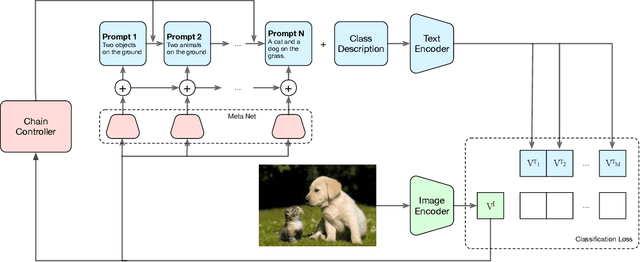
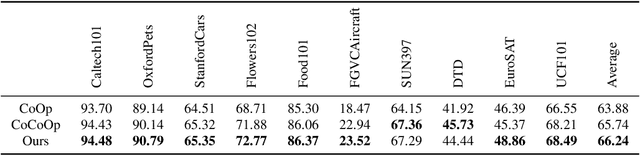
Language-Image Pre-training has demonstrated promising results on zero-shot and few-shot downstream tasks by prompting visual models with natural language prompts. However, most recent studies only use a single prompt for tuning, neglecting the inherent step-to-step cognitive reasoning process that humans conduct in complex task settings, for example, when processing images from unfamiliar domains. Chain of Thought is a simple and effective approximation to human reasoning process and has been proven useful for natural language processing (NLP) tasks. Based on this cognitive intuition, we believe that conducting effective reasoning is also an important problem in visual tasks, and a chain of thought could be a solution to this problem. In this work, we propose a novel chain of thought prompt tuning for vision-language modeling. Extensive experiments show that our method not only generalizes better in image classification tasks, has greater transferability beyond a single dataset, and has stronger domain generalization performance, but also performs much better in imagetext retrieval and visual question answering, which require more reasoning capabilities. We are the first to successfully adapt chain-of-thought prompting that combines visual and textual embeddings. We will release our codes