 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Thought Prompt Tuning in Vision Language Models
Paper and Code
Apr 16, 2023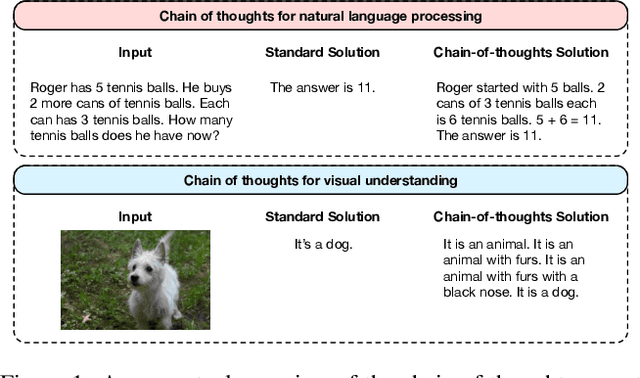
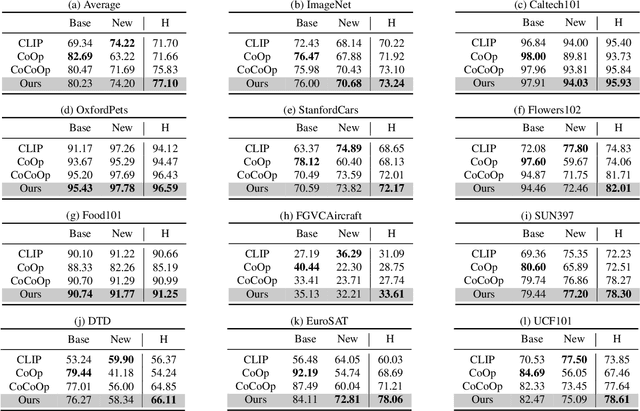
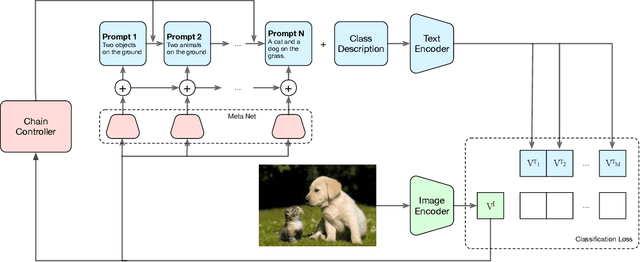
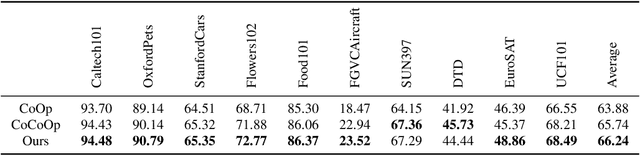
Language-Image Pre-training has demonstrated promising results on zero-shot and few-shot downstream tasks by prompting visual models with natural language prompts. However, most recent studies only use a single prompt for tuning, neglecting the inherent step-to-step cognitive reasoning process that humans conduct in complex task settings, for example, when processing images from unfamiliar domains. Chain of Thought is a simple and effective approximation to human reasoning process and has been proven useful for natural language processing (NLP) tasks. Based on this cognitive intuition, we believe that conducting effective reasoning is also an important problem in visual tasks, and a chain of thought could be a solution to this problem. In this work, we propose a novel chain of thought prompt tuning for vision-language modeling. Extensive experiments show that our method not only generalizes better in image classification tasks, has greater transferability beyond a single dataset, and has stronger domain generalization performance, but also performs much better in imagetext retrieval and visual question answering, which require more reasoning capabilities. We are the first to successfully adapt chain-of-thought prompting that combines visual and textual embeddings. We will release our codes