 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Jan 23, 2026Modern Vision-Language Models (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Jan 16, 2026Vision-as-inverse-graphics, the concept of reconstructing an image as an editable graphics program is a long-standing goal of computer vision. Yet even strong VLMs aren't able to achieve this in one-shot as they lack fine-grained spatial and physical grounding capability. Our key insight is that closing this gap requires interleaved multimodal reasoning through iterative execution and verification. Stemming from this, we present VIGA (Vision-as-Inverse-Graphic Agent) that starts from an empty world and reconstructs or edits scenes through a closed-loop write-run-render-compare-revise procedure. To support long-horizon reasoning, VIGA combines (i) a skill library that alternates generator and verifier roles and (ii) an evolving context memory that contains plans, code diffs, and render history. VIGA is task-agnostic as it doesn't require auxiliary modules, covering a wide range of tasks such as 3D reconstruction, multi-step scene editing, 4D physical interaction, and 2D document editing, etc. Empirically, we found VIGA substantially improves one-shot baselines on BlenderGym (35.32%) and SlideBench (117.17%). Moreover, VIGA is also model-agnostic as it doesn't require finetuning, enabling a unified protocol to evaluate heterogeneous foundation VLMs. To better support this protocol, we introduce BlenderBench, a challenging benchmark that stress-tests interleaved multimodal reasoning with graphics engine, where VIGA improves by 124.70%.
Puzzled by Puzzles: When Vision-Language Models Can't Take a Hint
May 29, 2025Rebus puzzles, visual riddles that encode language through imagery, spatial arrangement, and symbolic substitution, pose a unique challenge to current vision-language models (VLMs). Unlike traditional image captioning or question answering tasks, rebus solving requires multi-modal abstraction, symbolic reasoning, and a grasp of cultural, phonetic and linguistic puns. In this paper, we investigate the capacity of contemporary VLMs to interpret and solve rebus puzzles by constructing a hand-generated and annotated benchmark of diverse English-language rebus puzzles, ranging from simple pictographic substitutions to spatially-dependent cues ("head" over "heels"). We analyze how different VLMs perform, and our findings reveal that while VLMs exhibit some surprising capabilities in decoding simple visual clues, they struggle significantly with tasks requiring abstract reasoning, lateral thinking, and understanding visual metaphors.
Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling
Apr 17, 2025Vision-Language Models (VLMs) excel at visual understanding but often suffer from visual hallucinations, where they generate descriptions of nonexistent objects, actions, or concepts, posing significant risks in safety-critical applications. Existing hallucination mitigation methods typically follow one of two paradigms: generation adjustment, which modifies decoding behavior to align text with visual inputs, and post-hoc verification, where external models assess and correct outputs. While effective, generation adjustment methods often rely on heuristics and lack correction mechanisms, while post-hoc verification is complicated, typically requiring multiple models and tending to reject outputs rather than refine them. In this work, we introduce REVERSE, a unified framework that integrates hallucination-aware training with on-the-fly self-verification. By leveraging a new hallucination-verification dataset containing over 1.3M semi-synthetic samples, along with a novel inference-time retrospective resampling technique, our approach enables VLMs to both detect hallucinations during generation and dynamically revise those hallucinations. Our evaluations show that REVERSE achieves state-of-the-art hallucination reduction, outperforming the best existing methods by up to 12% on CHAIR-MSCOCO and 28% on HaloQuest. Our dataset, model, and code are available at: https://reverse-vlm.github.io.
EmpathyAgent: Can Embodied Agents Conduct Empathetic Actions?
Mar 19, 2025Empathy is fundamental to human interactions, yet it remains unclear whether embodied agents can provide human-like empathetic support. Existing works have studied agents' tasks solving and social interactions abilities, but whether agents can understand empathetic needs and conduct empathetic behaviors remains overlooked. To address this, we introduce EmpathyAgent, the first benchmark to evaluate and enhance agents' empathetic actions across diverse scenarios. EmpathyAgent contains 10,000 multimodal samples with corresponding empathetic task plans and three different challenges. To systematically evaluate the agents' empathetic actions, we propose an empathy-specific evaluation suite that evaluates the agents' empathy process. We benchmark current models and found that exhibiting empathetic actions remains a significant challenge. Meanwhile, we train Llama3-8B using EmpathyAgent and find it can potentially enhance empathetic behavior. By establishing a standard benchmark for evaluating empathetic actions, we hope to advance research in empathetic embodied agents. Our code and data are publicly available at https://github.com/xinyan-cxy/EmpathyAgent.
Enough Coin Flips Can Make LLMs Act Bayesian
Mar 06, 2025Large language models (LLMs) exhibit the ability to generalize given few-shot examples in their input prompt, an emergent capability known as in-context learning (ICL). We investigate whether LLMs utilize ICL to perform structured reasoning in ways that are consistent with a Bayesian framework or rely on pattern matching. Using a controlled setting of biased coin flips, we find that: (1) LLMs often possess biased priors, causing initial divergence in zero-shot settings, (2) in-context evidence outweighs explicit bias instructions, (3) LLMs broadly follow Bayesian posterior updates, with deviations primarily due to miscalibrated priors rather than flawed updates, and (4) attention magnitude has negligible effect on Bayesian inference. With sufficient demonstrations of biased coin flips via ICL, LLMs update their priors in a Bayesian manner.
AutoPresent: Designing Structured Visuals from Scratch
Jan 01, 2025
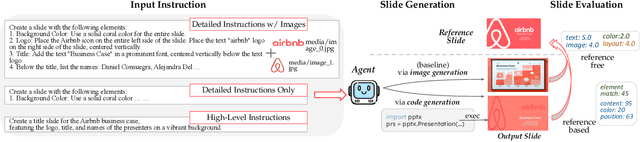
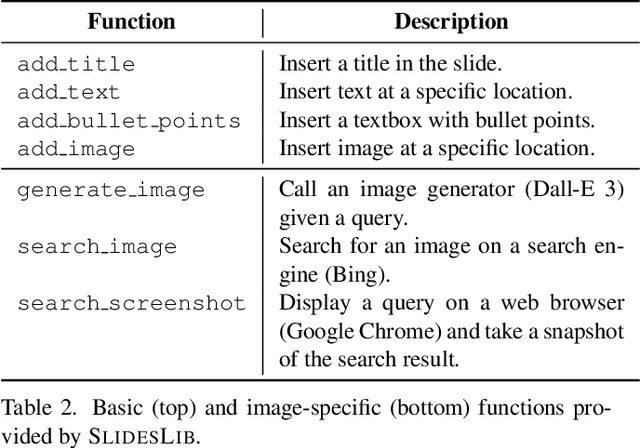
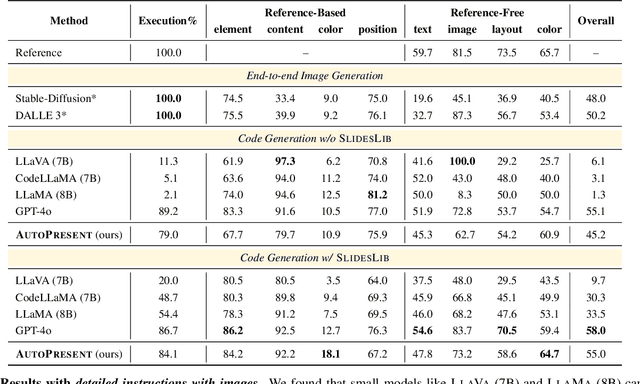
Designing structured visuals such as presentation slides is essential for communicative needs, necessitating both content creation and visual planning skills. In this work, we tackle the challenge of automated slide generation, where models produce slide presentations from natural language (NL) instructions. We first introduce the SlidesBench benchmark, the first benchmark for slide generation with 7k training and 585 testing examples derived from 310 slide decks across 10 domains. SlidesBench supports evaluations that are (i)reference-based to measure similarity to a target slide, and (ii)reference-free to measure the design quality of generated slides alone. We benchmark end-to-end image generation and program generation methods with a variety of models, and find that programmatic methods produce higher-quality slides in user-interactable formats. Built on the success of program generation, we create AutoPresent, an 8B Llama-based model trained on 7k pairs of instructions paired with code for slide generation, and achieve results comparable to the closed-source model GPT-4o. We further explore iterative design refinement where the model is tasked to self-refine its own output, and we found that this process improves the slide's quality. We hope that our work will provide a basis for future work on generating structured visuals.
Training Task Experts through Retrieval Based Distillation
Jul 07, 2024



One of the most reliable ways to create deployable models for specialized tasks is to obtain an adequate amount of high-quality task-specific data. However, for specialized tasks, often such datasets do not exist. Existing methods address this by creating such data from large language models (LLMs) and then distilling such knowledge into smaller models. However, these methods are limited by the quality of the LLMs output, and tend to generate repetitive or incorrect data. In this work, we present Retrieval Based Distillation (ReBase), a method that first retrieves data from rich online sources and then transforms them into domain-specific data. This method greatly enhances data diversity. Moreover, ReBase generates Chain-of-Thought reasoning and distills the reasoning capacity of LLMs. We test our method on 4 benchmarks and results show that our method significantly improves performance by up to 7.8% on SQuAD, 1.37% on MNLI, and 1.94% on BigBench-Hard.
Self-Corrected Multimodal Large Language Model for End-to-End Robot Manipulation
May 27, 2024



Robot manipulation policies have shown unsatisfactory action performance when confronted with novel task or object instances. Hence, the capability to automatically detect and self-correct failure action is essential for a practical robotic system. Recently, Multimodal Large Language Models (MLLMs) have shown promise in visual instruction following and demonstrated strong reasoning abilities in various tasks. To unleash general MLLMs as an end-to-end robotic agent, we introduce a Self-Corrected (SC)-MLLM, equipping our model not only to predict end-effector poses but also to autonomously recognize and correct failure actions. Specifically, we first conduct parameter-efficient fine-tuning to empower MLLM with pose prediction ability, which is reframed as a language modeling problem. When facing execution failures, our model learns to identify low-level action error causes (i.e., position and rotation errors) and adaptively seeks prompt feedback from experts. Based on the feedback, SC-MLLM rethinks the current failure scene and generates the corrected actions. Furthermore, we design a continuous policy learning method for successfully corrected samples, enhancing the model's adaptability to the current scene configuration and reducing the frequency of expert intervention. To evaluate our SC-MLLM, we conduct extensive experiments in both simulation and real-world settings. SC-MLLM agent significantly improve manipulation accuracy compared to previous state-of-the-art robotic MLLM (ManipLLM), increasing from 57\% to 79\% on seen object categories and from 47\% to 69\% on unseen novel categories.
Iterative Prompt Relabeling for diffusion model with RLDF
Dec 23, 2023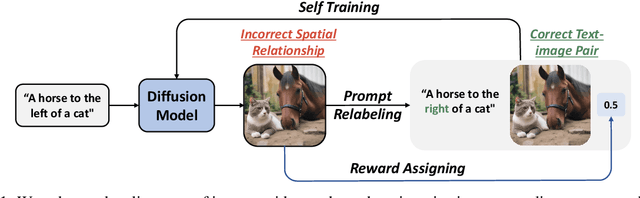
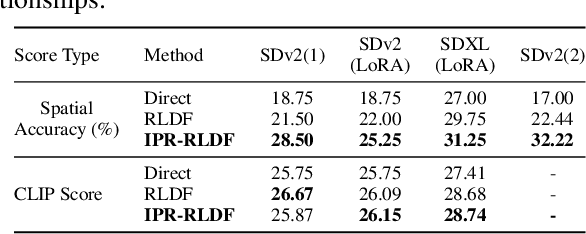
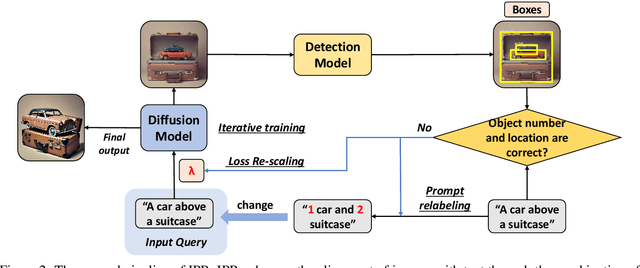

Diffusion models have shown impressive performance in many domains, including image generation, time series prediction, and reinforcement learning. The algorithm demonstrates superior performance over the traditional GAN and transformer based methods. However, the model's capability to follow natural language instructions (e.g., spatial relationships between objects, generating complex scenes) is still unsatisfactory. This has been an important research area to enhance such capability. Prior works adopt reinforcement learning to adjust the behavior of the diffusion models. However, RL methods not only require careful reward design and complex hyperparameter tuning, but also fails to incorporate rich natural language feedback. In this work, we propose iterative prompt relabeling (IP-RLDF), a novel algorithm that aligns images to text through iterative image sampling and prompt relabeling. IP-RLDF first samples a batch of images conditioned on the text, then relabels the text prompts of unmatched text-image pairs with classifier feedback. We conduct thorough experiments on three different models, including SDv2, GLIGEN, and SDXL, testing their capability to generate images following instructions. With IP-RLDF, we improved up to 15.22% (absolute improvement) on the challenging spatial relation VISOR benchmark, demonstrating superior performance compared to previous RL methods.