 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Biologically Plausible Temporal Credit Assignment Rules Match BPTT for Neural Similarity? E-prop as an Example
Jun 07, 2025Understanding how the brain learns may be informed by studying biologically plausible learning rules. These rules, often approximating gradient descent learning to respect biological constraints such as locality, must meet two critical criteria to be considered an appropriate brain model: (1) good neuroscience task performance and (2) alignment with neural recordings. While extensive research has assessed the first criterion, the second remains underexamined. Employing methods such as Procrustes analysis on well-known neuroscience datasets, this study demonstrates the existence of a biologically plausible learning rule -- namely e-prop, which is based on gradient truncation and has demonstrated versatility across a wide range of tasks -- that can achieve neural data similarity comparable to Backpropagation Through Time (BPTT) when matched for task accuracy. Our findings also reveal that model architecture and initial conditions can play a more significant role in determining neural similarity than the specific learning rule. Furthermore, we observe that BPTT-trained models and their biologically plausible counterparts exhibit similar dynamical properties at comparable accuracies. These results underscore the substantial progress made in developing biologically plausible learning rules, highlighting their potential to achieve both competitive task performance and neural data similarity.
Project Sid: Many-agent simulations toward AI civilization
Oct 31, 2024



AI agents have been evaluated in isolation or within small groups, where interactions remain limited in scope and complexity. Large-scale simulations involving many autonomous agents -- reflecting the full spectrum of civilizational processes -- have yet to be explored. Here, we demonstrate how 10 - 1000+ AI agents behave and progress within agent societies. We first introduce the PIANO (Parallel Information Aggregation via Neural Orchestration) architecture, which enables agents to interact with humans and other agents in real-time while maintaining coherence across multiple output streams. We then evaluate agent performance in agent simulations using civilizational benchmarks inspired by human history. These simulations, set within a Minecraft environment, reveal that agents are capable of meaningful progress -- autonomously developing specialized roles, adhering to and changing collective rules, and engaging in cultural and religious transmission. These preliminary results show that agents can achieve significant milestones towards AI civilizations, opening new avenues for large simulations, agentic organizational intelligence, and integrating AI into human civilizations.
A Framework for Standardizing Similarity Measures in a Rapidly Evolving Field
Sep 26, 2024Similarity measures are fundamental tools for quantifying the alignment between artificial and biological systems. However, the diversity of similarity measures and their varied naming and implementation conventions makes it challenging to compare across studies. To facilitate comparisons and make explicit the implementation choices underlying a given code package, we have created and are continuing to develop a Python repository that benchmarks and standardizes similarity measures. The goal of creating a consistent naming convention that uniquely and efficiently specifies a similarity measure is not trivial as, for example, even commonly used methods like Centered Kernel Alignment (CKA) have at least 12 different variations, and this number will likely continue to grow as the field evolves. For this reason, we do not advocate for a fixed, definitive naming convention. The landscape of similarity measures and best practices will continue to change and so we see our current repository, which incorporates approximately 100 different similarity measures from 14 packages, as providing a useful tool at this snapshot in time. To accommodate the evolution of the field we present a framework for developing, validating, and refining naming conventions with the goal of uniquely and efficiently specifying similarity measures, ultimately making it easier for the community to make comparisons across studies.
Gradient-based inference of abstract task representations for generalization in neural networks
Jul 24, 2024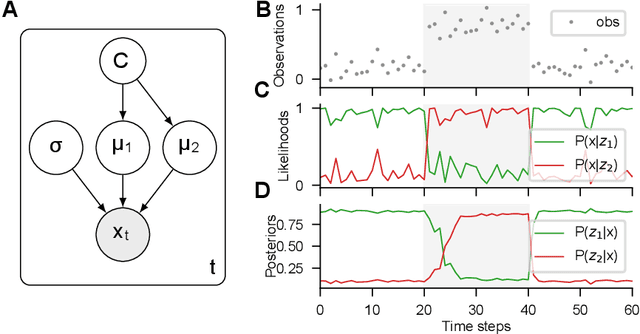



Humans and many animals show remarkably adaptive behavior and can respond differently to the same input depending on their internal goals. The brain not only represents the intermediate abstractions needed to perform a computation but also actively maintains a representation of the computation itself (task abstraction). Such separation of the computation and its abstraction is associated with faster learning, flexible decision-making, and broad generalization capacity. We investigate if such benefits might extend to neural networks trained with task abstractions. For such benefits to emerge, one needs a task inference mechanism that possesses two crucial abilities: First, the ability to infer abstract task representations when no longer explicitly provided (task inference), and second, manipulate task representations to adapt to novel problems (task recomposition). To tackle this, we cast task inference as an optimization problem from a variational inference perspective and ground our approach in an expectation-maximization framework. We show that gradients backpropagated through a neural network to a task representation layer are an efficient heuristic to infer current task demands, a process we refer to as gradient-based inference (GBI). Further iterative optimization of the task representation layer allows for recomposing abstractions to adapt to novel situations. Using a toy example, a novel image classifier, and a language model, we demonstrate that GBI provides higher learning efficiency and generalization to novel tasks and limits forgetting. Moreover, we show that GBI has unique advantages such as preserving information for uncertainty estimation and detecting out-of-distribution samples.
Differentiable Optimization of Similarity Scores Between Models and Brains
Jul 09, 2024What metrics should guide the development of more realistic models of the brain? One proposal is to quantify the similarity between models and brains using methods such as linear regression, Centered Kernel Alignment (CKA), and angular Procrustes distance. To better understand the limitations of these similarity measures we analyze neural activity recorded in five experiments on nonhuman primates, and optimize synthetic datasets to become more similar to these neural recordings. How similar can these synthetic datasets be to neural activity while failing to encode task relevant variables? We find that some measures like linear regression and CKA, differ from angular Procrustes, and yield high similarity scores even when task relevant variables cannot be linearly decoded from the synthetic datasets. Synthetic datasets optimized to maximize similarity scores initially learn the first principal component of the target dataset, but angular Procrustes captures higher variance dimensions much earlier than methods like linear regression and CKA. We show in both theory and simulations how these scores change when different principal components are perturbed. And finally, we jointly optimize multiple similarity scores to find their allowed ranges, and show that a high angular Procrustes similarity, for example, implies a high CKA score, but not the converse.
Lyfe Agents: Generative agents for low-cost real-time social interactions
Oct 03, 2023

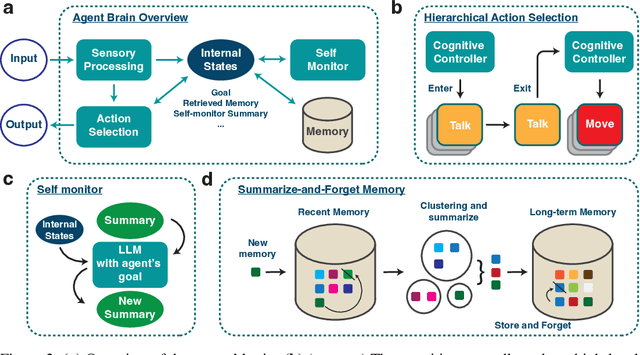
Highly autonomous generative agents powered by large language models promise to simulate intricate social behaviors in virtual societies. However, achieving real-time interactions with humans at a low computational cost remains challenging. Here, we introduce Lyfe Agents. They combine low-cost with real-time responsiveness, all while remaining intelligent and goal-oriented. Key innovations include: (1) an option-action framework, reducing the cost of high-level decisions; (2) asynchronous self-monitoring for better self-consistency; and (3) a Summarize-and-Forget memory mechanism, prioritizing critical memory items at a low cost. We evaluate Lyfe Agents' self-motivation and sociability across several multi-agent scenarios in our custom LyfeGame 3D virtual environment platform. When equipped with our brain-inspired techniques, Lyfe Agents can exhibit human-like self-motivated social reasoning. For example, the agents can solve a crime (a murder mystery) through autonomous collaboration and information exchange. Meanwhile, our techniques enabled Lyfe Agents to operate at a computational cost 10-100 times lower than existing alternatives. Our findings underscore the transformative potential of autonomous generative agents to enrich human social experiences in virtual worlds.
Dual policy as self-model for planning
Jun 11, 2023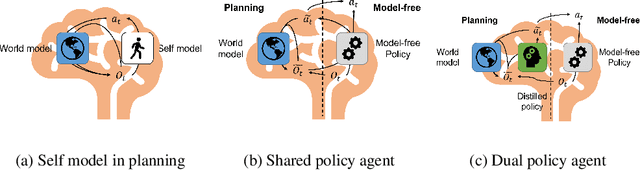

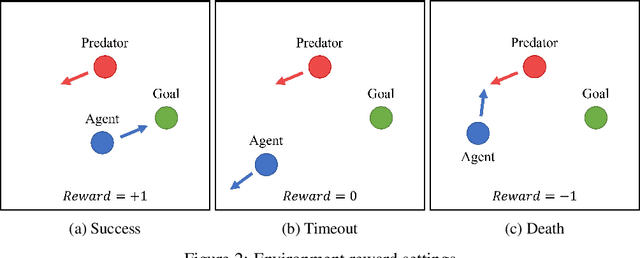
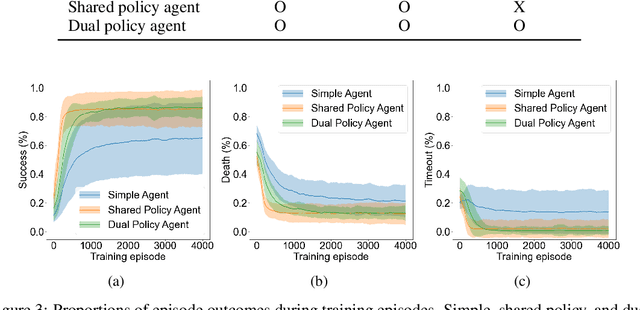
Planning is a data efficient decision-making strategy where an agent selects candidate actions by exploring possible future states. To simulate future states when there is a high-dimensional action space, the knowledge of one's decision making strategy must be used to limit the number of actions to be explored. We refer to the model used to simulate one's decisions as the agent's self-model. While self-models are implicitly used widely in conjunction with world models to plan actions, it remains unclear how self-models should be designed. Inspired by current reinforcement learning approaches and neuroscience, we explore the benefits and limitations of using a distilled policy network as the self-model. In such dual-policy agents, a model-free policy and a distilled policy are used for model-free actions and planned actions, respectively. Our results on a ecologically relevant, parametric environment indicate that distilled policy network for self-model stabilizes training, has faster inference than using model-free policy, promotes better exploration, and could learn a comprehensive understanding of its own behaviors, at the cost of distilling a new network apart from the model-free policy.
Neural Foundations of Mental Simulation: Future Prediction of Latent Representations on Dynamic Scenes
May 19, 2023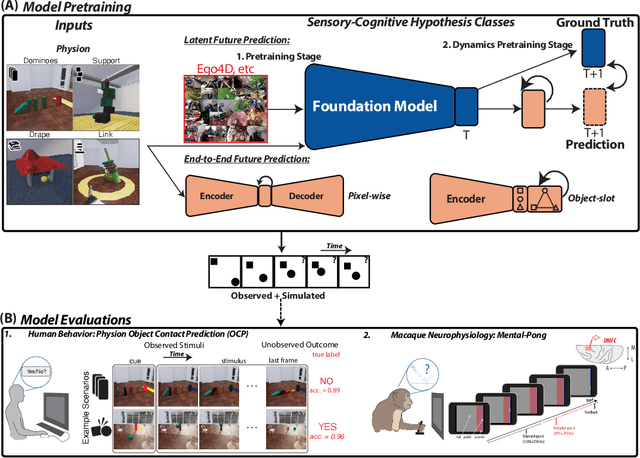
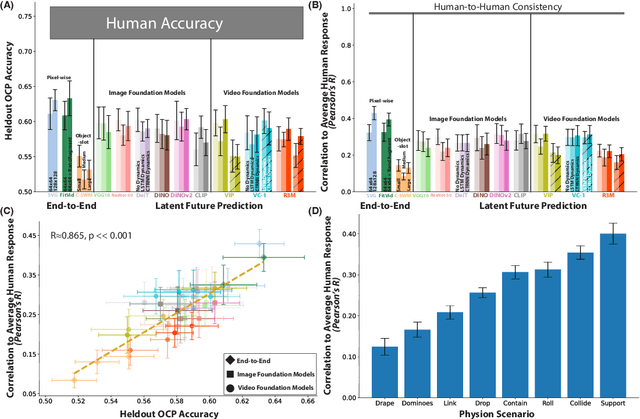
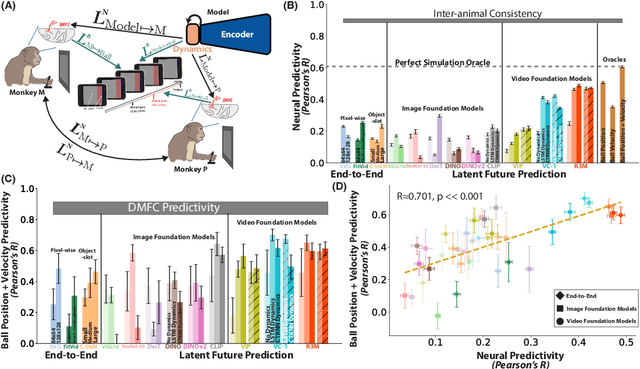
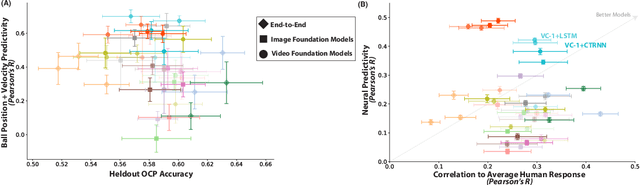
Humans and animals have a rich and flexible understanding of the physical world, which enables them to infer the underlying dynamical trajectories of objects and events, plausible future states, and use that to plan and anticipate the consequences of actions. However, the neural mechanisms underlying these computations are unclear. We combine a goal-driven modeling approach with dense neurophysiological data and high-throughput human behavioral readouts to directly impinge on this question. Specifically, we construct and evaluate several classes of sensory-cognitive networks to predict the future state of rich, ethologically-relevant environments, ranging from self-supervised end-to-end models with pixel-wise or object-centric objectives, to models that future predict in the latent space of purely static image-based or dynamic video-based pretrained foundation models. We find strong differentiation across these model classes in their ability to predict neural and behavioral data both within and across diverse environments. In particular, we find that neural responses are currently best predicted by models trained to predict the future state of their environment in the latent space of pretrained foundation models optimized for dynamic scenes in a self-supervised manner. Notably, models that future predict in the latent space of video foundation models that are optimized to support a diverse range of sensorimotor tasks, reasonably match both human behavioral error patterns and neural dynamics across all environmental scenarios that we were able to test. Overall, these findings suggest that the neural mechanisms and behaviors of primate mental simulation are thus far most consistent with being optimized to future predict on dynamic, reusable visual representations that are useful for embodied AI more generally.
Biological learning in key-value memory networks
Oct 26, 2021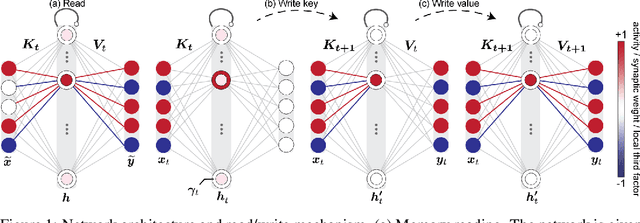


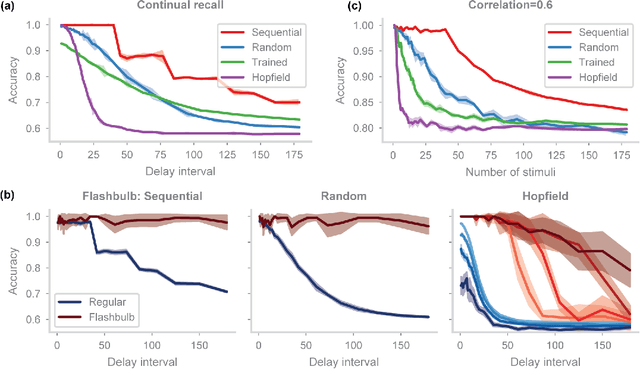
In neuroscience, classical Hopfield networks are the standard biologically plausible model of long-term memory, relying on Hebbian plasticity for storage and attractor dynamics for recall. In contrast, memory-augmented neural networks in machine learning commonly use a key-value mechanism to store and read out memories in a single step. Such augmented networks achieve impressive feats of memory compared to traditional variants, yet their biological relevance is unclear. We propose an implementation of basic key-value memory that stores inputs using a combination of biologically plausible three-factor plasticity rules. The same rules are recovered when network parameters are meta-learned. Our network performs on par with classical Hopfield networks on autoassociative memory tasks and can be naturally extended to continual recall, heteroassociative memory, and sequence learning. Our results suggest a compelling alternative to the classical Hopfield network as a model of biological long-term memory.
Artificial neural networks for neuroscientists: A primer
Jun 01, 2020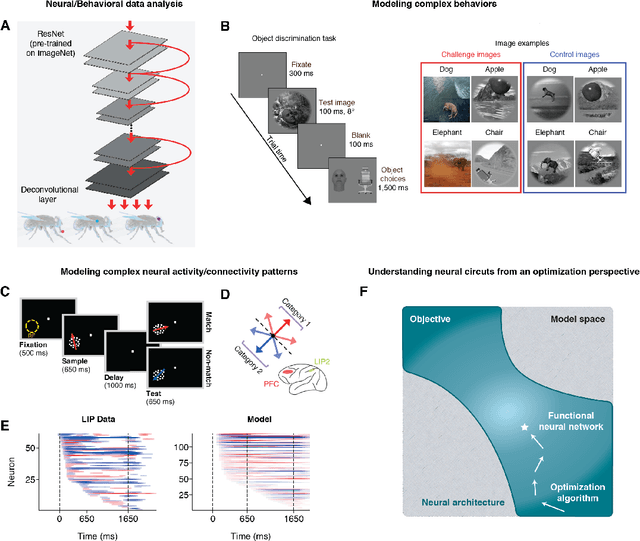
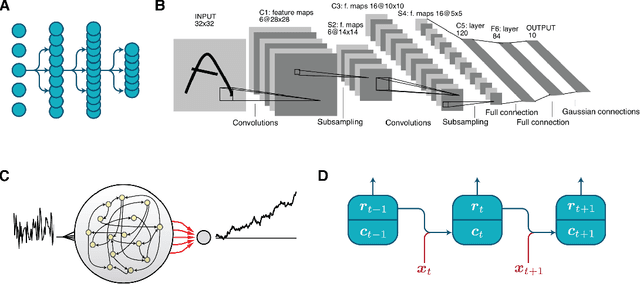
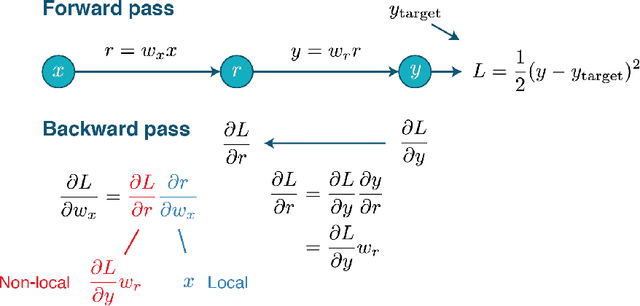
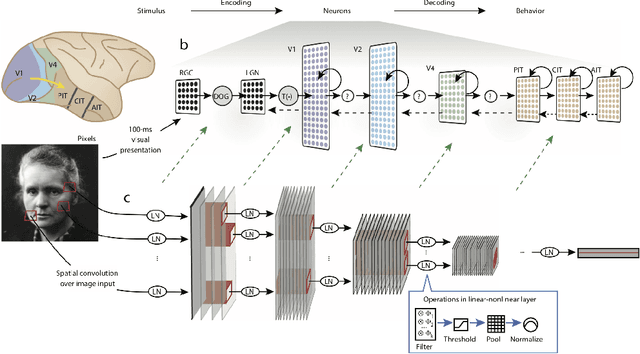
Artificial neural networks (ANNs) are essential tools in machine learning that are increasingly used for building computational models in neuroscience. Besides being powerful techniques for data analysis, ANNs provide a new approach for neuroscientists to build models that capture complex behaviors, neural activity and connectivity, as well as to explore optimization in neural systems. In this pedagogical Primer, we introduce conventional ANNs and demonstrate how they have been deployed to study neuroscience questions. Next, we detail how to customize the analysis, structure, and learning of ANNs to better address a wide range of challenges in brain research. To help the readers garner hands-on experience, this Primer is accompanied with tutorial-style code in PyTorch and Jupyter Notebook, covering major topics.