 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Sid: Many-agent simulations toward AI civilization
Oct 31, 2024



AI agents have been evaluated in isolation or within small groups, where interactions remain limited in scope and complexity. Large-scale simulations involving many autonomous agents -- reflecting the full spectrum of civilizational processes -- have yet to be explored. Here, we demonstrate how 10 - 1000+ AI agents behave and progress within agent societies. We first introduce the PIANO (Parallel Information Aggregation via Neural Orchestration) architecture, which enables agents to interact with humans and other agents in real-time while maintaining coherence across multiple output streams. We then evaluate agent performance in agent simulations using civilizational benchmarks inspired by human history. These simulations, set within a Minecraft environment, reveal that agents are capable of meaningful progress -- autonomously developing specialized roles, adhering to and changing collective rules, and engaging in cultural and religious transmission. These preliminary results show that agents can achieve significant milestones towards AI civilizations, opening new avenues for large simulations, agentic organizational intelligence, and integrating AI into human civilizations.
How many degrees of freedom do we need to train deep networks: a loss landscape perspective
Jul 13, 2021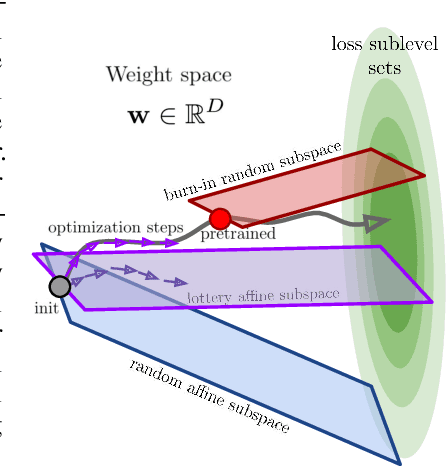
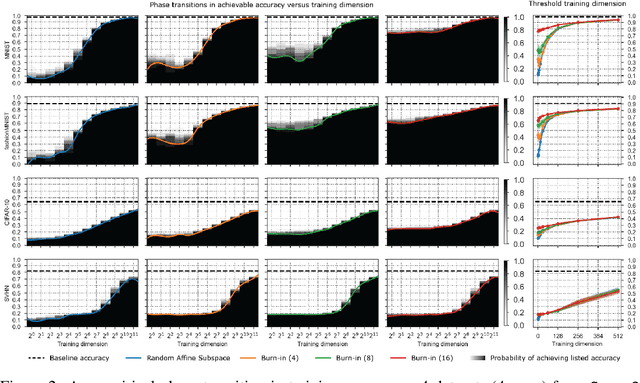
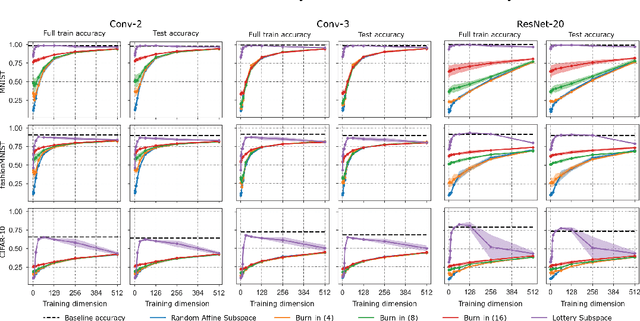
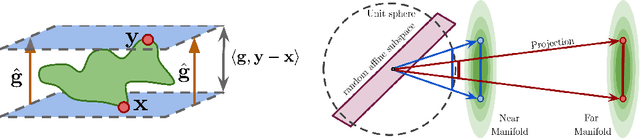
A variety of recent works, spanning pruning, lottery tickets, and training within random subspaces, have shown that deep neural networks can be trained using far fewer degrees of freedom than the total number of parameters. We explain this phenomenon by first examining the success probability of hitting a training loss sub-level set when training within a random subspace of a given training dimensionality. We find a sharp phase transition in the success probability from $0$ to $1$ as the training dimension surpasses a threshold. This threshold training dimension increases as the desired final loss decreases, but decreases as the initial loss decreases. We then theoretically explain the origin of this phase transition, and its dependence on initialization and final desired loss, in terms of precise properties of the high dimensional geometry of the loss landscape. In particular, we show via Gordon's escape theorem, that the training dimension plus the Gaussian width of the desired loss sub-level set, projected onto a unit sphere surrounding the initialization, must exceed the total number of parameters for the success probability to be large. In several architectures and datasets, we measure the threshold training dimension as a function of initialization and demonstrate that it is a small fraction of the total number of parameters, thereby implying, by our theory, that successful training with so few dimensions is possible precisely because the Gaussian width of low loss sub-level sets is very large. Moreover, this threshold training dimension provides a strong null model for assessing the efficacy of more sophisticated ways to reduce training degrees of freedom, including lottery tickets as well a more optimal method we introduce: lottery subspaces.