 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving adversarial examples requires solving exponential misalignment
Mar 03, 2026Adversarial attacks - input perturbations imperceptible to humans that fool neural networks - remain both a persistent failure mode in machine learning, and a phenomenon with mysterious origins. To shed light, we define and analyze a network's perceptual manifold (PM) for a class concept as the space of all inputs confidently assigned to that class by the network. We find, strikingly, that the dimensionalities of neural network PMs are orders of magnitude higher than those of natural human concepts. Since volume typically grows exponentially with dimension, this suggests exponential misalignment between machines and humans, with exponentially many inputs confidently assigned to concepts by machines but not humans. Furthermore, this provides a natural geometric hypothesis for the origin of adversarial examples: because a network's PM fills such a large region of input space, any input will be very close to any class concept's PM. Our hypothesis thus suggests that adversarial robustness cannot be attained without dimensional alignment of machine and human PMs, and therefore makes strong predictions: both robust accuracy and distance to any PM should be negatively correlated with the PM dimension. We confirmed these predictions across 18 different networks of varying robust accuracy. Crucially, we find even the most robust networks are still exponentially misaligned, and only the few PMs whose dimensionality approaches that of human concepts exhibit alignment to human perception. Our results connect the fields of alignment and adversarial examples, and suggest the curse of high dimensionality of machine PMs is a major impediment to adversarial robustness.
Deriving Neural Scaling Laws from the statistics of natural language
Feb 07, 2026Despite the fact that experimental neural scaling laws have substantially guided empirical progress in large-scale machine learning, no existing theory can quantitatively predict the exponents of these important laws for any modern LLM trained on any natural language dataset. We provide the first such theory in the case of data-limited scaling laws. We isolate two key statistical properties of language that alone can predict neural scaling exponents: (i) the decay of pairwise token correlations with time separation between token pairs, and (ii) the decay of the next-token conditional entropy with the length of the conditioning context. We further derive a simple formula in terms of these statistics that predicts data-limited neural scaling exponents from first principles without any free parameters or synthetic data models. Our theory exhibits a remarkable match with experimentally measured neural scaling laws obtained from training GPT-2 and LLaMA style models from scratch on two qualitatively different benchmarks, TinyStories and WikiText.
From Kepler to Newton: Inductive Biases Guide Learned World Models in Transformers
Feb 06, 2026Can general-purpose AI architectures go beyond prediction to discover the physical laws governing the universe? True intelligence relies on "world models" -- causal abstractions that allow an agent to not only predict future states but understand the underlying governing dynamics. While previous "AI Physicist" approaches have successfully recovered such laws, they typically rely on strong, domain-specific priors that effectively "bake in" the physics. Conversely, Vafa et al. recently showed that generic Transformers fail to acquire these world models, achieving high predictive accuracy without capturing the underlying physical laws. We bridge this gap by systematically introducing three minimal inductive biases. We show that ensuring spatial smoothness (by formulating prediction as continuous regression) and stability (by training with noisy contexts to mitigate error accumulation) enables generic Transformers to surpass prior failures and learn a coherent Keplerian world model, successfully fitting ellipses to planetary trajectories. However, true physical insight requires a third bias: temporal locality. By restricting the attention window to the immediate past -- imposing the simple assumption that future states depend only on the local state rather than a complex history -- we force the model to abandon curve-fitting and discover Newtonian force representations. Our results demonstrate that simple architectural choices determine whether an AI becomes a curve-fitter or a physicist, marking a critical step toward automated scientific discovery.
Contrastive Concept-Tree Search for LLM-Assisted Algorithm Discovery
Feb 03, 2026Large language Model (LLM)-assisted algorithm discovery is an iterative, black-box optimization process over programs to approximatively solve a target task, where an LLM proposes candidate programs and an external evaluator provides task feedback. Despite intense recent research on the topic and promising results, how can the LLM internal representation of the space of possible programs be maximally exploited to improve performance is an open question. Here, we introduce Contrastive Concept-Tree Search (CCTS), which extracts a hierarchical concept representation from the generated programs and learns a contrastive concept model that guides parent selection. By reweighting parents using a likelihood-ratio score between high- and low-performing solutions, CCTS biases search toward useful concept combinations and away from misleading ones, providing guidance through an explicit concept hierarchy rather than the algorithm lineage constructed by the LLM. We show that CCTS improves search efficiency over fitness-based baselines and produces interpretable, task-specific concept trees across a benchmark of open Erdős-type combinatorics problems. Our analysis indicates that the gains are driven largely by learning which concepts to avoid. We further validate these findings in a controlled synthetic algorithm-discovery environment, which reproduces qualitatively the search dynamics observed with the LLMs.
Alternating Gradient Flows: A Theory of Feature Learning in Two-layer Neural Networks
Jun 06, 2025What features neural networks learn, and how, remains an open question. In this paper, we introduce Alternating Gradient Flows (AGF), an algorithmic framework that describes the dynamics of feature learning in two-layer networks trained from small initialization. Prior works have shown that gradient flow in this regime exhibits a staircase-like loss curve, alternating between plateaus where neurons slowly align to useful directions and sharp drops where neurons rapidly grow in norm. AGF approximates this behavior as an alternating two-step process: maximizing a utility function over dormant neurons and minimizing a cost function over active ones. AGF begins with all neurons dormant. At each round, a dormant neuron activates, triggering the acquisition of a feature and a drop in the loss. AGF quantifies the order, timing, and magnitude of these drops, matching experiments across architectures. We show that AGF unifies and extends existing saddle-to-saddle analyses in fully connected linear networks and attention-only linear transformers, where the learned features are singular modes and principal components, respectively. In diagonal linear networks, we prove AGF converges to gradient flow in the limit of vanishing initialization. Applying AGF to quadratic networks trained to perform modular addition, we give the first complete characterization of the training dynamics, revealing that networks learn Fourier features in decreasing order of coefficient magnitude. Altogether, AGF offers a promising step towards understanding feature learning in neural networks.
Rethinking Fine-Tuning when Scaling Test-Time Compute: Limiting Confidence Improves Mathematical Reasoning
Feb 11, 2025
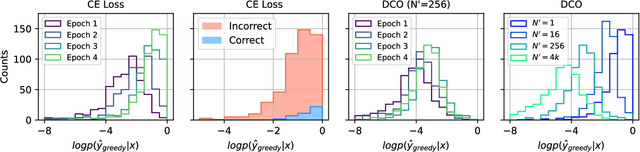
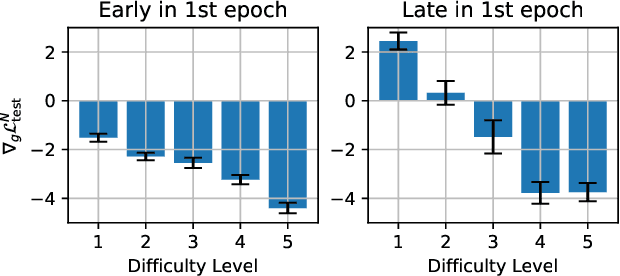
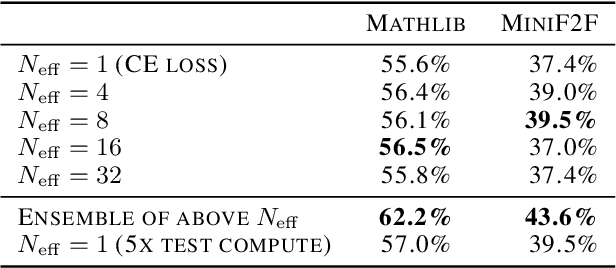
Recent progress in large language models (LLMs) highlights the power of scaling test-time compute to achieve strong performance on complex tasks, such as mathematical reasoning and code generation. This raises a critical question: how should model training be modified to optimize performance under a subsequent test-time compute strategy and budget? To explore this, we focus on pass@N, a simple test-time strategy that searches for a correct answer in $N$ independent samples. We show, surprisingly, that training with cross-entropy (CE) loss can be ${\it misaligned}$ with pass@N in that pass@N accuracy ${\it decreases}$ with longer training. We explain the origins of this misalignment in terms of model overconfidence induced by CE, and experimentally verify our prediction of overconfidence as an impediment to scaling test-time compute via pass@N. Furthermore we suggest a principled, modified training loss that is better aligned to pass@N by limiting model confidence and rescuing pass@N test performance. Our algorithm demonstrates improved mathematical reasoning on MATH and MiniF2F benchmarks under several scenarios: (1) providing answers to math questions; and (2) proving theorems by searching over proof trees of varying shapes. Overall our work underscores the importance of co-designing two traditionally separate phases of LLM development: training-time protocols and test-time search and reasoning strategies.
An analytic theory of creativity in convolutional diffusion models
Dec 28, 2024
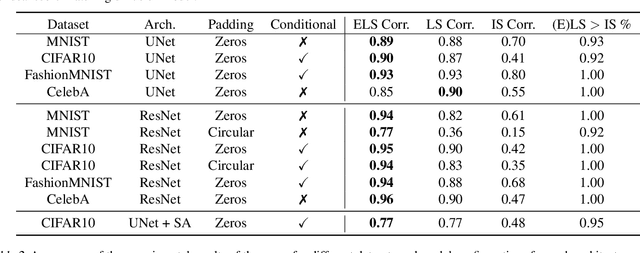
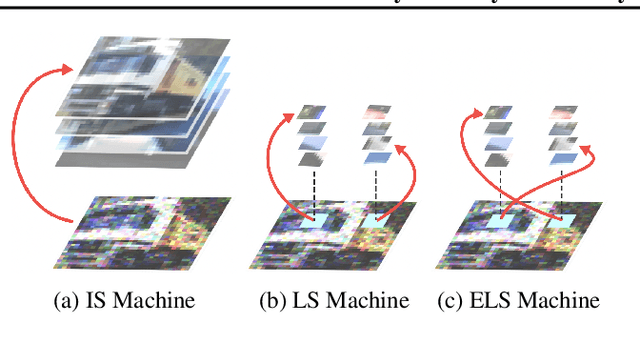
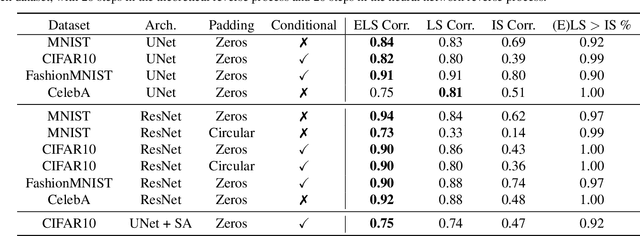
We obtain the first analytic, interpretable and predictive theory of creativity in convolutional diffusion models. Indeed, score-based diffusion models can generate highly creative images that lie far from their training data. But optimal score-matching theory suggests that these models should only be able to produce memorized training examples. To reconcile this theory-experiment gap, we identify two simple inductive biases, locality and equivariance, that: (1) induce a form of combinatorial creativity by preventing optimal score-matching; (2) result in a fully analytic, completely mechanistically interpretable, equivariant local score (ELS) machine that, (3) without any training can quantitatively predict the outputs of trained convolution only diffusion models (like ResNets and UNets) with high accuracy (median $r^2$ of $0.90, 0.91, 0.94$ on CIFAR10, FashionMNIST, and MNIST). Our ELS machine reveals a locally consistent patch mosaic model of creativity, in which diffusion models create exponentially many novel images by mixing and matching different local training set patches in different image locations. Our theory also partially predicts the outputs of pre-trained self-attention enabled UNets (median $r^2 \sim 0.75$ on CIFAR10), revealing an intriguing role for attention in carving out semantic coherence from local patch mosaics.
Fooling LLM graders into giving better grades through neural activity guided adversarial prompting
Dec 17, 2024The deployment of artificial intelligence (AI) in critical decision-making and evaluation processes raises concerns about inherent biases that malicious actors could exploit to distort decision outcomes. We propose a systematic method to reveal such biases in AI evaluation systems and apply it to automated essay grading as an example. Our approach first identifies hidden neural activity patterns that predict distorted decision outcomes and then optimizes an adversarial input suffix to amplify such patterns. We demonstrate that this combination can effectively fool large language model (LLM) graders into assigning much higher grades than humans would. We further show that this white-box attack transfers to black-box attacks on other models, including commercial closed-source models like Gemini. They further reveal the existence of a "magic word" that plays a pivotal role in the efficacy of the attack. We trace the origin of this magic word bias to the structure of commonly-used chat templates for supervised fine-tuning of LLMs and show that a minor change in the template can drastically reduce the bias. This work not only uncovers vulnerabilities in current LLMs but also proposes a systematic method to identify and remove hidden biases, contributing to the goal of ensuring AI safety and security.
Features are fate: a theory of transfer learning in high-dimensional regression
Oct 10, 2024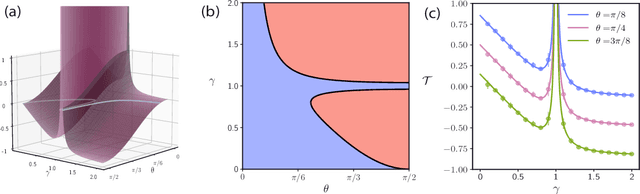
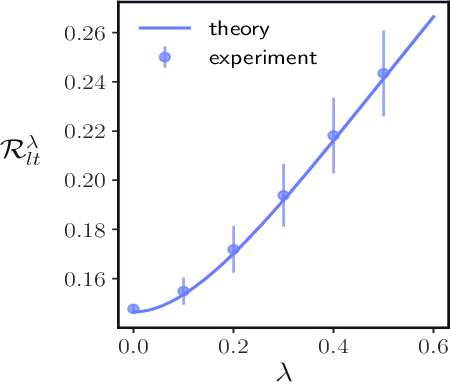
With the emergence of large-scale pre-trained neural networks, methods to adapt such "foundation" models to data-limited downstream tasks have become a necessity. Fine-tuning, preference optimization, and transfer learning have all been successfully employed for these purposes when the target task closely resembles the source task, but a precise theoretical understanding of "task similarity" is still lacking. While conventional wisdom suggests that simple measures of similarity between source and target distributions, such as $\phi$-divergences or integral probability metrics, can directly predict the success of transfer, we prove the surprising fact that, in general, this is not the case. We adopt, instead, a feature-centric viewpoint on transfer learning and establish a number of theoretical results that demonstrate that when the target task is well represented by the feature space of the pre-trained model, transfer learning outperforms training from scratch. We study deep linear networks as a minimal model of transfer learning in which we can analytically characterize the transferability phase diagram as a function of the target dataset size and the feature space overlap. For this model, we establish rigorously that when the feature space overlap between the source and target tasks is sufficiently strong, both linear transfer and fine-tuning improve performance, especially in the low data limit. These results build on an emerging understanding of feature learning dynamics in deep linear networks, and we demonstrate numerically that the rigorous results we derive for the linear case also apply to nonlinear networks.
Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning
Jun 10, 2024



While the impressive performance of modern neural networks is often attributed to their capacity to efficiently extract task-relevant features from data, the mechanisms underlying this rich feature learning regime remain elusive, with much of our theoretical understanding stemming from the opposing lazy regime. In this work, we derive exact solutions to a minimal model that transitions between lazy and rich learning, precisely elucidating how unbalanced layer-specific initialization variances and learning rates determine the degree of feature learning. Our analysis reveals that they conspire to influence the learning regime through a set of conserved quantities that constrain and modify the geometry of learning trajectories in parameter and function space. We extend our analysis to more complex linear models with multiple neurons, outputs, and layers and to shallow nonlinear networks with piecewise linear activation functions. In linear networks, rapid feature learning only occurs with balanced initializations, where all layers learn at similar speeds. While in nonlinear networks, unbalanced initializations that promote faster learning in earlier layers can accelerate rich learning. Through a series of experiments, we provide evidence that this unbalanced rich regime drives feature learning in deep finite-width networks, promotes interpretability of early layers in CNNs, reduces the sample complexity of learning hierarchical data, and decreases the time to grokking in modular arithmetic. Our theory motivates further exploration of unbalanced initializations to enhance efficient feature learning.