 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Group Composition: A Window into the Mechanics of Deep Learning
Feb 03, 2026How do neural networks trained over sequences acquire the ability to perform structured operations, such as arithmetic, geometric, and algorithmic computation? To gain insight into this question, we introduce the sequential group composition task. In this task, networks receive a sequence of elements from a finite group encoded in a real vector space and must predict their cumulative product. The task can be order-sensitive and requires a nonlinear architecture to be learned. Our analysis isolates the roles of the group structure, encoding statistics, and sequence length in shaping learning. We prove that two-layer networks learn this task one irreducible representation of the group at a time in an order determined by the Fourier statistics of the encoding. These networks can perfectly learn the task, but doing so requires a hidden width exponential in the sequence length $k$. In contrast, we show how deeper models exploit the associativity of the task to dramatically improve this scaling: recurrent neural networks compose elements sequentially in $k$ steps, while multilayer networks compose adjacent pairs in parallel in $\log k$ layers. Overall, the sequential group composition task offers a tractable window into the mechanics of deep learning.
Symmetry Breaking in Transformers for Efficient and Interpretable Training
Jan 29, 2026The attention mechanism in its standard implementation contains extraneous rotational degrees of freedom that are carried through computation but do not affect model activations or outputs. We introduce a simple symmetry-breaking protocol that inserts a preferred direction into this rotational space through batchwise-sampled, unlearned query and value biases. This modification has two theoretically motivated and empirically validated consequences. First, it can substantially improve the performance of simple, memory-efficient optimizers, narrowing -- and in some cases closing -- the gap to successful but more complex memory-intensive adaptive methods. We demonstrate this by pretraining 124M parameter transformer models with four optimization algorithms (AdamW, SOAP, SGDM, and Energy Conserving Descent(ECD)) and evaluating both validation loss and downstream logical reasoning. Second, it enables an interpretable use of otherwise redundant rotational degrees of freedom, selectively amplifying semantically meaningful token classes within individual attention heads. Overall, our results show that minimal, principled architectural changes can simultaneously improve performance and interpretability.
Alternating Gradient Flows: A Theory of Feature Learning in Two-layer Neural Networks
Jun 06, 2025What features neural networks learn, and how, remains an open question. In this paper, we introduce Alternating Gradient Flows (AGF), an algorithmic framework that describes the dynamics of feature learning in two-layer networks trained from small initialization. Prior works have shown that gradient flow in this regime exhibits a staircase-like loss curve, alternating between plateaus where neurons slowly align to useful directions and sharp drops where neurons rapidly grow in norm. AGF approximates this behavior as an alternating two-step process: maximizing a utility function over dormant neurons and minimizing a cost function over active ones. AGF begins with all neurons dormant. At each round, a dormant neuron activates, triggering the acquisition of a feature and a drop in the loss. AGF quantifies the order, timing, and magnitude of these drops, matching experiments across architectures. We show that AGF unifies and extends existing saddle-to-saddle analyses in fully connected linear networks and attention-only linear transformers, where the learned features are singular modes and principal components, respectively. In diagonal linear networks, we prove AGF converges to gradient flow in the limit of vanishing initialization. Applying AGF to quadratic networks trained to perform modular addition, we give the first complete characterization of the training dynamics, revealing that networks learn Fourier features in decreasing order of coefficient magnitude. Altogether, AGF offers a promising step towards understanding feature learning in neural networks.
From Lazy to Rich: Exact Learning Dynamics in Deep Linear Networks
Sep 22, 2024



Biological and artificial neural networks develop internal representations that enable them to perform complex tasks. In artificial networks, the effectiveness of these models relies on their ability to build task specific representation, a process influenced by interactions among datasets, architectures, initialization strategies, and optimization algorithms. Prior studies highlight that different initializations can place networks in either a lazy regime, where representations remain static, or a rich/feature learning regime, where representations evolve dynamically. Here, we examine how initialization influences learning dynamics in deep linear neural networks, deriving exact solutions for lambda-balanced initializations-defined by the relative scale of weights across layers. These solutions capture the evolution of representations and the Neural Tangent Kernel across the spectrum from the rich to the lazy regimes. Our findings deepen the theoretical understanding of the impact of weight initialization on learning regimes, with implications for continual learning, reversal learning, and transfer learning, relevant to both neuroscience and practical applications.
Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning
Jun 10, 2024



While the impressive performance of modern neural networks is often attributed to their capacity to efficiently extract task-relevant features from data, the mechanisms underlying this rich feature learning regime remain elusive, with much of our theoretical understanding stemming from the opposing lazy regime. In this work, we derive exact solutions to a minimal model that transitions between lazy and rich learning, precisely elucidating how unbalanced layer-specific initialization variances and learning rates determine the degree of feature learning. Our analysis reveals that they conspire to influence the learning regime through a set of conserved quantities that constrain and modify the geometry of learning trajectories in parameter and function space. We extend our analysis to more complex linear models with multiple neurons, outputs, and layers and to shallow nonlinear networks with piecewise linear activation functions. In linear networks, rapid feature learning only occurs with balanced initializations, where all layers learn at similar speeds. While in nonlinear networks, unbalanced initializations that promote faster learning in earlier layers can accelerate rich learning. Through a series of experiments, we provide evidence that this unbalanced rich regime drives feature learning in deep finite-width networks, promotes interpretability of early layers in CNNs, reduces the sample complexity of learning hierarchical data, and decreases the time to grokking in modular arithmetic. Our theory motivates further exploration of unbalanced initializations to enhance efficient feature learning.
Stochastic Collapse: How Gradient Noise Attracts SGD Dynamics Towards Simpler Subnetworks
Jun 07, 2023In this work, we reveal a strong implicit bias of stochastic gradient descent (SGD) that drives overly expressive networks to much simpler subnetworks, thereby dramatically reducing the number of independent parameters, and improving generalization. To reveal this bias, we identify invariant sets, or subsets of parameter space that remain unmodified by SGD. We focus on two classes of invariant sets that correspond to simpler subnetworks and commonly appear in modern architectures. Our analysis uncovers that SGD exhibits a property of stochastic attractivity towards these simpler invariant sets. We establish a sufficient condition for stochastic attractivity based on a competition between the loss landscape's curvature around the invariant set and the noise introduced by stochastic gradients. Remarkably, we find that an increased level of noise strengthens attractivity, leading to the emergence of attractive invariant sets associated with saddle-points or local maxima of the train loss. We observe empirically the existence of attractive invariant sets in trained deep neural networks, implying that SGD dynamics often collapses to simple subnetworks with either vanishing or redundant neurons. We further demonstrate how this simplifying process of stochastic collapse benefits generalization in a linear teacher-student framework. Finally, through this analysis, we mechanistically explain why early training with large learning rates for extended periods benefits subsequent generalization.
The Asymmetric Maximum Margin Bias of Quasi-Homogeneous Neural Networks
Oct 07, 2022


In this work, we explore the maximum-margin bias of quasi-homogeneous neural networks trained with gradient flow on an exponential loss and past a point of separability. We introduce the class of quasi-homogeneous models, which is expressive enough to describe nearly all neural networks with homogeneous activations, even those with biases, residual connections, and normalization layers, while structured enough to enable geometric analysis of its gradient dynamics. Using this analysis, we generalize the existing results of maximum-margin bias for homogeneous networks to this richer class of models. We find that gradient flow implicitly favors a subset of the parameters, unlike in the case of a homogeneous model where all parameters are treated equally. We demonstrate through simple examples how this strong favoritism toward minimizing an asymmetric norm can degrade the robustness of quasi-homogeneous models. On the other hand, we conjecture that this norm-minimization discards, when possible, unnecessary higher-order parameters, reducing the model to a sparser parameterization. Lastly, by applying our theorem to sufficiently expressive neural networks with normalization layers, we reveal a universal mechanism behind the empirical phenomenon of Neural Collapse.
Rethinking the limiting dynamics of SGD: modified loss, phase space oscillations, and anomalous diffusion
Jul 19, 2021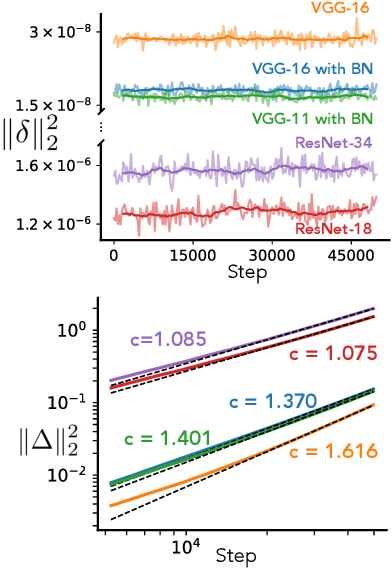
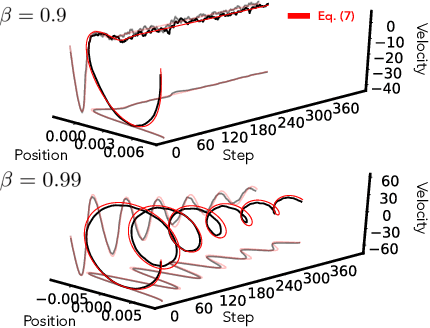

In this work we explore the limiting dynamics of deep neural networks trained with stochastic gradient descent (SGD). We find empirically that long after performance has converged, networks continue to move through parameter space by a process of anomalous diffusion in which distance travelled grows as a power law in the number of gradient updates with a nontrivial exponent. We reveal an intricate interaction between the hyperparameters of optimization, the structure in the gradient noise, and the Hessian matrix at the end of training that explains this anomalous diffusion. To build this understanding, we first derive a continuous-time model for SGD with finite learning rates and batch sizes as an underdamped Langevin equation. We study this equation in the setting of linear regression, where we can derive exact, analytic expressions for the phase space dynamics of the parameters and their instantaneous velocities from initialization to stationarity. Using the Fokker-Planck equation, we show that the key ingredient driving these dynamics is not the original training loss, but rather the combination of a modified loss, which implicitly regularizes the velocity, and probability currents, which cause oscillations in phase space. We identify qualitative and quantitative predictions of this theory in the dynamics of a ResNet-18 model trained on ImageNet. Through the lens of statistical physics, we uncover a mechanistic origin for the anomalous limiting dynamics of deep neural networks trained with SGD.
Noether's Learning Dynamics: The Role of Kinetic Symmetry Breaking in Deep Learning
May 06, 2021

In nature, symmetry governs regularities, while symmetry breaking brings texture. Here, we reveal a novel role of symmetry breaking behind efficiency and stability in learning, a critical issue in machine learning. Recent experiments suggest that the symmetry of the loss function is closely related to the learning performance. This raises a fundamental question. Is such symmetry beneficial, harmful, or irrelevant to the success of learning? Here, we demystify this question and pose symmetry breaking as a new design principle by considering the symmetry of the learning rule in addition to the loss function. We model the discrete learning dynamics using a continuous-time Lagrangian formulation, in which the learning rule corresponds to the kinetic energy and the loss function corresponds to the potential energy. We identify kinetic asymmetry unique to learning systems, where the kinetic energy often does not have the same symmetry as the potential (loss) function reflecting the non-physical symmetries of the loss function and the non-Euclidean metric used in learning rules. We generalize Noether's theorem known in physics to explicitly take into account this kinetic asymmetry and derive the resulting motion of the Noether charge. Finally, we apply our theory to modern deep networks with normalization layers and reveal a mechanism of implicit adaptive optimization induced by the kinetic symmetry breaking.
Neural Mechanics: Symmetry and Broken Conservation Laws in Deep Learning Dynamics
Dec 08, 2020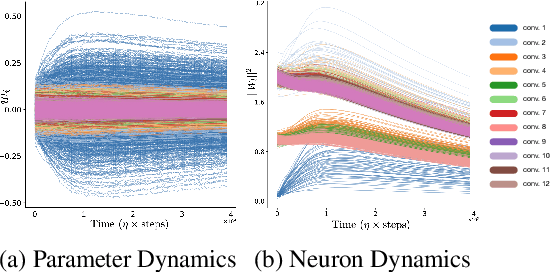
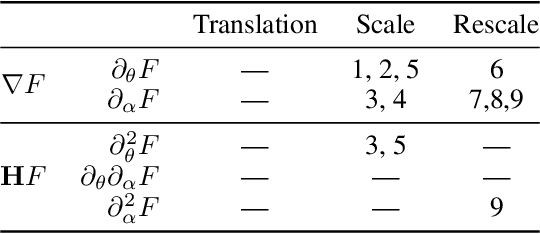
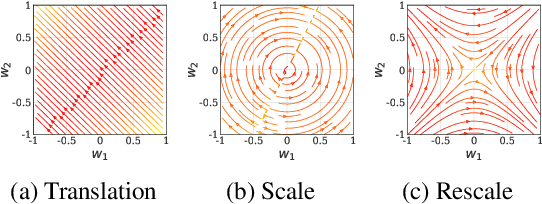

Predicting the dynamics of neural network parameters during training is one of the key challenges in building a theoretical foundation for deep learning. A central obstacle is that the motion of a network in high-dimensional parameter space undergoes discrete finite steps along complex stochastic gradients derived from real-world datasets. We circumvent this obstacle through a unifying theoretical framework based on intrinsic symmetries embedded in a network's architecture that are present for any dataset. We show that any such symmetry imposes stringent geometric constraints on gradients and Hessians, leading to an associated conservation law in the continuous-time limit of stochastic gradient descent (SGD), akin to Noether's theorem in physics. We further show that finite learning rates used in practice can actually break these symmetry induced conservation laws. We apply tools from finite difference methods to derive modified gradient flow, a differential equation that better approximates the numerical trajectory taken by SGD at finite learning rates. We combine modified gradient flow with our framework of symmetries to derive exact integral expressions for the dynamics of certain parameter combinations. We empirically validate our analytic predictions for learning dynamics on VGG-16 trained on Tiny ImageNet. Overall, by exploiting symmetry, our work demonstrates that we can analytically describe the learning dynamics of various parameter combinations at finite learning rates and batch sizes for state of the art architectures trained on any dataset.