 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Flow Matching for Motion Prediction
Dec 27, 2025Motion prediction has been studied in different contexts with models trained on narrow distributions and applied to downstream tasks in human motion prediction and robotics. Simultaneously, recent efforts in scaling video prediction have demonstrated impressive visual realism, yet they struggle to accurately model complex motions despite massive scale. Inspired by the scaling of video generation, we develop autoregressive flow matching (ARFM), a new method for probabilistic modeling of sequential continuous data and train it on diverse video datasets to generate future point track locations over long horizons. To evaluate our model, we develop benchmarks for evaluating the ability of motion prediction models to predict human and robot motion. Our model is able to predict complex motions, and we demonstrate that conditioning robot action prediction and human motion prediction on predicted future tracks can significantly improve downstream task performance. Code and models publicly available at: https://github.com/Johnathan-Xie/arfm-motion-prediction.
Weakly-Supervised Learning of Dense Functional Correspondences
Sep 04, 2025Establishing dense correspondences across image pairs is essential for tasks such as shape reconstruction and robot manipulation. In the challenging setting of matching across different categories, the function of an object, i.e., the effect that an object can cause on other objects, can guide how correspondences should be established. This is because object parts that enable specific functions often share similarities in shape and appearance. We derive the definition of dense functional correspondence based on this observation and propose a weakly-supervised learning paradigm to tackle the prediction task. The main insight behind our approach is that we can leverage vision-language models to pseudo-label multi-view images to obtain functional parts. We then integrate this with dense contrastive learning from pixel correspondences to distill both functional and spatial knowledge into a new model that can establish dense functional correspondence. Further, we curate synthetic and real evaluation datasets as task benchmarks. Our results demonstrate the advantages of our approach over baseline solutions consisting of off-the-shelf self-supervised image representations and grounded vision language models.
3D Scene Understanding Through Local Random Access Sequence Modeling
Apr 04, 20253D scene understanding from single images is a pivotal problem in computer vision with numerous downstream applications in graphics, augmented reality, and robotics. While diffusion-based modeling approaches have shown promise, they often struggle to maintain object and scene consistency, especially in complex real-world scenarios. To address these limitations, we propose an autoregressive generative approach called Local Random Access Sequence (LRAS) modeling, which uses local patch quantization and randomly ordered sequence generation. By utilizing optical flow as an intermediate representation for 3D scene editing, our experiments demonstrate that LRAS achieves state-of-the-art novel view synthesis and 3D object manipulation capabilities. Furthermore, we show that our framework naturally extends to self-supervised depth estimation through a simple modification of the sequence design. By achieving strong performance on multiple 3D scene understanding tasks, LRAS provides a unified and effective framework for building the next generation of 3D vision models.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024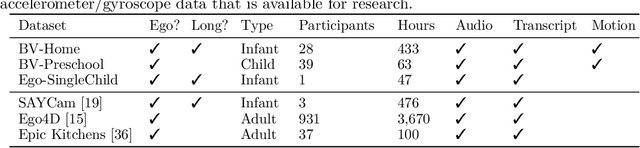
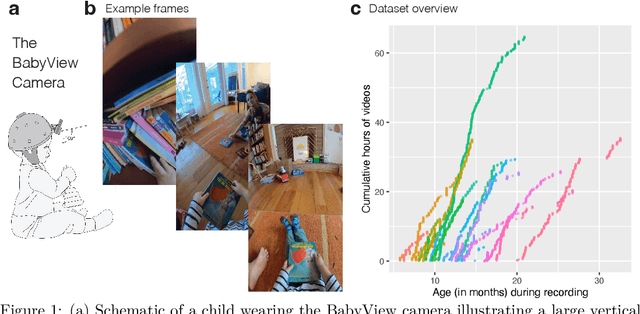
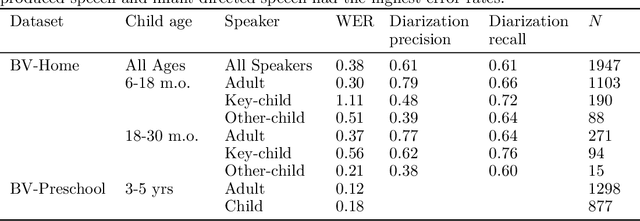
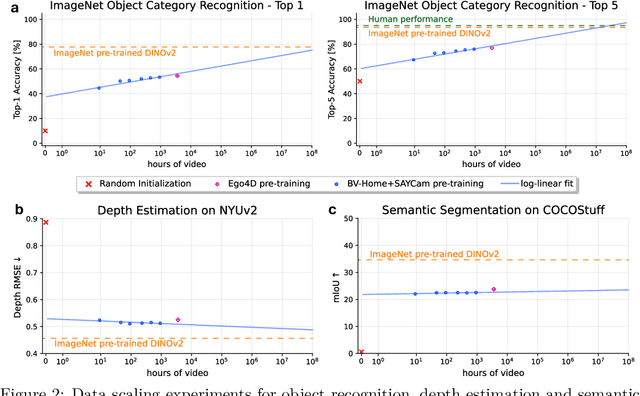
Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?
Counterfactual World Modeling for Physical Dynamics Understanding
Dec 26, 2023



The ability to understand physical dynamics is essential to learning agents acting in the world. This paper presents Counterfactual World Modeling (CWM), a candidate pure vision foundational model for physical dynamics understanding. CWM consists of three basic concepts. First, we propose a simple and powerful temporally-factored masking policy for masked prediction of video data, which encourages the model to learn disentangled representations of scene appearance and dynamics. Second, as a result of the factoring, CWM is capable of generating counterfactual next-frame predictions by manipulating a few patch embeddings to exert meaningful control over scene dynamics. Third, the counterfactual modeling capability enables the design of counterfactual queries to extract vision structures similar to keypoints, optical flows, and segmentations, which are useful for dynamics understanding. We show that zero-shot readouts of these structures extracted by the counterfactual queries attain competitive performance to prior methods on real-world datasets. Finally, we demonstrate that CWM achieves state-of-the-art performance on the challenging Physion benchmark for evaluating physical dynamics understanding.
Are These the Same Apple? Comparing Images Based on Object Intrinsics
Nov 01, 2023



The human visual system can effortlessly recognize an object under different extrinsic factors such as lighting, object poses, and background, yet current computer vision systems often struggle with these variations. An important step to understanding and improving artificial vision systems is to measure image similarity purely based on intrinsic object properties that define object identity. This problem has been studied in the computer vision literature as re-identification, though mostly restricted to specific object categories such as people and cars. We propose to extend it to general object categories, exploring an image similarity metric based on object intrinsics. To benchmark such measurements, we collect the Common paired objects Under differenT Extrinsics (CUTE) dataset of $18,000$ images of $180$ objects under different extrinsic factors such as lighting, poses, and imaging conditions. While existing methods such as LPIPS and CLIP scores do not measure object intrinsics well, we find that combining deep features learned from contrastive self-supervised learning with foreground filtering is a simple yet effective approach to approximating the similarity. We conduct an extensive survey of pre-trained features and foreground extraction methods to arrive at a strong baseline that best measures intrinsic object-centric image similarity among current methods. Finally, we demonstrate that our approach can aid in downstream applications such as acting as an analog for human subjects and improving generalizable re-identification. Please see our project website at https://s-tian.github.io/projects/cute/ for visualizations of the data and demos of our metric.
Unifying (Machine) Vision via Counterfactual World Modeling
Jun 02, 2023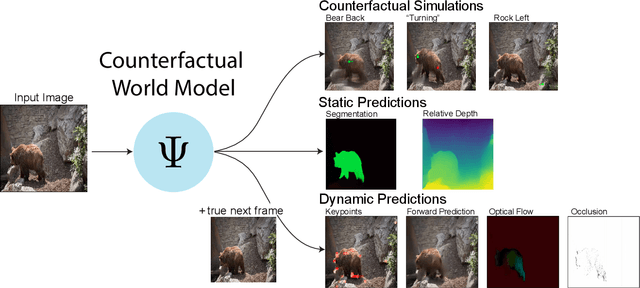


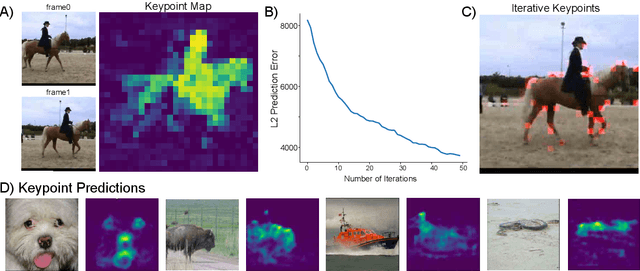
Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.
Measuring and Modeling Physical Intrinsic Motivation
May 24, 2023



Humans are interactive agents driven to seek out situations with interesting physical dynamics. Here we formalize the functional form of physical intrinsic motivation. We first collect ratings of how interesting humans find a variety of physics scenarios. We then model human interestingness responses by implementing various hypotheses of intrinsic motivation including models that rely on simple scene features to models that depend on forward physics prediction. We find that the single best predictor of human responses is adversarial reward, a model derived from physical prediction loss. We also find that simple scene feature models do not generalize their prediction of human responses across all scenarios. Finally, linearly combining the adversarial model with the number of collisions in a scene leads to the greatest improvement in predictivity of human responses, suggesting humans are driven towards scenarios that result in high information gain and physical activity.
Developmental Curiosity and Social Interaction in Virtual Agents
May 22, 2023Infants explore their complex physical and social environment in an organized way. To gain insight into what intrinsic motivations may help structure this exploration, we create a virtual infant agent and place it in a developmentally-inspired 3D environment with no external rewards. The environment has a virtual caregiver agent with the capability to interact contingently with the infant agent in ways that resemble play. We test intrinsic reward functions that are similar to motivations that have been proposed to drive exploration in humans: surprise, uncertainty, novelty, and learning progress. These generic reward functions lead the infant agent to explore its environment and discover the contingencies that are embedded into the caregiver agent. The reward functions that are proxies for novelty and uncertainty are the most successful in generating diverse experiences and activating the environment contingencies. We also find that learning a world model in the presence of an attentive caregiver helps the infant agent learn how to predict scenarios with challenging social and physical dynamics. Taken together, our findings provide insight into how curiosity-like intrinsic rewards and contingent social interaction lead to dynamic social behavior and the creation of a robust predictive world model.
Unsupervised Segmentation in Real-World Images via Spelke Object Inference
May 17, 2022
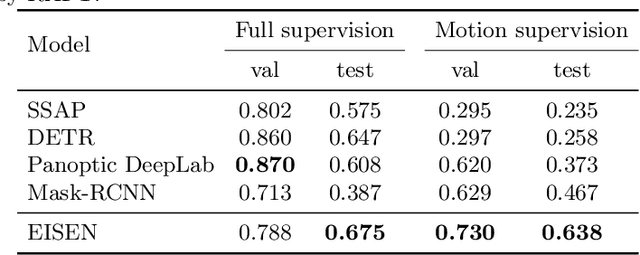
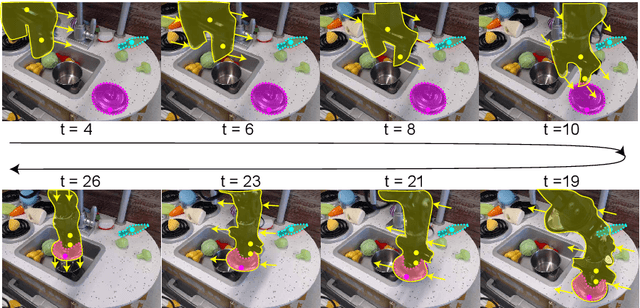

Self-supervised category-agnostic segmentation of real-world images into objects is a challenging open problem in computer vision. Here, we show how to learn static grouping priors from motion self-supervision, building on the cognitive science notion of Spelke Objects: groupings of stuff that move together. We introduce Excitatory-Inhibitory Segment Extraction Network (EISEN), which learns from optical flow estimates to extract pairwise affinity graphs for static scenes. EISEN then produces segments from affinities using a novel graph propagation and competition mechanism. Correlations between independent sources of motion (e.g. robot arms) and objects they move are resolved into separate segments through a bootstrapping training process. We show that EISEN achieves a substantial improvement in the state of the art for self-supervised segmentation on challenging synthetic and real-world robotic image datasets. We also present an ablation analysis illustrating the importance of each element of the EISEN architecture.