 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot World Models Are Developmentally Efficient Learners
Apr 11, 2026Young children demonstrate early abilities to understand their physical world, estimating depth, motion, object coherence, interactions, and many other aspects of physical scene understanding. Children are both data-efficient and flexible cognitive systems, creating competence despite extremely limited training data, while generalizing to myriad untrained tasks -- a major challenge even for today's best AI systems. Here we introduce a novel computational hypothesis for these abilities, the Zero-shot Visual World Model (ZWM). ZWM is based on three principles: a sparse temporally-factored predictor that decouples appearance from dynamics; zero-shot estimation through approximate causal inference; and composition of inferences to build more complex abilities. We show that ZWM can be learned from the first-person experience of a single child, rapidly generating competence across multiple physical understanding benchmarks. It also broadly recapitulates behavioral signatures of child development and builds brain-like internal representations. Our work presents a blueprint for efficient and flexible learning from human-scale data, advancing both a computational account for children's early physical understanding and a path toward data-efficient AI systems.
Counterfactual World Modeling for Physical Dynamics Understanding
Dec 26, 2023



The ability to understand physical dynamics is essential to learning agents acting in the world. This paper presents Counterfactual World Modeling (CWM), a candidate pure vision foundational model for physical dynamics understanding. CWM consists of three basic concepts. First, we propose a simple and powerful temporally-factored masking policy for masked prediction of video data, which encourages the model to learn disentangled representations of scene appearance and dynamics. Second, as a result of the factoring, CWM is capable of generating counterfactual next-frame predictions by manipulating a few patch embeddings to exert meaningful control over scene dynamics. Third, the counterfactual modeling capability enables the design of counterfactual queries to extract vision structures similar to keypoints, optical flows, and segmentations, which are useful for dynamics understanding. We show that zero-shot readouts of these structures extracted by the counterfactual queries attain competitive performance to prior methods on real-world datasets. Finally, we demonstrate that CWM achieves state-of-the-art performance on the challenging Physion benchmark for evaluating physical dynamics understanding.
Deep Bayesian Active Learning for Multiple Correct Outputs
Dec 08, 2019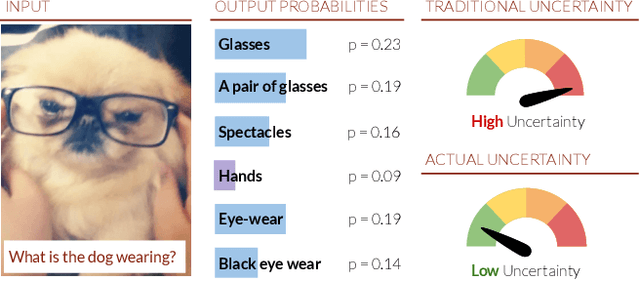
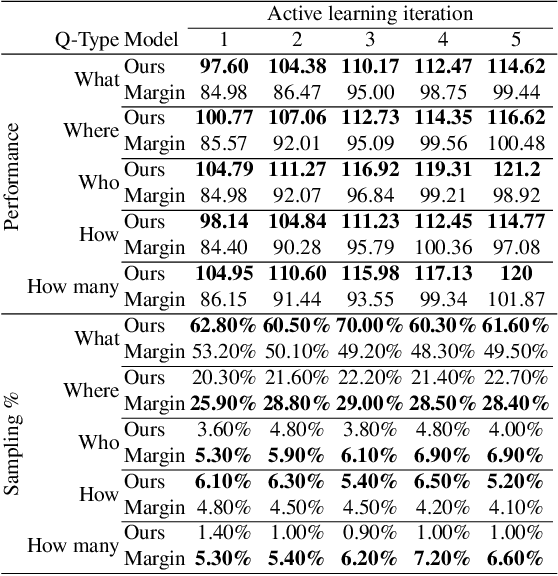
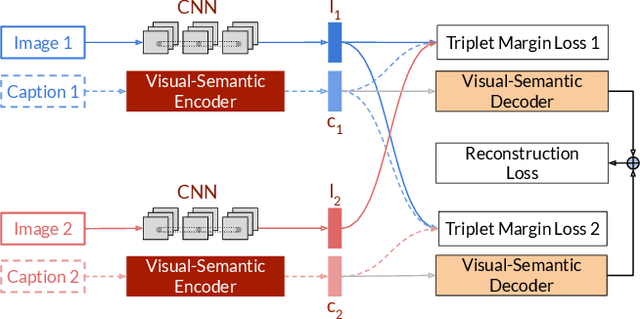
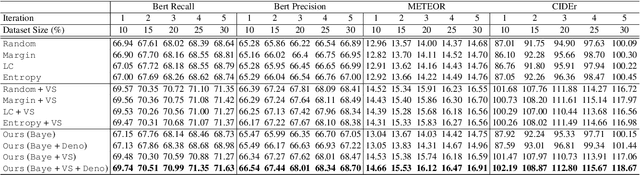
Typical active learning strategies are designed for tasks, such as classification, with the assumption that the output space is mutually exclusive. The assumption that these tasks always have exactly one correct answer has resulted in the creation of numerous uncertainty-based measurements, such as entropy and least confidence, which operate over a model's outputs. Unfortunately, many real-world vision tasks, like visual question answering and image captioning, have multiple correct answers, causing these measurements to overestimate uncertainty and sometimes perform worse than a random sampling baseline. In this paper, we propose a new paradigm that estimates uncertainty in the model's internal hidden space instead of the model's output space. We specifically study a manifestation of this problem for visual question answer generation (VQA), where the aim is not to classify the correct answer but to produce a natural language answer, given an image and a question. Our method overcomes the paraphrastic nature of language. It requires a semantic space that structures the model's output concepts and that enables the usage of techniques like dropout-based Bayesian uncertainty. We build a visual-semantic space that embeds paraphrases close together for any existing VQA model. We empirically show state-of-art active learning results on the task of VQA on two datasets, being 5 times more cost-efficient on Visual Genome and 3 times more cost-efficient on VQA 2.0.