 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning of Motion Concepts by Optimizing Counterfactuals
Mar 25, 2025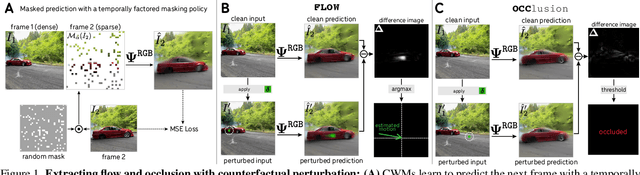
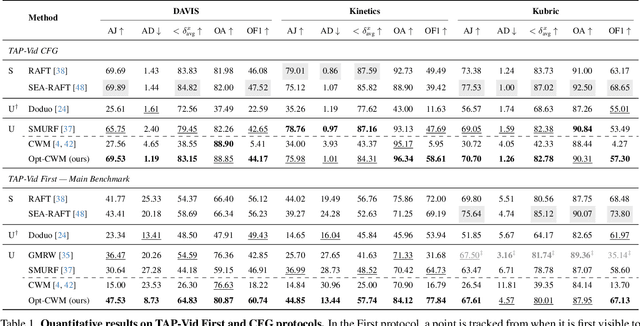
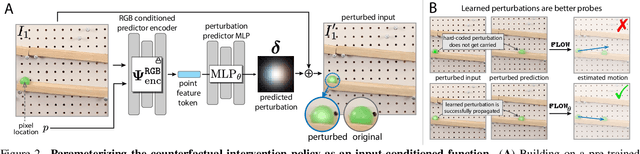
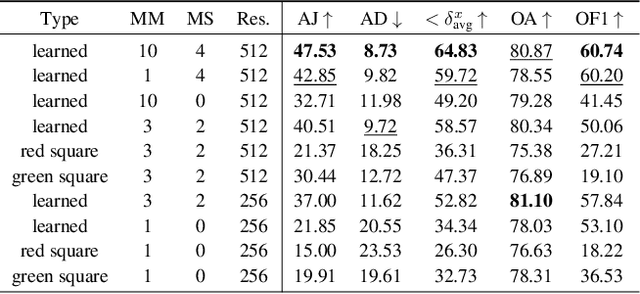
Estimating motion in videos is an essential computer vision problem with many downstream applications, including controllable video generation and robotics. Current solutions are primarily trained using synthetic data or require tuning of situation-specific heuristics, which inherently limits these models' capabilities in real-world contexts. Despite recent developments in large-scale self-supervised learning from videos, leveraging such representations for motion estimation remains relatively underexplored. In this work, we develop Opt-CWM, a self-supervised technique for flow and occlusion estimation from a pre-trained next-frame prediction model. Opt-CWM works by learning to optimize counterfactual probes that extract motion information from a base video model, avoiding the need for fixed heuristics while training on unrestricted video inputs. We achieve state-of-the-art performance for motion estimation on real-world videos while requiring no labeled data.
Counterfactual World Modeling for Physical Dynamics Understanding
Dec 26, 2023



The ability to understand physical dynamics is essential to learning agents acting in the world. This paper presents Counterfactual World Modeling (CWM), a candidate pure vision foundational model for physical dynamics understanding. CWM consists of three basic concepts. First, we propose a simple and powerful temporally-factored masking policy for masked prediction of video data, which encourages the model to learn disentangled representations of scene appearance and dynamics. Second, as a result of the factoring, CWM is capable of generating counterfactual next-frame predictions by manipulating a few patch embeddings to exert meaningful control over scene dynamics. Third, the counterfactual modeling capability enables the design of counterfactual queries to extract vision structures similar to keypoints, optical flows, and segmentations, which are useful for dynamics understanding. We show that zero-shot readouts of these structures extracted by the counterfactual queries attain competitive performance to prior methods on real-world datasets. Finally, we demonstrate that CWM achieves state-of-the-art performance on the challenging Physion benchmark for evaluating physical dynamics understanding.
Unifying (Machine) Vision via Counterfactual World Modeling
Jun 02, 2023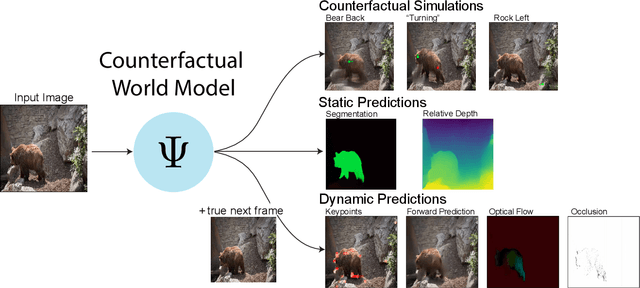


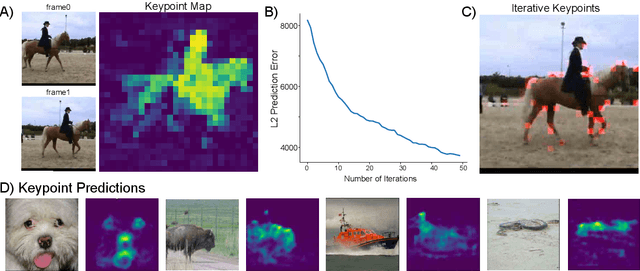
Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.
ThreeDWorld: A Platform for Interactive Multi-Modal Physical Simulation
Jul 09, 2020
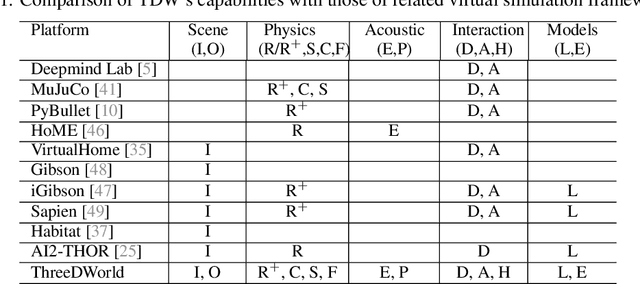

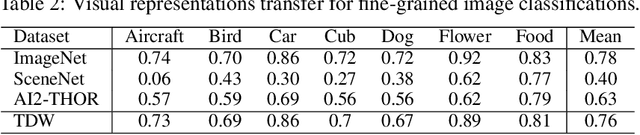
We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. With TDW, users can simulate high-fidelity sensory data and physical interactions between mobile agents and objects in a wide variety of rich 3D environments. TDW has several unique properties: 1) realtime near photo-realistic image rendering quality; 2) a library of objects and environments with materials for high-quality rendering, and routines enabling user customization of the asset library; 3) generative procedures for efficiently building classes of new environments 4) high-fidelity audio rendering; 5) believable and realistic physical interactions for a wide variety of material types, including cloths, liquid, and deformable objects; 6) a range of "avatar" types that serve as embodiments of AI agents, with the option for user avatar customization; and 7) support for human interactions with VR devices. TDW also provides a rich API enabling multiple agents to interact within a simulation and return a range of sensor and physics data representing the state of the world. We present initial experiments enabled by the platform around emerging research directions in computer vision, machine learning, and cognitive science, including multi-modal physical scene understanding, multi-agent interactions, models that "learn like a child", and attention studies in humans and neural networks. The simulation platform will be made publicly available.
Flexible and Efficient Long-Range Planning Through Curious Exploration
Apr 22, 2020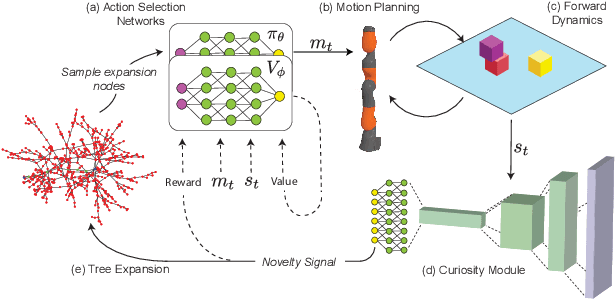
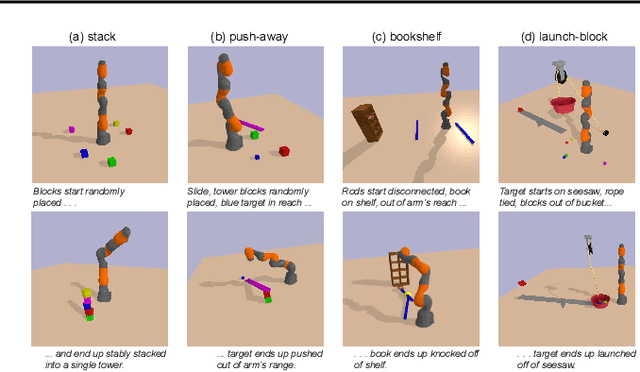
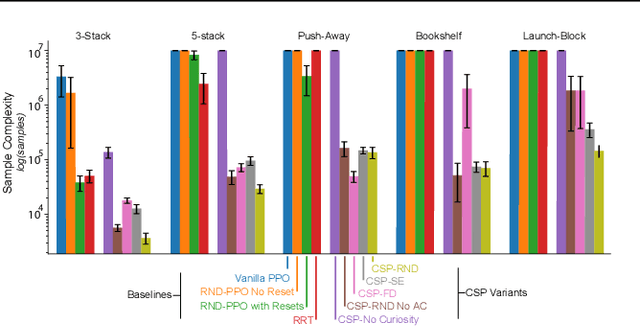
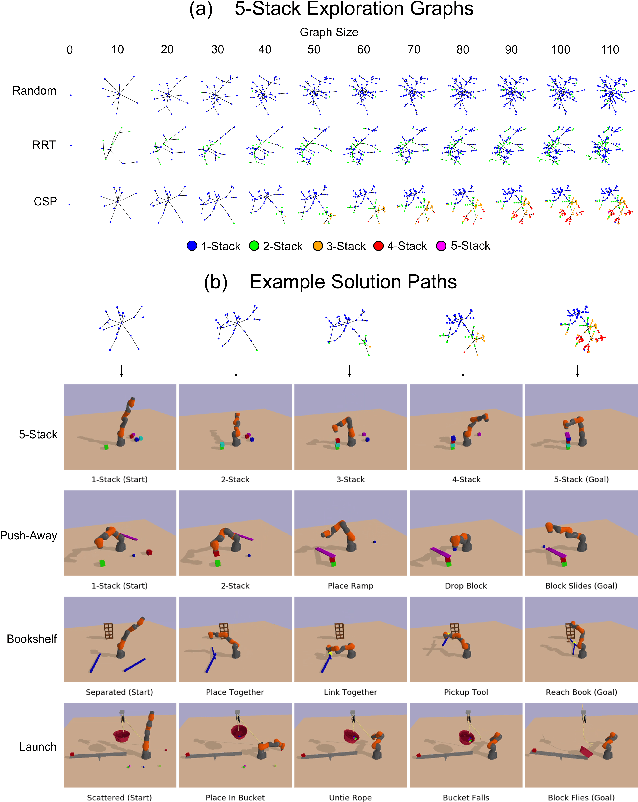
Identifying algorithms that flexibly and efficiently discover temporally-extended multi-phase plans is an essential step for the advancement of robotics and model-based reinforcement learning. The core problem of long-range planning is finding an efficient way to search through the tree of possible action sequences. Existing non-learned planning solutions from the Task and Motion Planning (TAMP) literature rely on the existence of logical descriptions for the effects and preconditions for actions. This constraint allows TAMP methods to efficiently reduce the tree search problem but limits their ability to generalize to unseen and complex physical environments. In contrast, deep reinforcement learning (DRL) methods use flexible neural-network-based function approximators to discover policies that generalize naturally to unseen circumstances. However, DRL methods struggle to handle the very sparse reward landscapes inherent to long-range multi-step planning situations. Here, we propose the Curious Sample Planner (CSP), which fuses elements of TAMP and DRL by combining a curiosity-guided sampling strategy with imitation learning to accelerate planning. We show that CSP can efficiently discover interesting and complex temporally-extended plans for solving a wide range of physically realistic 3D tasks. In contrast, standard planning and learning methods often fail to solve these tasks at all or do so only with a huge and highly variable number of training samples. We explore the use of a variety of curiosity metrics with CSP and analyze the types of solutions that CSP discovers. Finally, we show that CSP supports task transfer so that the exploration policies learned during experience with one task can help improve efficiency on related tasks.