 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow the Signs: Using Textual Cues and LLMs to Guide Efficient Robot Navigation
Jan 10, 2026Autonomous navigation in unfamiliar environments often relies on geometric mapping and planning strategies that overlook rich semantic cues such as signs, room numbers, and textual labels. We propose a novel semantic navigation framework that leverages large language models (LLMs) to infer patterns from partial observations and predict regions where the goal is most likely located. Our method combines local perceptual inputs with frontier-based exploration and periodic LLM queries, which extract symbolic patterns (e.g., room numbering schemes and building layout structures) and update a confidence grid used to guide exploration. This enables robots to move efficiently toward goal locations labeled with textual identifiers (e.g., "room 8") even before direct observation. We demonstrate that this approach enables more efficient navigation in sparse, partially observable grid environments by exploiting symbolic patterns. Experiments across environments modeled after real floor plans show that our approach consistently achieves near-optimal paths and outperforms baselines by over 25% in Success weighted by Path Length.
LLM-Guided Probabilistic Program Induction for POMDP Model Estimation
May 04, 2025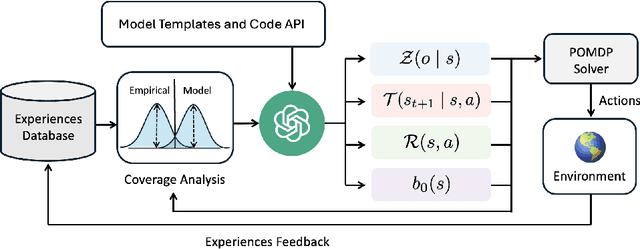



Partially Observable Markov Decision Processes (POMDPs) model decision making under uncertainty. While there are many approaches to approximately solving POMDPs, we aim to address the problem of learning such models. In particular, we are interested in a subclass of POMDPs wherein the components of the model, including the observation function, reward function, transition function, and initial state distribution function, can be modeled as low-complexity probabilistic graphical models in the form of a short probabilistic program. Our strategy to learn these programs uses an LLM as a prior, generating candidate probabilistic programs that are then tested against the empirical distribution and adjusted through feedback. We experiment on a number of classical toy POMDP problems, simulated MiniGrid domains, and two real mobile-base robotics search domains involving partial observability. Our results show that using an LLM to guide in the construction of a low-complexity POMDP model can be more effective than tabular POMDP learning, behavior cloning, or direct LLM planning.
Cognitive maps are generative programs
Apr 29, 2025Making sense of the world and acting in it relies on building simplified mental representations that abstract away aspects of reality. This principle of cognitive mapping is universal to agents with limited resources. Living organisms, people, and algorithms all face the problem of forming functional representations of their world under various computing constraints. In this work, we explore the hypothesis that human resource-efficient planning may arise from representing the world as predictably structured. Building on the metaphor of concepts as programs, we propose that cognitive maps can take the form of generative programs that exploit predictability and redundancy, in contrast to directly encoding spatial layouts. We use a behavioral experiment to show that people who navigate in structured spaces rely on modular planning strategies that align with programmatic map representations. We describe a computational model that predicts human behavior in a variety of structured scenarios. This model infers a small distribution over possible programmatic cognitive maps conditioned on human prior knowledge of the world, and uses this distribution to generate resource-efficient plans. Our models leverages a Large Language Model as an embedding of human priors, implicitly learned through training on a vast corpus of human data. Our model demonstrates improved computational efficiency, requires drastically less memory, and outperforms unstructured planning algorithms with cognitive constraints at predicting human behavior, suggesting that human planning strategies rely on programmatic cognitive maps.
Seeing is Believing: Belief-Space Planning with Foundation Models as Uncertainty Estimators
Apr 04, 2025Generalizable robotic mobile manipulation in open-world environments poses significant challenges due to long horizons, complex goals, and partial observability. A promising approach to address these challenges involves planning with a library of parameterized skills, where a task planner sequences these skills to achieve goals specified in structured languages, such as logical expressions over symbolic facts. While vision-language models (VLMs) can be used to ground these expressions, they often assume full observability, leading to suboptimal behavior when the agent lacks sufficient information to evaluate facts with certainty. This paper introduces a novel framework that leverages VLMs as a perception module to estimate uncertainty and facilitate symbolic grounding. Our approach constructs a symbolic belief representation and uses a belief-space planner to generate uncertainty-aware plans that incorporate strategic information gathering. This enables the agent to effectively reason about partial observability and property uncertainty. We demonstrate our system on a range of challenging real-world tasks that require reasoning in partially observable environments. Simulated evaluations show that our approach outperforms both vanilla VLM-based end-to-end planning or VLM-based state estimation baselines by planning for and executing strategic information gathering. This work highlights the potential of VLMs to construct belief-space symbolic scene representations, enabling downstream tasks such as uncertainty-aware planning.
Flow-based Domain Randomization for Learning and Sequencing Robotic Skills
Feb 03, 2025



Domain randomization in reinforcement learning is an established technique for increasing the robustness of control policies trained in simulation. By randomizing environment properties during training, the learned policy can become robust to uncertainties along the randomized dimensions. While the environment distribution is typically specified by hand, in this paper we investigate automatically discovering a sampling distribution via entropy-regularized reward maximization of a normalizing-flow-based neural sampling distribution. We show that this architecture is more flexible and provides greater robustness than existing approaches that learn simpler, parameterized sampling distributions, as demonstrated in six simulated and one real-world robotics domain. Lastly, we explore how these learned sampling distributions, combined with a privileged value function, can be used for out-of-distribution detection in an uncertainty-aware multi-step manipulation planner.
Hierarchical Hybrid Learning for Long-Horizon Contact-Rich Robotic Assembly
Sep 24, 2024



Generalizable long-horizon robotic assembly requires reasoning at multiple levels of abstraction. End-to-end imitation learning (IL) has been proven a promising approach, but it requires a large amount of demonstration data for training and often fails to meet the high-precision requirement of assembly tasks. Reinforcement Learning (RL) approaches have succeeded in high-precision assembly tasks, but suffer from sample inefficiency and hence, are less competent at long-horizon tasks. To address these challenges, we propose a hierarchical modular approach, named ARCH (Adaptive Robotic Composition Hierarchy), which enables long-horizon high-precision assembly in contact-rich settings. ARCH employs a hierarchical planning framework, including a low-level primitive library of continuously parameterized skills and a high-level policy. The low-level primitive library includes essential skills for assembly tasks, such as grasping and inserting. These primitives consist of both RL and model-based controllers. The high-level policy, learned via imitation learning from a handful of demonstrations, selects the appropriate primitive skills and instantiates them with continuous input parameters. We extensively evaluate our approach on a real robot manipulation platform. We show that while trained on a single task, ARCH generalizes well to unseen tasks and outperforms baseline methods in terms of success rate and data efficiency. Videos can be found at https://long-horizon-assembly.github.io.
Towards Practical Finite Sample Bounds for Motion Planning in TAMP
Jul 24, 2024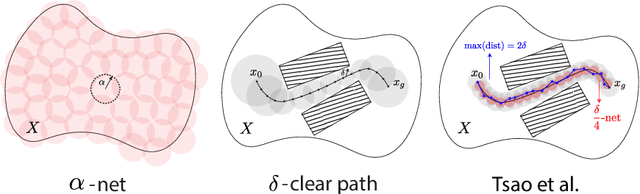
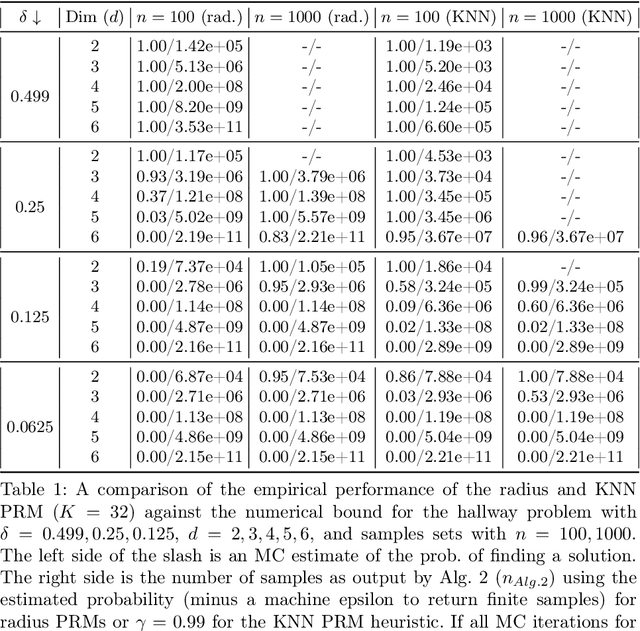
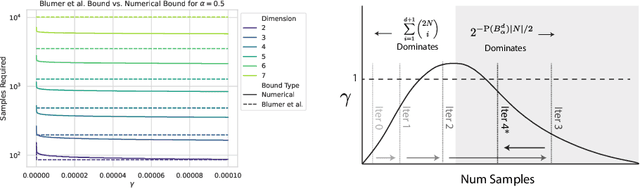
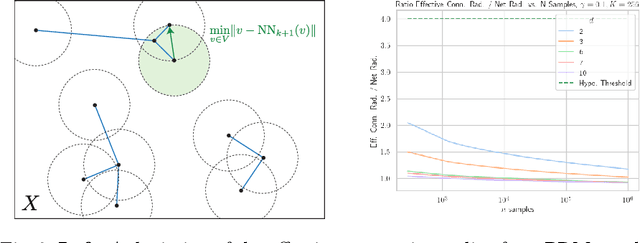
When using sampling-based motion planners, such as PRMs, in configuration spaces, it is difficult to determine how many samples are required for the PRM to find a solution consistently. This is relevant in Task and Motion Planning (TAMP), where many motion planning problems must be solved in sequence. We attempt to solve this problem by proving an upper bound on the number of samples that are sufficient, with high probability, to find a solution by drawing on prior work in deterministic sampling and sample complexity theory. We also introduce a numerical algorithm to compute a tighter number of samples based on the proof of the sample complexity theorem we apply to derive our bound. Our experiments show that our numerical bounding algorithm is tight within two orders of magnitude on planar planning problems and becomes looser as the problem's dimensionality increases. When deployed as a heuristic to schedule samples in a TAMP planner, we also observe planning time improvements in planar problems. While our experiments show much work remains to tighten our bounds, the ideas presented in this paper are a step towards a practical sample bound.
Trust the PRoC3S: Solving Long-Horizon Robotics Problems with LLMs and Constraint Satisfaction
Jun 08, 2024Recent developments in pretrained large language models (LLMs) applied to robotics have demonstrated their capacity for sequencing a set of discrete skills to achieve open-ended goals in simple robotic tasks. In this paper, we examine the topic of LLM planning for a set of continuously parameterized skills whose execution must avoid violations of a set of kinematic, geometric, and physical constraints. We prompt the LLM to output code for a function with open parameters, which, together with environmental constraints, can be viewed as a Continuous Constraint Satisfaction Problem (CCSP). This CCSP can be solved through sampling or optimization to find a skill sequence and continuous parameter settings that achieve the goal while avoiding constraint violations. Additionally, we consider cases where the LLM proposes unsatisfiable CCSPs, such as those that are kinematically infeasible, dynamically unstable, or lead to collisions, and re-prompt the LLM to form a new CCSP accordingly. Experiments across three different simulated 3D domains demonstrate that our proposed strategy, PRoC3S, is capable of solving a wide range of complex manipulation tasks with realistic constraints on continuous parameters much more efficiently and effectively than existing baselines.
Partially Observable Task and Motion Planning with Uncertainty and Risk Awareness
Mar 15, 2024

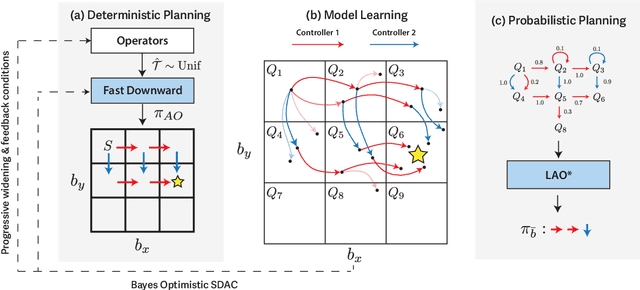

Integrated task and motion planning (TAMP) has proven to be a valuable approach to generalizable long-horizon robotic manipulation and navigation problems. However, the typical TAMP problem formulation assumes full observability and deterministic action effects. These assumptions limit the ability of the planner to gather information and make decisions that are risk-aware. We propose a strategy for TAMP with Uncertainty and Risk Awareness (TAMPURA) that is capable of efficiently solving long-horizon planning problems with initial-state and action outcome uncertainty, including problems that require information gathering and avoiding undesirable and irreversible outcomes. Our planner reasons under uncertainty at both the abstract task level and continuous controller level. Given a set of closed-loop goal-conditioned controllers operating in the primitive action space and a description of their preconditions and potential capabilities, we learn a high-level abstraction that can be solved efficiently and then refined to continuous actions for execution. We demonstrate our approach on several robotics problems where uncertainty is a crucial factor and show that reasoning under uncertainty in these problems outperforms previously proposed determinized planning, direct search, and reinforcement learning strategies. Lastly, we demonstrate our planner on two real-world robotics problems using recent advancements in probabilistic perception.
Bayes3D: fast learning and inference in structured generative models of 3D objects and scenes
Dec 14, 2023



Robots cannot yet match humans' ability to rapidly learn the shapes of novel 3D objects and recognize them robustly despite clutter and occlusion. We present Bayes3D, an uncertainty-aware perception system for structured 3D scenes, that reports accurate posterior uncertainty over 3D object shape, pose, and scene composition in the presence of clutter and occlusion. Bayes3D delivers these capabilities via a novel hierarchical Bayesian model for 3D scenes and a GPU-accelerated coarse-to-fine sequential Monte Carlo algorithm. Quantitative experiments show that Bayes3D can learn 3D models of novel objects from just a handful of views, recognizing them more robustly and with orders of magnitude less training data than neural baselines, and tracking 3D objects faster than real time on a single GPU. We also demonstrate that Bayes3D learns complex 3D object models and accurately infers 3D scene composition when used on a Panda robot in a tabletop scenario.