 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Under Ignorance in Universal Artificial Intelligence
Dec 18, 2025We generalize the AIXI reinforcement learning agent to admit a wider class of utility functions. Assigning a utility to each possible interaction history forces us to confront the ambiguity that some hypotheses in the agent's belief distribution only predict a finite prefix of the history, which is sometimes interpreted as implying a chance of death equal to a quantity called the semimeasure loss. This death interpretation suggests one way to assign utilities to such history prefixes. We argue that it is as natural to view the belief distributions as imprecise probability distributions, with the semimeasure loss as total ignorance. This motivates us to consider the consequences of computing expected utilities with Choquet integrals from imprecise probability theory, including an investigation of their computability level. We recover the standard recursive value function as a special case. However, our most general expected utilities under the death interpretation cannot be characterized as such Choquet integrals.
Formalizing Embeddedness Failures in Universal Artificial Intelligence
May 23, 2025We rigorously discuss the commonly asserted failures of the AIXI reinforcement learning agent as a model of embedded agency. We attempt to formalize these failure modes and prove that they occur within the framework of universal artificial intelligence, focusing on a variant of AIXI that models the joint action/percept history as drawn from the universal distribution. We also evaluate the progress that has been made towards a successful theory of embedded agency based on variants of the AIXI agent.
Cognitive maps are generative programs
Apr 29, 2025Making sense of the world and acting in it relies on building simplified mental representations that abstract away aspects of reality. This principle of cognitive mapping is universal to agents with limited resources. Living organisms, people, and algorithms all face the problem of forming functional representations of their world under various computing constraints. In this work, we explore the hypothesis that human resource-efficient planning may arise from representing the world as predictably structured. Building on the metaphor of concepts as programs, we propose that cognitive maps can take the form of generative programs that exploit predictability and redundancy, in contrast to directly encoding spatial layouts. We use a behavioral experiment to show that people who navigate in structured spaces rely on modular planning strategies that align with programmatic map representations. We describe a computational model that predicts human behavior in a variety of structured scenarios. This model infers a small distribution over possible programmatic cognitive maps conditioned on human prior knowledge of the world, and uses this distribution to generate resource-efficient plans. Our models leverages a Large Language Model as an embedding of human priors, implicitly learned through training on a vast corpus of human data. Our model demonstrates improved computational efficiency, requires drastically less memory, and outperforms unstructured planning algorithms with cognitive constraints at predicting human behavior, suggesting that human planning strategies rely on programmatic cognitive maps.
Understanding is Compression
Jun 24, 2024We have previously shown all understanding or learning are compression, under reasonable assumptions. In principle, better understanding of data should improve data compression. Traditional compression methodologies focus on encoding frequencies or some other computable properties of data. Large language models approximate the uncomputable Solomonoff distribution, opening up a whole new avenue to justify our theory. Under the new uncomputable paradigm, we present LMCompress based on the understanding of data using large models. LMCompress has significantly better lossless compression ratios than all other lossless data compression methods, doubling the compression ratios of JPEG-XL for images, FLAC for audios and H264 for videos, and tripling or quadrupling the compression ratio of bz2 for texts. The better a large model understands the data, the better LMCompress compresses.
A Circuit Complexity Formulation of Algorithmic Information Theory
Jun 25, 2023Inspired by Solomonoffs theory of inductive inference, we propose a prior based on circuit complexity. There are several advantages to this approach. First, it relies on a complexity measure that does not depend on the choice of UTM. There is one universal definition for Boolean circuits involving an universal operation such as nand with simple conversions to alternative definitions such as and, or, and not. Second, there is no analogue of the halting problem. The output value of a circuit can be calculated recursively by computer in time proportional to the number of gates, while a short program may run for a very long time. Our prior assumes that a Boolean function, or equivalently, Boolean string of fixed length, is generated by some Bayesian mixture of circuits. This model is appropriate for learning Boolean functions from partial information, a problem often encountered within machine learning as "binary classification." We argue that an inductive bias towards simple explanations as measured by circuit complexity is appropriate for this problem.
Robust Group Synchronization via Quadratic Programming
Jun 17, 2022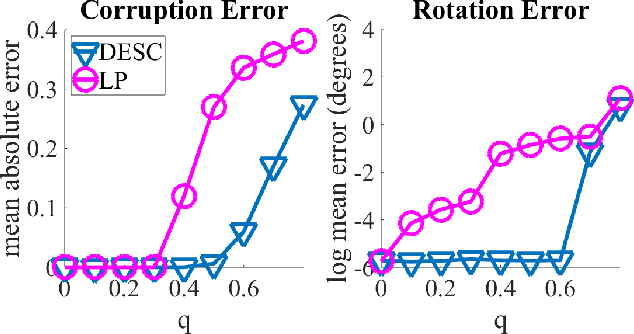
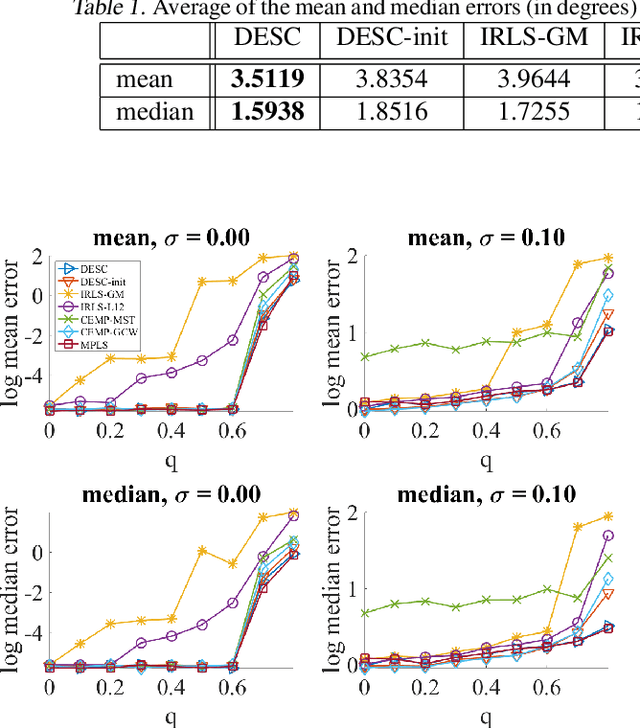
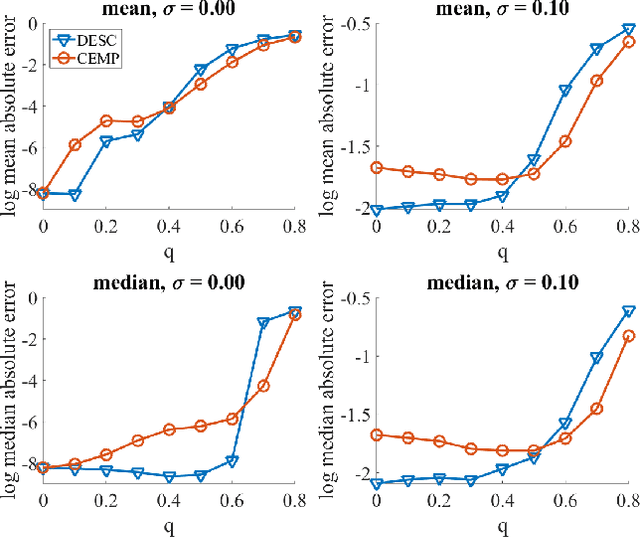
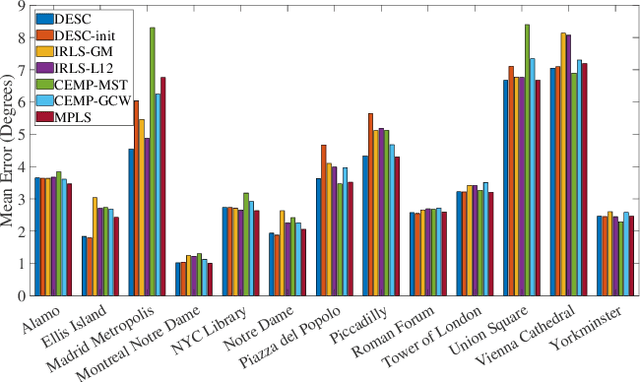
We propose a novel quadratic programming formulation for estimating the corruption levels in group synchronization, and use these estimates to solve this problem. Our objective function exploits the cycle consistency of the group and we thus refer to our method as detection and estimation of structural consistency (DESC). This general framework can be extended to other algebraic and geometric structures. Our formulation has the following advantages: it can tolerate corruption as high as the information-theoretic bound, it does not require a good initialization for the estimates of group elements, it has a simple interpretation, and under some mild conditions the global minimum of our objective function exactly recovers the corruption levels. We demonstrate the competitive accuracy of our approach on both synthetic and real data experiments of rotation averaging.
Semantically-Aware Strategies for Stereo-Visual Robotic Obstacle Avoidance
Jul 13, 2021

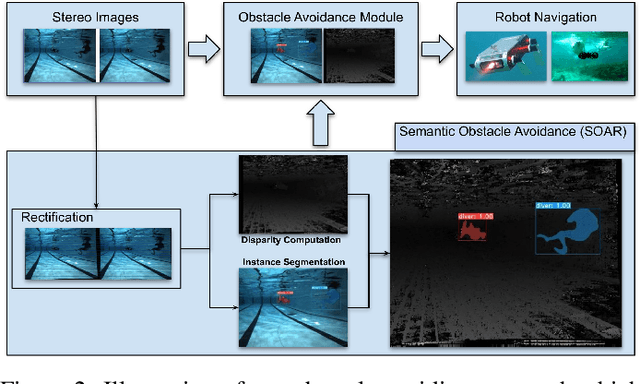
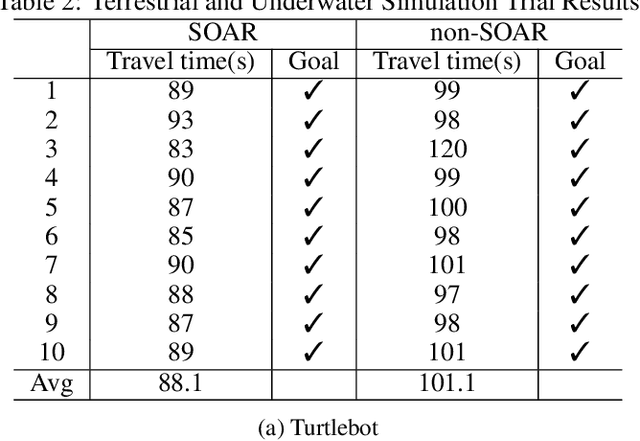
Mobile robots in unstructured, mapless environments must rely on an obstacle avoidance module to navigate safely. The standard avoidance techniques estimate the locations of obstacles with respect to the robot but are unaware of the obstacles' identities. Consequently, the robot cannot take advantage of semantic information about obstacles when making decisions about how to navigate. We propose an obstacle avoidance module that combines visual instance segmentation with a depth map to classify and localize objects in the scene. The system avoids obstacles differentially, based on the identity of the objects: for example, the system is more cautious in response to unpredictable objects such as humans. The system can also navigate closer to harmless obstacles and ignore obstacles that pose no collision danger, enabling it to navigate more efficiently. We validate our approach in two simulated environments: one terrestrial and one underwater. Results indicate that our approach is feasible and can enable more efficient navigation strategies.