 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sharp Phase Transition of Tyler's M-Estimator for Robust Subspace Recovery
Jun 04, 2026Robust Subspace Recovery (RSR) aims to identify an underlying d-dimensional subspace from a dataset heavily corrupted by outliers. Complexity-theoretic results establish a threshold for the problem's computational hardness based on the dimension-scaled signal-to-noise ratio (DS-SNR): the problem is SSE-hard when the DS-SNR is strictly less than 1, and solvable via practical algorithms when it is greater than 1 under general position assumptions. However, the exact behavior of practical algorithms at the critical boundary DS-SNR = 1 has remained unknown. This work resolves the behavior of Tyler's M-estimator (TME) at this critical boundary, consequently establishing a sharp phase transition. Specifically, we prove that TME converges exactly to the true subspace for DS-SNR \geq 1 under a new stability condition, which is less restrictive than the general position assumptions used in prior literature. Our analysis utilizes a decomposition of the TME iterates within a majorization-minimization framework.
Understanding Latent Diffusability via Fisher Geometry
Apr 03, 2026Diffusion models often degrade when trained in latent spaces (e.g., VAEs), yet the formal causes remain poorly understood. We quantify latent-space diffusability through the rate of change of the Minimum Mean Squared Error (MMSE) along the diffusion trajectory. Our framework decomposes this MMSE rate into contributions from Fisher Information (FI) and Fisher Information Rate (FIR). We demonstrate that while global isometry ensures FI alignment, FIR is governed by the encoder's local geometric properties. Our analysis explicitly decouples latent geometric distortion into three measurable penalties: dimensional compression, tangential distortion, and curvature injection. We derive theoretical conditions for FIR preservation across spaces, ensuring maintained diffusability. Experiments across diverse autoencoding architectures validate our framework and establish these efficient FI and FIR metrics as a robust diagnostic suite for identifying and mitigating latent diffusion failure.
QuadSync: Quadrifocal Tensor Synchronization via Tucker Decomposition
Feb 26, 2026In structure from motion, quadrifocal tensors capture more information than their pairwise counterparts (essential matrices), yet they have often been thought of as impractical and only of theoretical interest. In this work, we challenge such beliefs by providing a new framework to recover $n$ cameras from the corresponding collection of quadrifocal tensors. We form the block quadrifocal tensor and show that it admits a Tucker decomposition whose factor matrices are the stacked camera matrices, and which thus has a multilinear rank of (4,~4,~4,~4) independent of $n$. We develop the first synchronization algorithm for quadrifocal tensors, using Tucker decomposition, alternating direction method of multipliers, and iteratively reweighted least squares. We further establish relationships between the block quadrifocal, trifocal, and bifocal tensors, and introduce an algorithm that jointly synchronizes these three entities. Numerical experiments demonstrate the effectiveness of our methods on modern datasets, indicating the potential and importance of using higher-order information in synchronization.
Learning to Charge More: A Theoretical Study of Collusion by Q-Learning Agents
May 28, 2025There is growing experimental evidence that $Q$-learning agents may learn to charge supracompetitive prices. We provide the first theoretical explanation for this behavior in infinite repeated games. Firms update their pricing policies based solely on observed profits, without computing equilibrium strategies. We show that when the game admits both a one-stage Nash equilibrium price and a collusive-enabling price, and when the $Q$-function satisfies certain inequalities at the end of experimentation, firms learn to consistently charge supracompetitive prices. We introduce a new class of one-memory subgame perfect equilibria (SPEs) and provide conditions under which learned behavior is supported by naive collusion, grim trigger policies, or increasing strategies. Naive collusion does not constitute an SPE unless the collusive-enabling price is a one-stage Nash equilibrium, whereas grim trigger policies can.
Stein Discrepancy for Unsupervised Domain Adaptation
Feb 05, 2025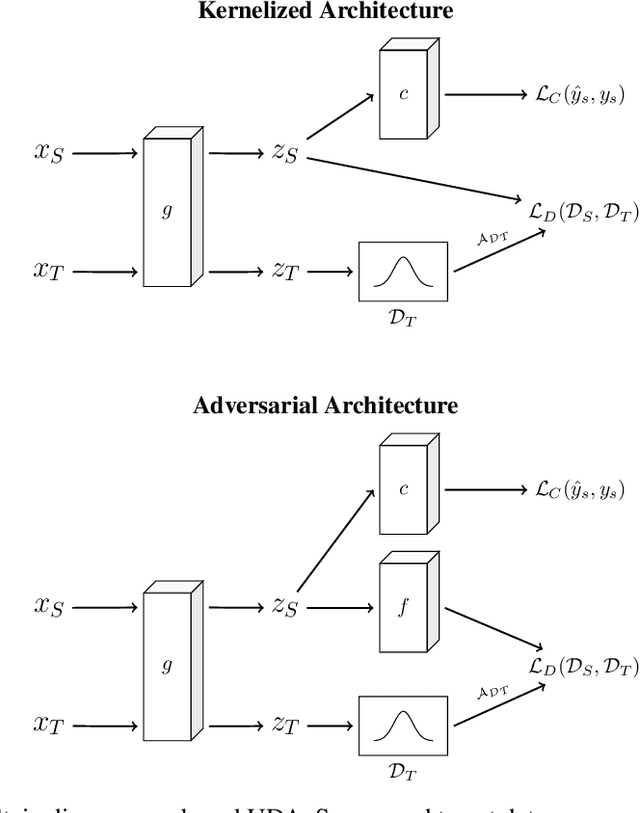
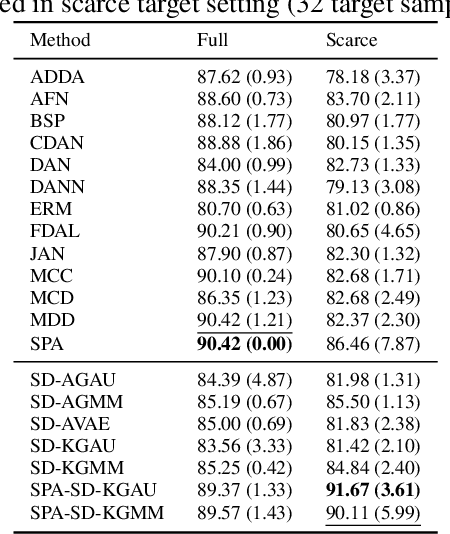
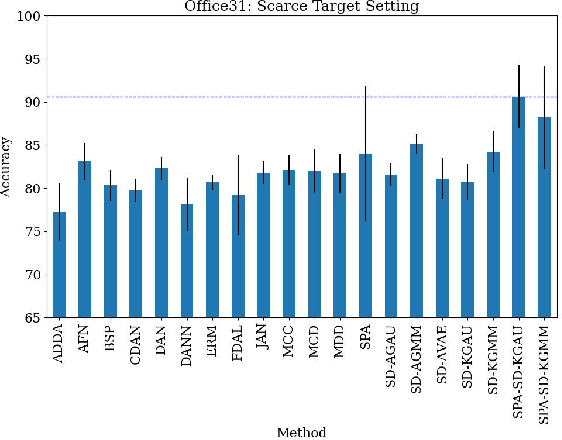
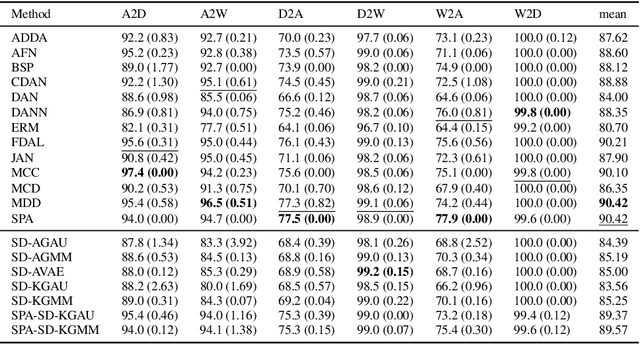
Unsupervised domain adaptation (UDA) leverages information from a labeled source dataset to improve accuracy on a related but unlabeled target dataset. A common approach to UDA is aligning representations from the source and target domains by minimizing the distance between their data distributions. Previous methods have employed distances such as Wasserstein distance and maximum mean discrepancy. However, these approaches are less effective when the target data is significantly scarcer than the source data. Stein discrepancy is an asymmetric distance between distributions that relies on one distribution only through its score function. In this paper, we propose a novel \ac{uda} method that uses Stein discrepancy to measure the distance between source and target domains. We develop a learning framework using both non-kernelized and kernelized Stein discrepancy. Theoretically, we derive an upper bound for the generalization error. Numerical experiments show that our method outperforms existing methods using other domain discrepancy measures when only small amounts of target data are available.
Tensor-Based Synchronization and the Low-Rankness of the Block Trifocal Tensor
Sep 14, 2024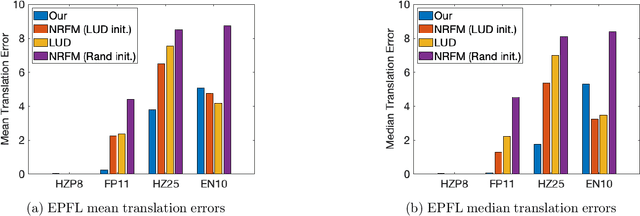
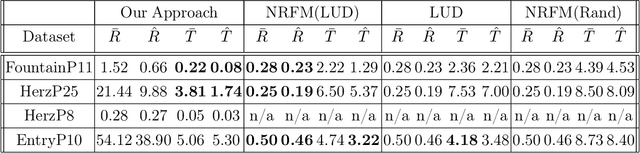
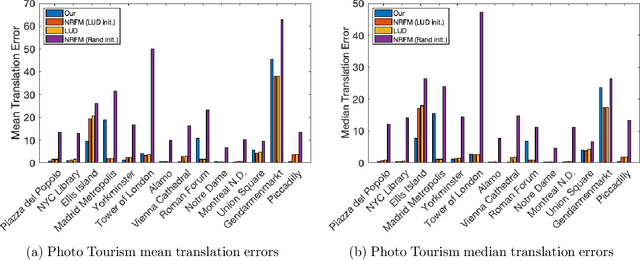
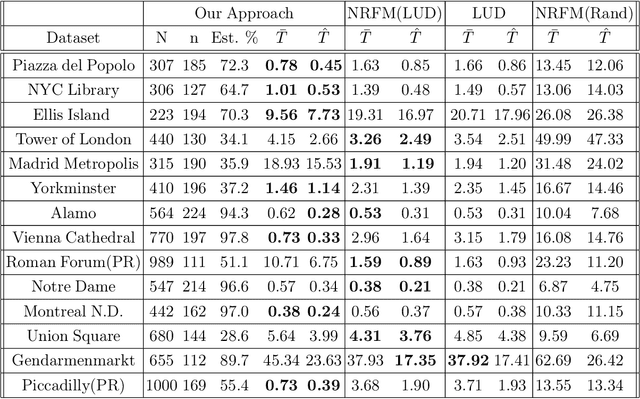
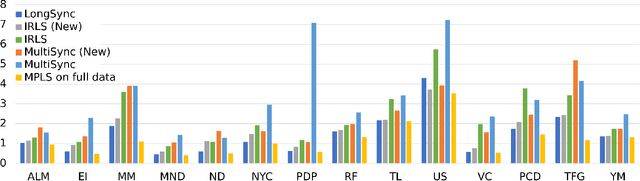
The block tensor of trifocal tensors provides crucial geometric information on the three-view geometry of a scene. The underlying synchronization problem seeks to recover camera poses (locations and orientations up to a global transformation) from the block trifocal tensor. We establish an explicit Tucker factorization of this tensor, revealing a low multilinear rank of $(6,4,4)$ independent of the number of cameras under appropriate scaling conditions. We prove that this rank constraint provides sufficient information for camera recovery in the noiseless case. The constraint motivates a synchronization algorithm based on the higher-order singular value decomposition of the block trifocal tensor. Experimental comparisons with state-of-the-art global synchronization methods on real datasets demonstrate the potential of this algorithm for significantly improving location estimation accuracy. Overall this work suggests that higher-order interactions in synchronization problems can be exploited to improve performance, beyond the usual pairwise-based approaches.
Improving Hyperbolic Representations via Gromov-Wasserstein Regularization
Jul 15, 2024
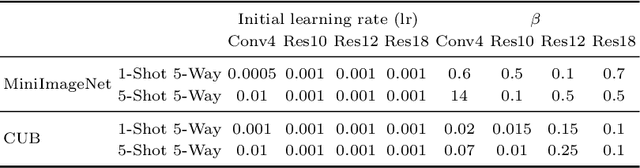
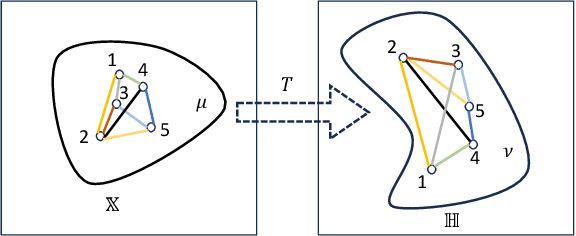
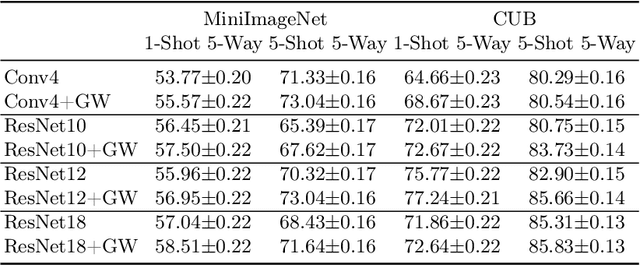
Hyperbolic representations have shown remarkable efficacy in modeling inherent hierarchies and complexities within data structures. Hyperbolic neural networks have been commonly applied for learning such representations from data, but they often fall short in preserving the geometric structures of the original feature spaces. In response to this challenge, our work applies the Gromov-Wasserstein (GW) distance as a novel regularization mechanism within hyperbolic neural networks. The GW distance quantifies how well the original data structure is maintained after embedding the data in a hyperbolic space. Specifically, we explicitly treat the layers of the hyperbolic neural networks as a transport map and calculate the GW distance accordingly. We validate that the GW distance computed based on a training set well approximates the GW distance of the underlying data distribution. Our approach demonstrates consistent enhancements over current state-of-the-art methods across various tasks, including few-shot image classification, as well as semi-supervised graph link prediction and node classification.
Efficient Detection of Long Consistent Cycles and its Application to Distributed Synchronization
Jul 05, 2024
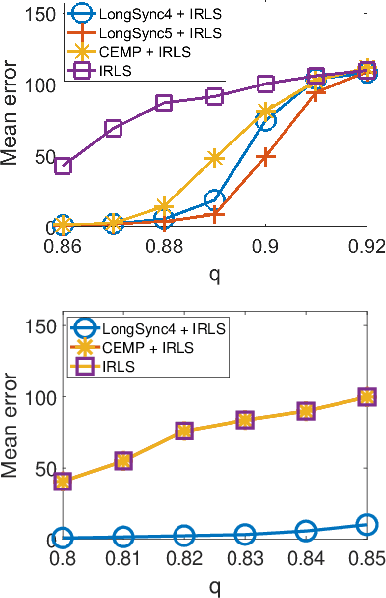

Group synchronization plays a crucial role in global pipelines for Structure from Motion (SfM). Its formulation is nonconvex and it is faced with highly corrupted measurements. Cycle consistency has been effective in addressing these challenges. However, computationally efficient solutions are needed for cycles longer than three, especially in practical scenarios where 3-cycles are unavailable. To overcome this computational bottleneck, we propose an algorithm for group synchronization that leverages information from cycles of lengths ranging from three to six with a time complexity of order $O(n^3)$ (or $O(n^{2.373})$ when using a faster matrix multiplication algorithm). We establish non-trivial theory for this and related methods that achieves competitive sample complexity, assuming the uniform corruption model. To advocate the practical need for our method, we consider distributed group synchronization, which requires at least 4-cycles, and we illustrate state-of-the-art performance by our method in this context.
Artificial Intelligence and Algorithmic Price Collusion in Two-sided Markets
Jul 04, 2024



Algorithmic price collusion facilitated by artificial intelligence (AI) algorithms raises significant concerns. We examine how AI agents using Q-learning engage in tacit collusion in two-sided markets. Our experiments reveal that AI-driven platforms achieve higher collusion levels compared to Bertrand competition. Increased network externalities significantly enhance collusion, suggesting AI algorithms exploit them to maximize profits. Higher user heterogeneity or greater utility from outside options generally reduce collusion, while higher discount rates increase it. Tacit collusion remains feasible even at low discount rates. To mitigate collusive behavior and inform potential regulatory measures, we propose incorporating a penalty term in the Q-learning algorithm.
A Subspace-Constrained Tyler's Estimator and its Applications to Structure from Motion
Apr 17, 2024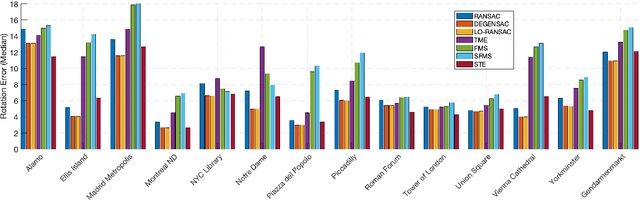
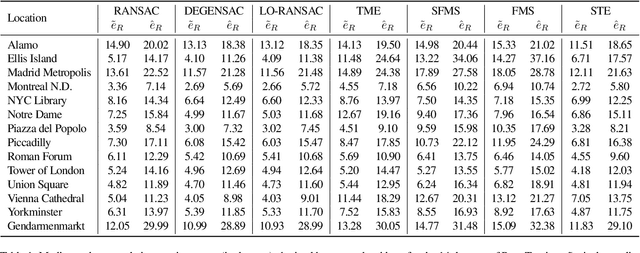
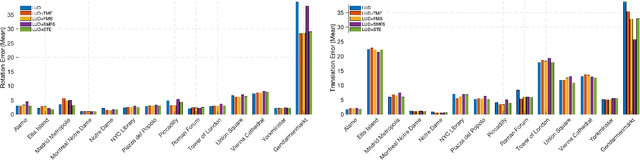
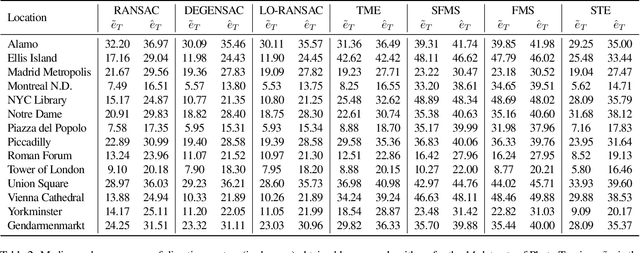
We present the subspace-constrained Tyler's estimator (STE) designed for recovering a low-dimensional subspace within a dataset that may be highly corrupted with outliers. STE is a fusion of the Tyler's M-estimator (TME) and a variant of the fast median subspace. Our theoretical analysis suggests that, under a common inlier-outlier model, STE can effectively recover the underlying subspace, even when it contains a smaller fraction of inliers relative to other methods in the field of robust subspace recovery. We apply STE in the context of Structure from Motion (SfM) in two ways: for robust estimation of the fundamental matrix and for the removal of outlying cameras, enhancing the robustness of the SfM pipeline. Numerical experiments confirm the state-of-the-art performance of our method in these applications. This research makes significant contributions to the field of robust subspace recovery, particularly in the context of computer vision and 3D reconstruction.