 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMPhy: Complex Physical Reasoning Using Large Language Models and World Models
Nov 12, 2024Physical reasoning is an important skill needed for robotic agents when operating in the real world. However, solving such reasoning problems often involves hypothesizing and reflecting over complex multi-body interactions under the effect of a multitude of physical forces and thus learning all such interactions poses a significant hurdle for state-of-the-art machine learning frameworks, including large language models (LLMs). To study this problem, we propose a new physical reasoning task and a dataset, dubbed TraySim. Our task involves predicting the dynamics of several objects on a tray that is given an external impact -- the domino effect of the ensued object interactions and their dynamics thus offering a challenging yet controlled setup, with the goal of reasoning being to infer the stability of the objects after the impact. To solve this complex physical reasoning task, we present LLMPhy, a zero-shot black-box optimization framework that leverages the physics knowledge and program synthesis abilities of LLMs, and synergizes these abilities with the world models built into modern physics engines. Specifically, LLMPhy uses an LLM to generate code to iteratively estimate the physical hyperparameters of the system (friction, damping, layout, etc.) via an implicit analysis-by-synthesis approach using a (non-differentiable) simulator in the loop and uses the inferred parameters to imagine the dynamics of the scene towards solving the reasoning task. To show the effectiveness of LLMPhy, we present experiments on our TraySim dataset to predict the steady-state poses of the objects. Our results show that the combination of the LLM and the physics engine leads to state-of-the-art zero-shot physical reasoning performance, while demonstrating superior convergence against standard black-box optimization methods and better estimation of the physical parameters.
Open Human-Robot Collaboration using Decentralized Inverse Reinforcement Learning
Oct 02, 2024
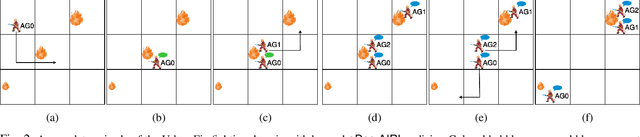


The growing interest in human-robot collaboration (HRC), where humans and robots cooperate towards shared goals, has seen significant advancements over the past decade. While previous research has addressed various challenges, several key issues remain unresolved. Many domains within HRC involve activities that do not necessarily require human presence throughout the entire task. Existing literature typically models HRC as a closed system, where all agents are present for the entire duration of the task. In contrast, an open model offers flexibility by allowing an agent to enter and exit the collaboration as needed, enabling them to concurrently manage other tasks. In this paper, we introduce a novel multiagent framework called oDec-MDP, designed specifically to model open HRC scenarios where agents can join or leave tasks flexibly during execution. We generalize a recent multiagent inverse reinforcement learning method - Dec-AIRL to learn from open systems modeled using the oDec-MDP. Our method is validated through experiments conducted in both a simplified toy firefighting domain and a realistic dyadic human-robot collaborative assembly. Results show that our framework and learning method improves upon its closed system counterpart.
DECAF: a Discrete-Event based Collaborative Human-Robot Framework for Furniture Assembly
Aug 28, 2024
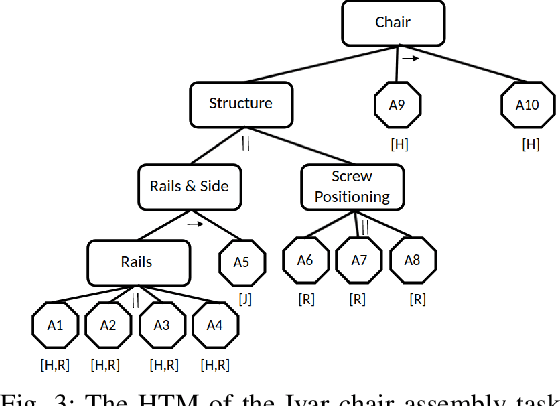
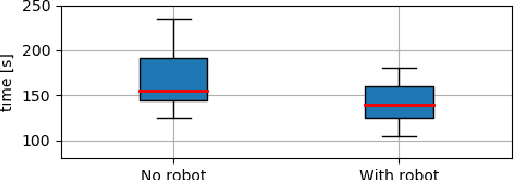
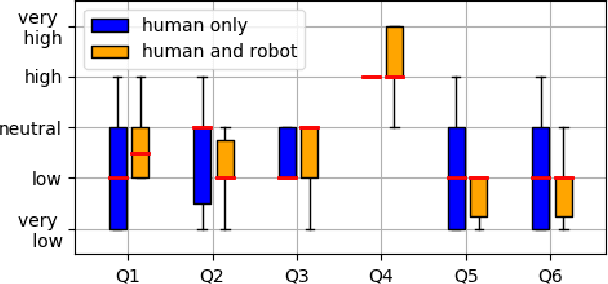
This paper proposes a task planning framework for collaborative Human-Robot scenarios, specifically focused on assembling complex systems such as furniture. The human is characterized as an uncontrollable agent, implying for example that the agent is not bound by a pre-established sequence of actions and instead acts according to its own preferences. Meanwhile, the task planner computes reactively the optimal actions for the collaborative robot to efficiently complete the entire assembly task in the least time possible. We formalize the problem as a Discrete Event Markov Decision Problem (DE-MDP), a comprehensive framework that incorporates a variety of asynchronous behaviors, human change of mind and failure recovery as stochastic events. Although the problem could theoretically be addressed by constructing a graph of all possible actions, such an approach would be constrained by computational limitations. The proposed formulation offers an alternative solution utilizing Reinforcement Learning to derive an optimal policy for the robot. Experiments where conducted both in simulation and on a real system with human subjects assembling a chair in collaboration with a 7-DoF manipulator.
Autonomous Robotic Assembly: From Part Singulation to Precise Assembly
Jun 11, 2024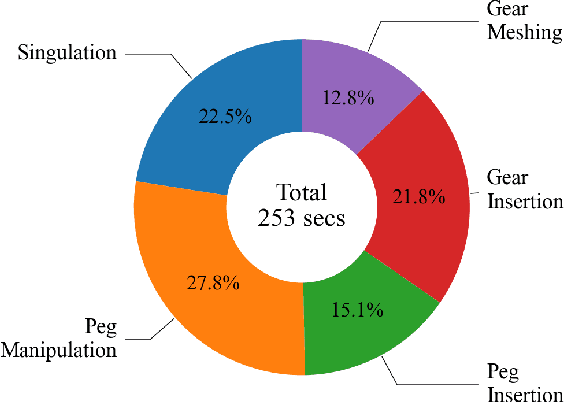
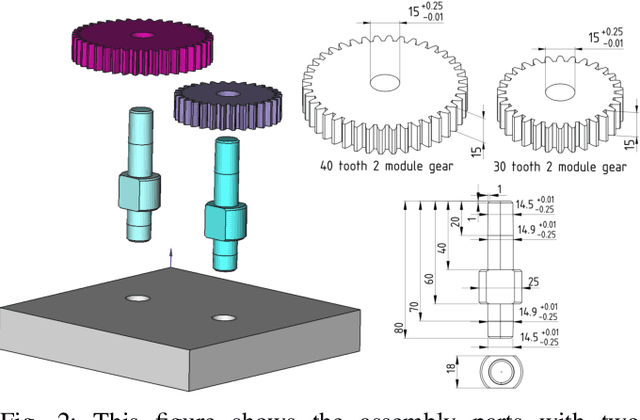


Imagine a robot that can assemble a functional product from the individual parts presented in any configuration to the robot. Designing such a robotic system is a complex problem which presents several open challenges. To bypass these challenges, the current generation of assembly systems is built with a lot of system integration effort to provide the structure and precision necessary for assembly. These systems are mostly responsible for part singulation, part kitting, and part detection, which is accomplished by intelligent system design. In this paper, we present autonomous assembly of a gear box with minimum requirements on structure. The assembly parts are randomly placed in a two-dimensional work environment for the robot. The proposed system makes use of several different manipulation skills such as sliding for grasping, in-hand manipulation, and insertion to assemble the gear box. All these tasks are run in a closed-loop fashion using vision, tactile, and Force-Torque (F/T) sensors. We perform extensive hardware experiments to show the robustness of the proposed methods as well as the overall system. See supplementary video at https://www.youtube.com/watch?v=cZ9M1DQ23OI.
Interactive Planning Using Large Language Models for Partially Observable Robotics Tasks
Dec 11, 2023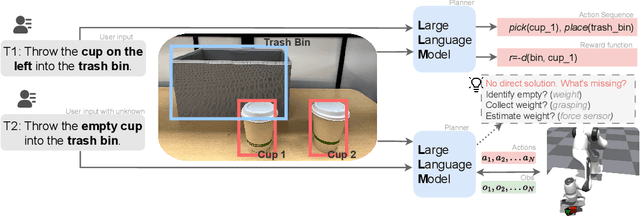



Designing robotic agents to perform open vocabulary tasks has been the long-standing goal in robotics and AI. Recently, Large Language Models (LLMs) have achieved impressive results in creating robotic agents for performing open vocabulary tasks. However, planning for these tasks in the presence of uncertainties is challenging as it requires \enquote{chain-of-thought} reasoning, aggregating information from the environment, updating state estimates, and generating actions based on the updated state estimates. In this paper, we present an interactive planning technique for partially observable tasks using LLMs. In the proposed method, an LLM is used to collect missing information from the environment using a robot and infer the state of the underlying problem from collected observations while guiding the robot to perform the required actions. We also use a fine-tuned Llama 2 model via self-instruct and compare its performance against a pre-trained LLM like GPT-4. Results are demonstrated on several tasks in simulation as well as real-world environments. A video describing our work along with some results could be found here.
EARL: Eye-on-Hand Reinforcement Learner for Dynamic Grasping with Active Pose Estimation
Oct 10, 2023
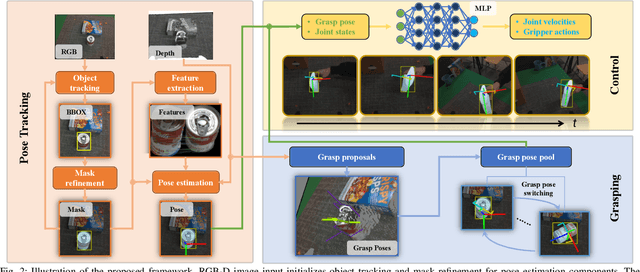
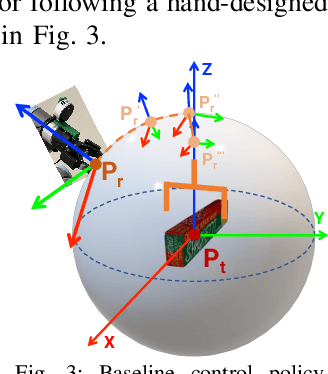
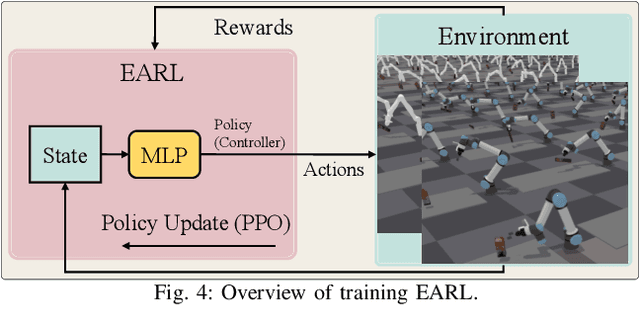
In this paper, we explore the dynamic grasping of moving objects through active pose tracking and reinforcement learning for hand-eye coordination systems. Most existing vision-based robotic grasping methods implicitly assume target objects are stationary or moving predictably. Performing grasping of unpredictably moving objects presents a unique set of challenges. For example, a pre-computed robust grasp can become unreachable or unstable as the target object moves, and motion planning must also be adaptive. In this work, we present a new approach, Eye-on-hAnd Reinforcement Learner (EARL), for enabling coupled Eye-on-Hand (EoH) robotic manipulation systems to perform real-time active pose tracking and dynamic grasping of novel objects without explicit motion prediction. EARL readily addresses many thorny issues in automated hand-eye coordination, including fast-tracking of 6D object pose from vision, learning control policy for a robotic arm to track a moving object while keeping the object in the camera's field of view, and performing dynamic grasping. We demonstrate the effectiveness of our approach in extensive experiments validated on multiple commercial robotic arms in both simulations and complex real-world tasks.
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos
Jun 27, 2023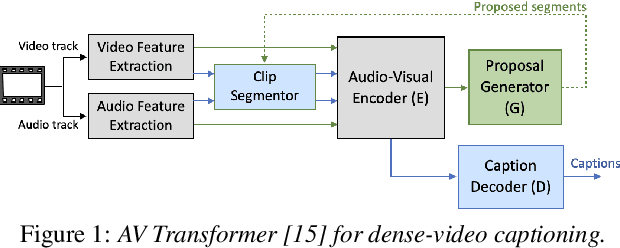

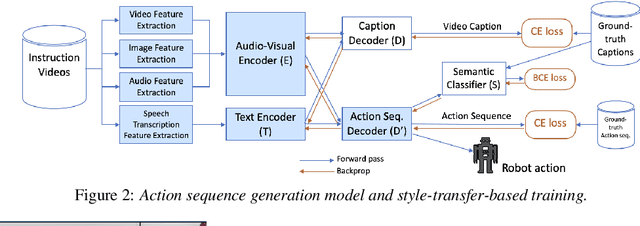
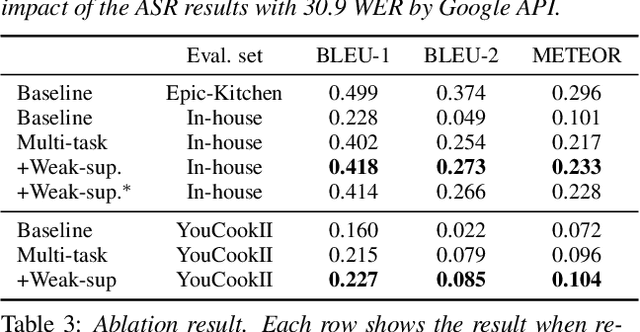
To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
Learning Generalizable Pivoting Skills
May 04, 2023The skill of pivoting an object with a robotic system is challenging for the external forces that act on the system, mainly given by contact interaction. The complexity increases when the same skills are required to generalize across different objects. This paper proposes a framework for learning robust and generalizable pivoting skills, which consists of three steps. First, we learn a pivoting policy on an ``unitary'' object using Reinforcement Learning (RL). Then, we obtain the object's feature space by supervised learning to encode the kinematic properties of arbitrary objects. Finally, to adapt the unitary policy to multiple objects, we learn data-driven projections based on the object features to adjust the state and action space of the new pivoting task. The proposed approach is entirely trained in simulation. It requires only one depth image of the object and can zero-shot transfer to real-world objects. We demonstrate robustness to sim-to-real transfer and generalization to multiple objects.
Task-Directed Exploration in Continuous POMDPs for Robotic Manipulation of Articulated Objects
Dec 08, 2022
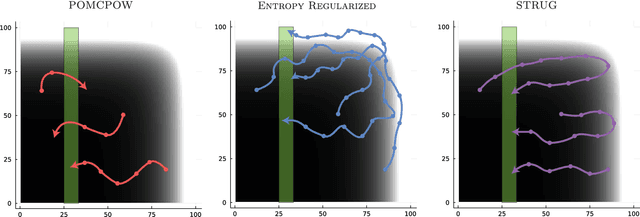


Representing and reasoning about uncertainty is crucial for autonomous agents acting in partially observable environments with noisy sensors. Partially observable Markov decision processes (POMDPs) serve as a general framework for representing problems in which uncertainty is an important factor. Online sample-based POMDP methods have emerged as efficient approaches to solving large POMDPs and have been shown to extend to continuous domains. However, these solutions struggle to find long-horizon plans in problems with significant uncertainty. Exploration heuristics can help guide planning, but many real-world settings contain significant task-irrelevant uncertainty that might distract from the task objective. In this paper, we propose STRUG, an online POMDP solver capable of handling domains that require long-horizon planning with significant task-relevant and task-irrelevant uncertainty. We demonstrate our solution on several temporally extended versions of toy POMDP problems as well as robotic manipulation of articulated objects using a neural perception frontend to construct a distribution of possible models. Our results show that STRUG outperforms the current sample-based online POMDP solvers on several tasks.
Generalizable Human-Robot Collaborative Assembly Using Imitation Learning and Force Control
Dec 02, 2022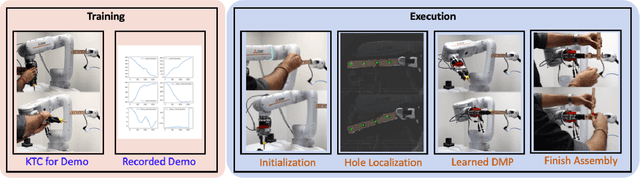
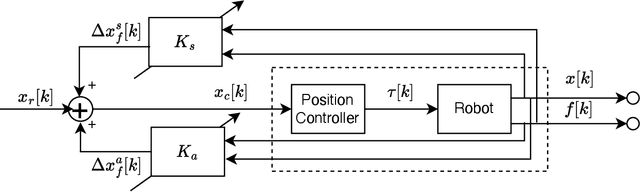
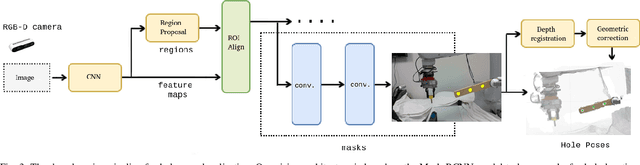

Robots have been steadily increasing their presence in our daily lives, where they can work along with humans to provide assistance in various tasks on industry floors, in offices, and in homes. Automated assembly is one of the key applications of robots, and the next generation assembly systems could become much more efficient by creating collaborative human-robot systems. However, although collaborative robots have been around for decades, their application in truly collaborative systems has been limited. This is because a truly collaborative human-robot system needs to adjust its operation with respect to the uncertainty and imprecision in human actions, ensure safety during interaction, etc. In this paper, we present a system for human-robot collaborative assembly using learning from demonstration and pose estimation, so that the robot can adapt to the uncertainty caused by the operation of humans. Learning from demonstration is used to generate motion trajectories for the robot based on the pose estimate of different goal locations from a deep learning-based vision system. The proposed system is demonstrated using a physical 6 DoF manipulator in a collaborative human-robot assembly scenario. We show successful generalization of the system's operation to changes in the initial and final goal locations through various experiments.