 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEFT: Bias-Efficient Fine-Tuning of Language Models
Sep 19, 2025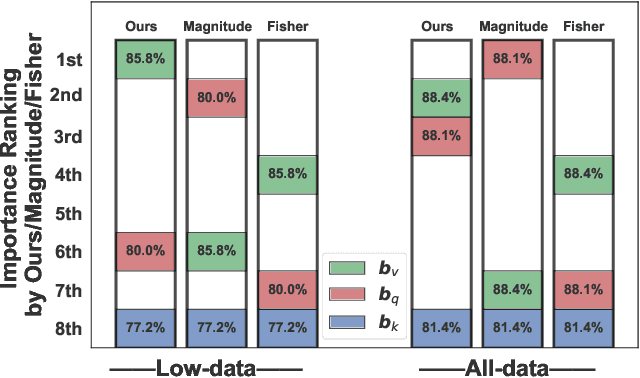
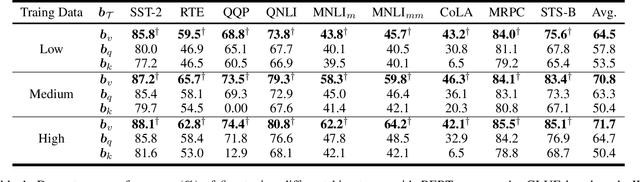
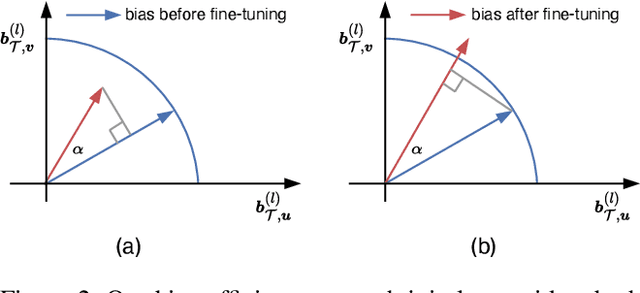

Fine-tuning all-bias-terms stands out among various parameter-efficient fine-tuning (PEFT) techniques, owing to its out-of-the-box usability and competitive performance, especially in low-data regimes. Bias-only fine-tuning has the potential for unprecedented parameter efficiency. However, the link between fine-tuning different bias terms (i.e., bias terms in the query, key, or value projections) and downstream performance remains unclear. The existing approaches, e.g., based on the magnitude of bias change or empirical Fisher information, provide limited guidance for selecting the particular bias term for effective fine-tuning. In this paper, we propose an approach for selecting the bias term to be fine-tuned, forming the foundation of our bias-efficient fine-tuning (BEFT). We extensively evaluate our bias-efficient approach against other bias-selection approaches, across a wide range of large language models (LLMs) spanning encoder-only and decoder-only architectures from 110M to 6.7B parameters. Our results demonstrate the effectiveness and superiority of our bias-efficient approach on diverse downstream tasks, including classification, multiple-choice, and generation tasks.
Efficiently Manipulating Clutter via Learning and Search-Based Reasoning
May 13, 2025
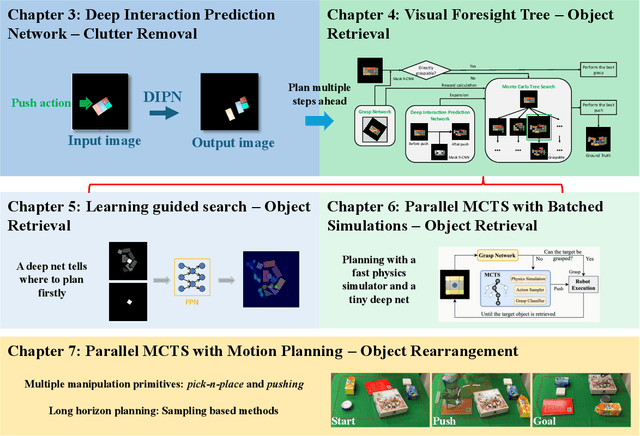
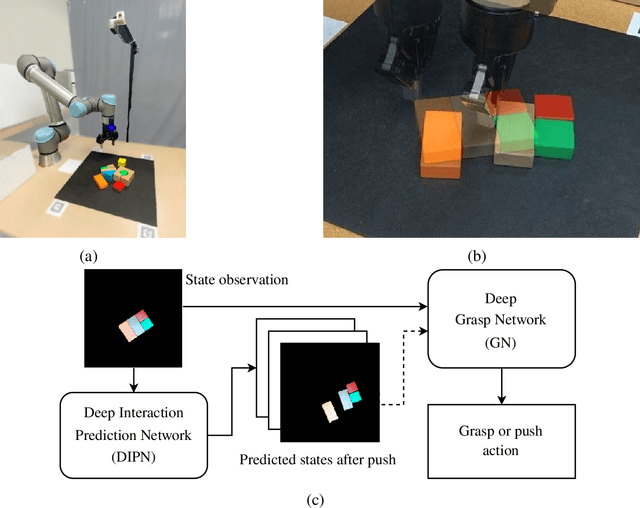
This thesis presents novel algorithms to advance robotic object rearrangement, a critical task for autonomous systems in applications like warehouse automation and household assistance. Addressing challenges of high-dimensional planning, complex object interactions, and computational demands, our work integrates deep learning for interaction prediction, tree search for action sequencing, and parallelized computation for efficiency. Key contributions include the Deep Interaction Prediction Network (DIPN) for accurate push motion forecasting (over 90% accuracy), its synergistic integration with Monte Carlo Tree Search (MCTS) for effective non-prehensile object retrieval (100% completion in specific challenging scenarios), and the Parallel MCTS with Batched Simulations (PMBS) framework, which achieves substantial planning speed-up while maintaining or improving solution quality. The research further explores combining diverse manipulation primitives, validated extensively through simulated and real-world experiments.
Toward Holistic Planning and Control Optimization for Dual-Arm Rearrangement
Apr 10, 2024
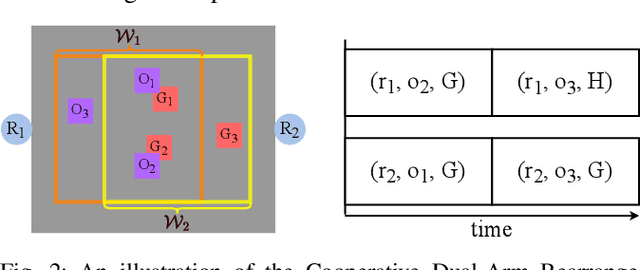
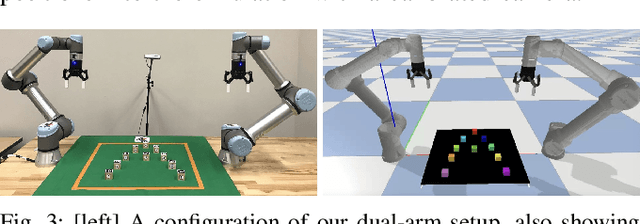
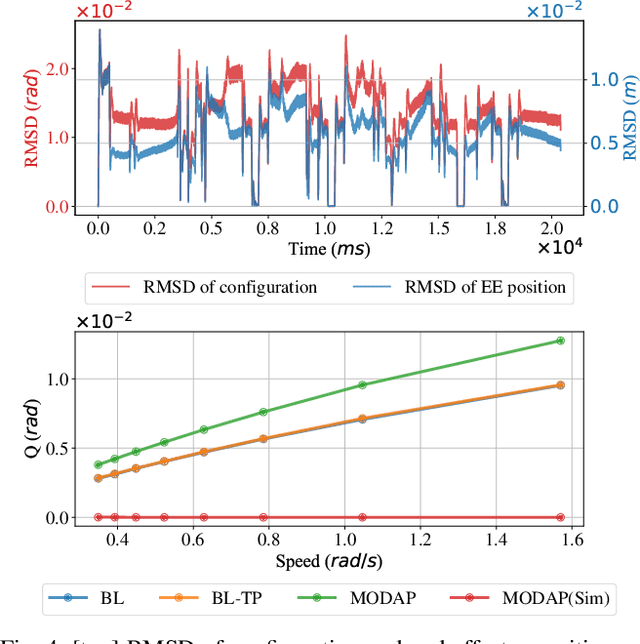
Long-horizon task and motion planning (TAMP) is notoriously difficult to solve, let alone optimally, due to the tight coupling between the interleaved (discrete) task and (continuous) motion planning phases, where each phase on its own is frequently an NP-hard or even PSPACE-hard computational challenge. In this study, we tackle the even more challenging goal of jointly optimizing task and motion plans for a real dual-arm system in which the two arms operate in close vicinity to solve highly constrained tabletop multi-object rearrangement problems. Toward that, we construct a tightly integrated planning and control optimization pipeline, Makespan-Optimized Dual-Arm Planner (MODAP) that combines novel sampling techniques for task planning with state-of-the-art trajectory optimization techniques. Compared to previous state-of-the-art, MODAP produces task and motion plans that better coordinate a dual-arm system, delivering significantly improved execution time improvements while simultaneously ensuring that the resulting time-parameterized trajectory conforms to specified acceleration and jerk limits.
Lightweight Inference for Forward-Forward Algorithm
Apr 09, 2024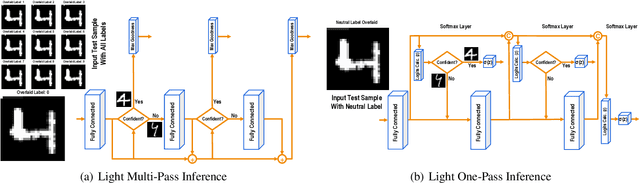
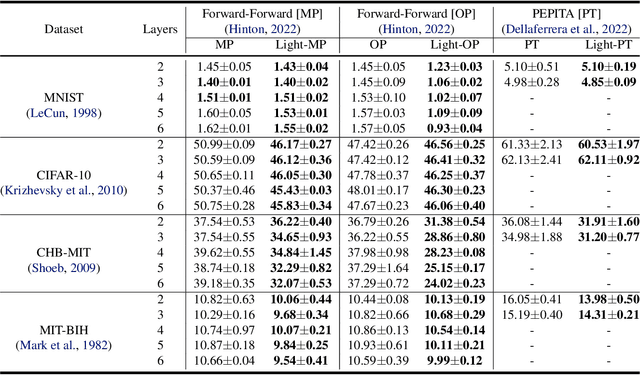

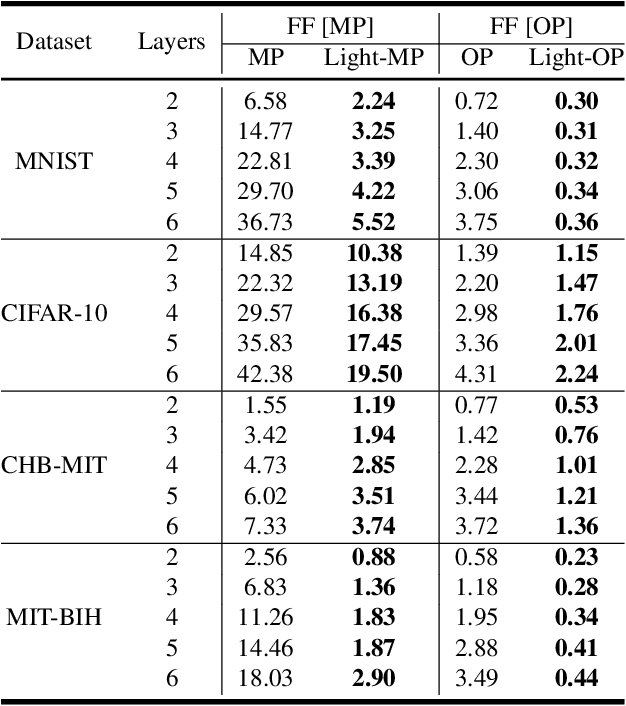
The human brain performs tasks with an outstanding energy-efficiency, i.e., with approximately 20 Watts. The state-of-the-art Artificial/Deep Neural Networks (ANN/DNN), on the other hand, have recently been shown to consume massive amounts of energy. The training of these ANNs/DNNs is done almost exclusively based on the back-propagation algorithm, which is known to be biologically implausible. This has led to a new generation of forward-only techniques, including the Forward-Forward algorithm. In this paper, we propose a lightweight inference scheme specifically designed for DNNs trained using the Forward-Forward algorithm. We have evaluated our proposed lightweight inference scheme in the case of the MNIST and CIFAR datasets, as well as two real-world applications, namely, epileptic seizure detection and cardiac arrhythmia classification using wearable technologies, where complexity overheads/energy consumption is a major constraint, and demonstrate its relevance.
EARL: Eye-on-Hand Reinforcement Learner for Dynamic Grasping with Active Pose Estimation
Oct 10, 2023
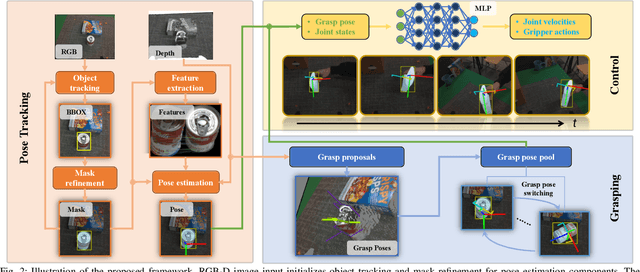
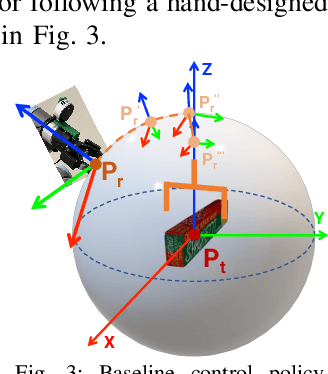
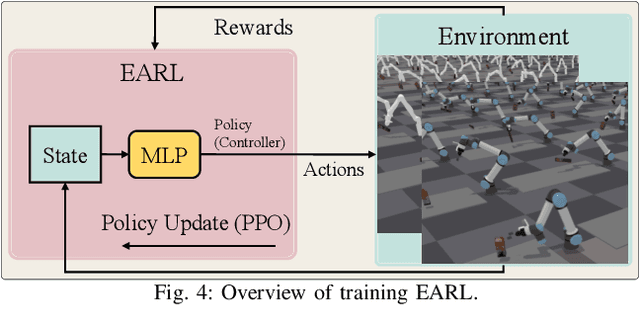
In this paper, we explore the dynamic grasping of moving objects through active pose tracking and reinforcement learning for hand-eye coordination systems. Most existing vision-based robotic grasping methods implicitly assume target objects are stationary or moving predictably. Performing grasping of unpredictably moving objects presents a unique set of challenges. For example, a pre-computed robust grasp can become unreachable or unstable as the target object moves, and motion planning must also be adaptive. In this work, we present a new approach, Eye-on-hAnd Reinforcement Learner (EARL), for enabling coupled Eye-on-Hand (EoH) robotic manipulation systems to perform real-time active pose tracking and dynamic grasping of novel objects without explicit motion prediction. EARL readily addresses many thorny issues in automated hand-eye coordination, including fast-tracking of 6D object pose from vision, learning control policy for a robotic arm to track a moving object while keeping the object in the camera's field of view, and performing dynamic grasping. We demonstrate the effectiveness of our approach in extensive experiments validated on multiple commercial robotic arms in both simulations and complex real-world tasks.
Toward Optimal Tabletop Rearrangement with Multiple Manipulation Primitives
Sep 29, 2023In practice, many types of manipulation actions (e.g., pick-n-place and push) are needed to accomplish real-world manipulation tasks. Yet, limited research exists that explores the synergistic integration of different manipulation actions for optimally solving long-horizon task-and-motion planning problems. In this study, we propose and investigate planning high-quality action sequences for solving long-horizon tabletop rearrangement tasks in which multiple manipulation primitives are required. Denoting the problem rearrangement with multiple manipulation primitives (REMP), we develop two algorithms, hierarchical best-first search (HBFS) and parallel Monte Carlo tree search for multi-primitive rearrangement (PMMR) toward optimally resolving the challenge. Extensive simulation and real robot experiments demonstrate that both methods effectively tackle REMP, with HBFS excelling in planning speed and PMMR producing human-like, high-quality solutions with a nearly 100% success rate.
LGMCTS: Language-Guided Monte-Carlo Tree Search for Executable Semantic Object Rearrangement
Sep 27, 2023

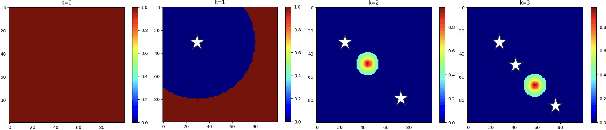
We introduce a novel approach to the executable semantic object rearrangement problem. In this challenge, a robot seeks to create an actionable plan that rearranges objects within a scene according to a pattern dictated by a natural language description. Unlike existing methods such as StructFormer and StructDiffusion, which tackle the issue in two steps by first generating poses and then leveraging a task planner for action plan formulation, our method concurrently addresses pose generation and action planning. We achieve this integration using a Language-Guided Monte-Carlo Tree Search (LGMCTS). Quantitative evaluations are provided on two simulation datasets, and complemented by qualitative tests with a real robot.
Learning Generalizable Pivoting Skills
May 04, 2023The skill of pivoting an object with a robotic system is challenging for the external forces that act on the system, mainly given by contact interaction. The complexity increases when the same skills are required to generalize across different objects. This paper proposes a framework for learning robust and generalizable pivoting skills, which consists of three steps. First, we learn a pivoting policy on an ``unitary'' object using Reinforcement Learning (RL). Then, we obtain the object's feature space by supervised learning to encode the kinematic properties of arbitrary objects. Finally, to adapt the unitary policy to multiple objects, we learn data-driven projections based on the object features to adjust the state and action space of the new pivoting task. The proposed approach is entirely trained in simulation. It requires only one depth image of the object and can zero-shot transfer to real-world objects. We demonstrate robustness to sim-to-real transfer and generalization to multiple objects.
Minimizing Running Buffers for Tabletop Object Rearrangement: Complexity, Fast Algorithms, and Applications
Apr 04, 2023For rearranging objects on tabletops with overhand grasps, temporarily relocating objects to some buffer space may be necessary. This raises the natural question of how many simultaneous storage spaces, or "running buffers", are required so that certain classes of tabletop rearrangement problems are feasible. In this work, we examine the problem for both labeled and unlabeled settings. On the structural side, we observe that finding the minimum number of running buffers (MRB) can be carried out on a dependency graph abstracted from a problem instance, and show that computing MRB is NP-hard. We then prove that under both labeled and unlabeled settings, even for uniform cylindrical objects, the number of required running buffers may grow unbounded as the number of objects to be rearranged increases. We further show that the bound for the unlabeled case is tight. On the algorithmic side, we develop effective exact algorithms for finding MRB for both labeled and unlabeled tabletop rearrangement problems, scalable to over a hundred objects under very high object density. More importantly, our algorithms also compute a sequence witnessing the computed MRB that can be used for solving object rearrangement tasks. Employing these algorithms, empirical evaluations reveal that random labeled and unlabeled instances, which more closely mimics real-world setups, generally have fairly small MRBs. Using real robot experiments, we demonstrate that the running buffer abstraction leads to state-of-the-art solutions for in-place rearrangement of many objects in tight, bounded workspace.
Parallel Monte Carlo Tree Search with Batched Rigid-body Simulations for Speeding up Long-Horizon Episodic Robot Planning
Jul 14, 2022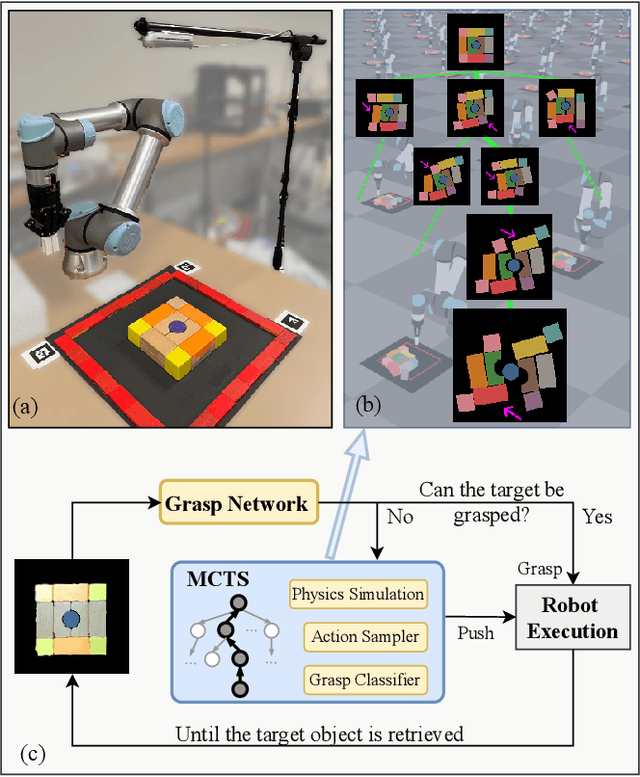
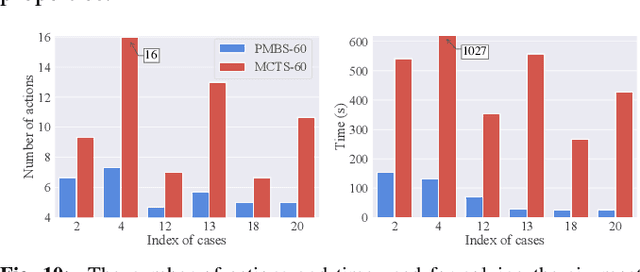
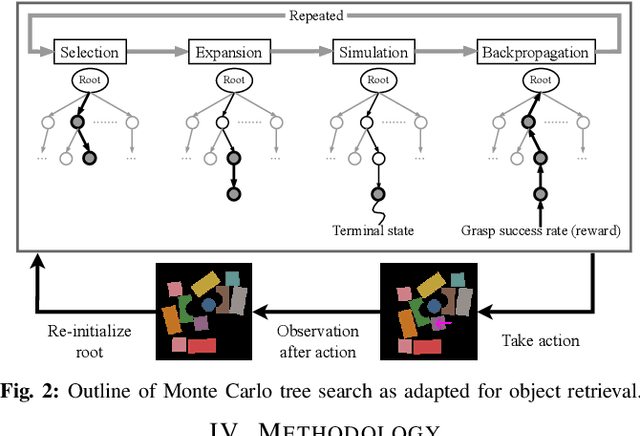
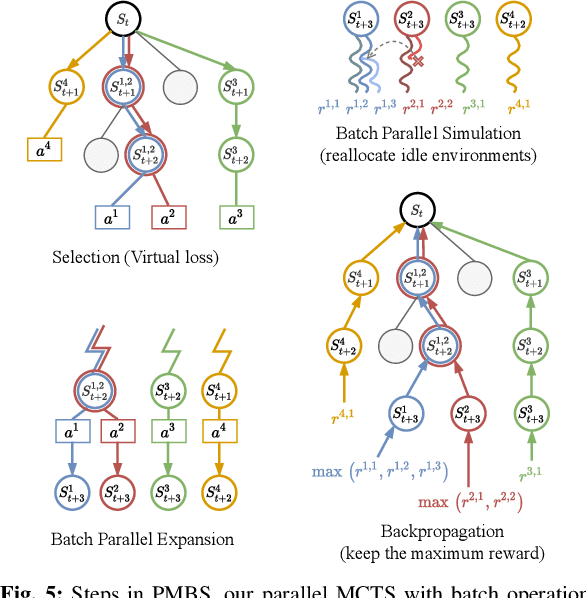
We propose a novel Parallel Monte Carlo tree search with Batched Simulations (PMBS) algorithm for accelerating long-horizon, episodic robotic planning tasks. Monte Carlo tree search (MCTS) is an effective heuristic search algorithm for solving episodic decision-making problems whose underlying search spaces are expansive. Leveraging a GPU-based large-scale simulator, PMBS introduces massive parallelism into MCTS for solving planning tasks through the batched execution of a large number of concurrent simulations, which allows for more efficient and accurate evaluations of the expected cost-to-go over large action spaces. When applied to the challenging manipulation tasks of object retrieval from clutter, PMBS achieves a speedup of over $30\times$ with an improved solution quality, in comparison to a serial MCTS implementation. We show that PMBS can be directly applied to real robot hardware with negligible sim-to-real differences. Supplementary material, including video, can be found at https://github.com/arc-l/pmbs.