 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFAN, a transformer-based deep learning model for human-artificial intelligence collaborative assessment of incidental pulmonary nodules in CT scans: a multi-reader, multi-case trial
Mar 26, 2026The widespread adoption of CT has notably increased the number of detected lung nodules. However, current deep learning methods for classifying benign and malignant nodules often fail to comprehensively integrate global and local features, and most of them have not been validated through clinical trials. To address this, we developed DeepFAN, a transformer-based model trained on over 10K pathology-confirmed nodules and further conducted a multi-reader, multi-case clinical trial to evaluate its efficacy in assisting junior radiologists. DeepFAN achieved diagnostic area under the curve (AUC) of 0.939 (95% CI 0.930-0.948) on an internal test set and 0.954 (95% CI 0.934-0.973) on the clinical trial dataset involving 400 cases across three independent medical institutions. Explainability analysis indicated higher contributions from global than local features. Twelve readers' average performance significantly improved by 10.9% (95% CI 8.3%-13.5%) in AUC, 10.0% (95% CI 8.9%-11.1%) in accuracy, 7.6% (95% CI 6.1%-9.2%) in sensitivity, and 12.6% (95% CI 10.9%-14.3%) in specificity (P<0.001 for all). Nodule-level inter-reader diagnostic consistency improved from fair to moderate (overall k: 0.313 vs. 0.421; P=0.019). In conclusion, DeepFAN effectively assisted junior radiologists and may help homogenize diagnostic quality and reduce unnecessary follow-up of indeterminate pulmonary nodules. Chinese Clinical Trial Registry: ChiCTR2400084624.
Infinite-Instruct: Synthesizing Scaling Code instruction Data with Bidirectional Synthesis and Static Verification
May 29, 2025Traditional code instruction data synthesis methods suffer from limited diversity and poor logic. We introduce Infinite-Instruct, an automated framework for synthesizing high-quality question-answer pairs, designed to enhance the code generation capabilities of large language models (LLMs). The framework focuses on improving the internal logic of synthesized problems and the quality of synthesized code. First, "Reverse Construction" transforms code snippets into diverse programming problems. Then, through "Backfeeding Construction," keywords in programming problems are structured into a knowledge graph to reconstruct them into programming problems with stronger internal logic. Finally, a cross-lingual static code analysis pipeline filters invalid samples to ensure data quality. Experiments show that on mainstream code generation benchmarks, our fine-tuned models achieve an average performance improvement of 21.70% on 7B-parameter models and 36.95% on 32B-parameter models. Using less than one-tenth of the instruction fine-tuning data, we achieved performance comparable to the Qwen-2.5-Coder-Instruct. Infinite-Instruct provides a scalable solution for LLM training in programming. We open-source the datasets used in the experiments, including both unfiltered versions and filtered versions via static analysis. The data are available at https://github.com/xingwenjing417/Infinite-Instruct-dataset
MuST: Multi-Head Skill Transformer for Long-Horizon Dexterous Manipulation with Skill Progress
Feb 04, 2025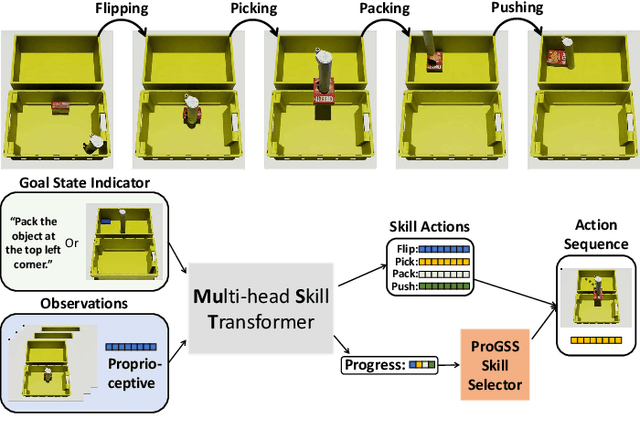
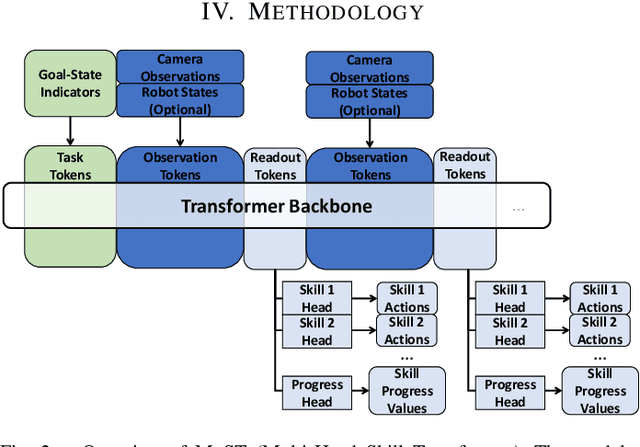
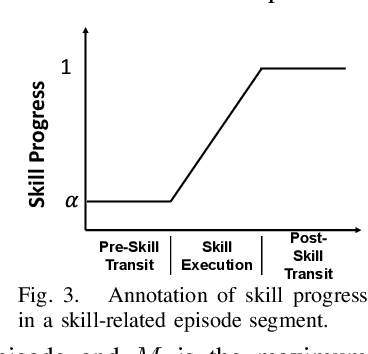
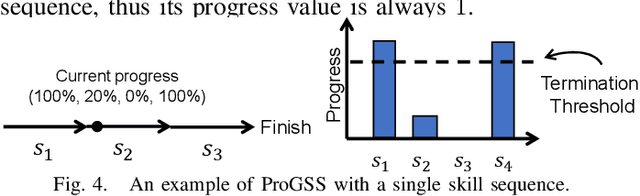
Robot picking and packing tasks require dexterous manipulation skills, such as rearranging objects to establish a good grasping pose, or placing and pushing items to achieve tight packing. These tasks are challenging for robots due to the complexity and variability of the required actions. To tackle the difficulty of learning and executing long-horizon tasks, we propose a novel framework called the Multi-Head Skill Transformer (MuST). This model is designed to learn and sequentially chain together multiple motion primitives (skills), enabling robots to perform complex sequences of actions effectively. MuST introduces a "progress value" for each skill, guiding the robot on which skill to execute next and ensuring smooth transitions between skills. Additionally, our model is capable of expanding its skill set and managing various sequences of sub-tasks efficiently. Extensive experiments in both simulated and real-world environments demonstrate that MuST significantly enhances the robot's ability to perform long-horizon dexterous manipulation tasks.
Imitation Game for Adversarial Disillusion with Multimodal Generative Chain-of-Thought Role-Play
Jan 31, 2025



As the cornerstone of artificial intelligence, machine perception confronts a fundamental threat posed by adversarial illusions. These adversarial attacks manifest in two primary forms: deductive illusion, where specific stimuli are crafted based on the victim model's general decision logic, and inductive illusion, where the victim model's general decision logic is shaped by specific stimuli. The former exploits the model's decision boundaries to create a stimulus that, when applied, interferes with its decision-making process. The latter reinforces a conditioned reflex in the model, embedding a backdoor during its learning phase that, when triggered by a stimulus, causes aberrant behaviours. The multifaceted nature of adversarial illusions calls for a unified defence framework, addressing vulnerabilities across various forms of attack. In this study, we propose a disillusion paradigm based on the concept of an imitation game. At the heart of the imitation game lies a multimodal generative agent, steered by chain-of-thought reasoning, which observes, internalises and reconstructs the semantic essence of a sample, liberated from the classic pursuit of reversing the sample to its original state. As a proof of concept, we conduct experimental simulations using a multimodal generative dialogue agent and evaluates the methodology under a variety of attack scenarios.
Tabletop Object Rearrangement: Structure, Complexity, and Efficient Combinatorial Search-Based Solutions
Dec 19, 2024This thesis provides an in-depth structural analysis and efficient algorithmic solutions for tabletop object rearrangement with overhand grasps (TORO), a foundational task in advancing intelligent robotic manipulation. Rearranging multiple objects in a confined workspace presents two primary challenges: sequencing actions to minimize pick-and-place operations - an NP-hard problem in TORO - and determining temporary object placements ("buffer poses") within a cluttered environment, which is essential yet highly complex. For TORO with available external free space, this work investigates the minimum buffer space, or "running buffer size," required for temporary relocations, presenting both theoretical insights and exact algorithms. For TORO without external free space, the concept of lazy buffer verification is introduced, with its efficiency evaluated across various manipulator configurations, including single-arm, dual-arm, and mobile manipulators.
A First Look at License Compliance Capability of LLMs in Code Generation
Aug 05, 2024



Recent advances in Large Language Models (LLMs) have revolutionized code generation, leading to widespread adoption of AI coding tools by developers. However, LLMs can generate license-protected code without providing the necessary license information, leading to potential intellectual property violations during software production. This paper addresses the critical, yet underexplored, issue of license compliance in LLM-generated code by establishing a benchmark to evaluate the ability of LLMs to provide accurate license information for their generated code. To establish this benchmark, we conduct an empirical study to identify a reasonable standard for "striking similarity" that excludes the possibility of independent creation, indicating a copy relationship between the LLM output and certain open-source code. Based on this standard, we propose an evaluation benchmark LiCoEval, to evaluate the license compliance capabilities of LLMs. Using LiCoEval, we evaluate 14 popular LLMs, finding that even top-performing LLMs produce a non-negligible proportion (0.88% to 2.01%) of code strikingly similar to existing open-source implementations. Notably, most LLMs fail to provide accurate license information, particularly for code under copyleft licenses. These findings underscore the urgent need to enhance LLM compliance capabilities in code generation tasks. Our study provides a foundation for future research and development to improve license compliance in AI-assisted software development, contributing to both the protection of open-source software copyrights and the mitigation of legal risks for LLM users.
Unsupervised Multimodal Clustering for Semantics Discovery in Multimodal Utterances
May 21, 2024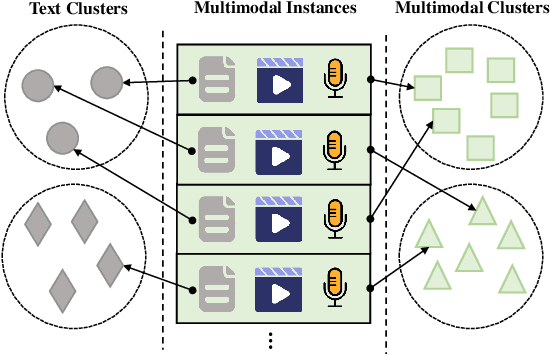
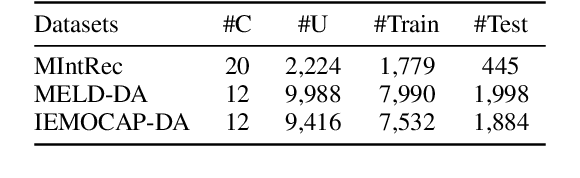
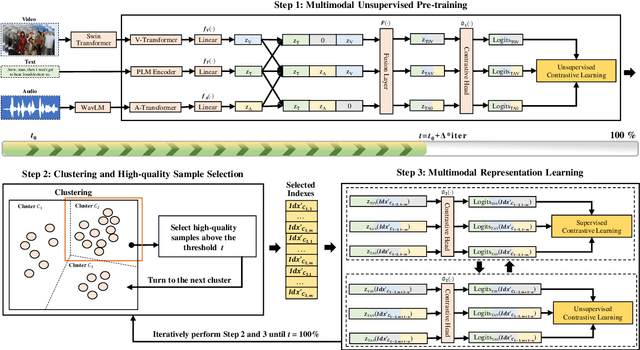
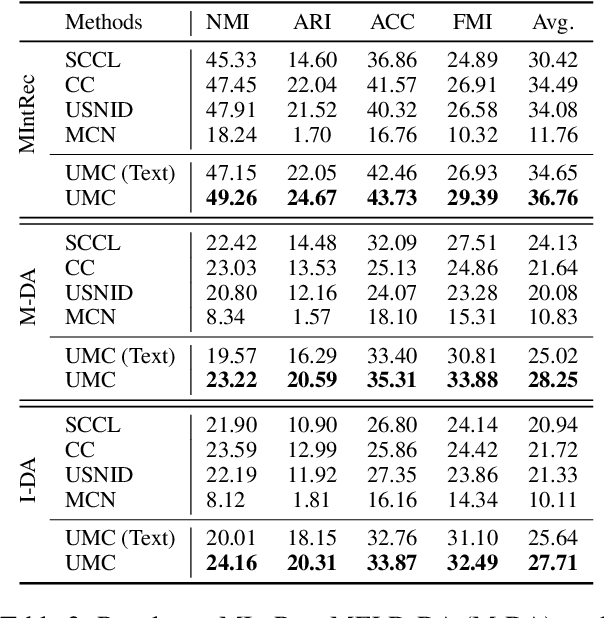
Discovering the semantics of multimodal utterances is essential for understanding human language and enhancing human-machine interactions. Existing methods manifest limitations in leveraging nonverbal information for discerning complex semantics in unsupervised scenarios. This paper introduces a novel unsupervised multimodal clustering method (UMC), making a pioneering contribution to this field. UMC introduces a unique approach to constructing augmentation views for multimodal data, which are then used to perform pre-training to establish well-initialized representations for subsequent clustering. An innovative strategy is proposed to dynamically select high-quality samples as guidance for representation learning, gauged by the density of each sample's nearest neighbors. Besides, it is equipped to automatically determine the optimal value for the top-$K$ parameter in each cluster to refine sample selection. Finally, both high- and low-quality samples are used to learn representations conducive to effective clustering. We build baselines on benchmark multimodal intent and dialogue act datasets. UMC shows remarkable improvements of 2-6\% scores in clustering metrics over state-of-the-art methods, marking the first successful endeavor in this domain. The complete code and data are available at https://github.com/thuiar/UMC.
Toward Holistic Planning and Control Optimization for Dual-Arm Rearrangement
Apr 10, 2024
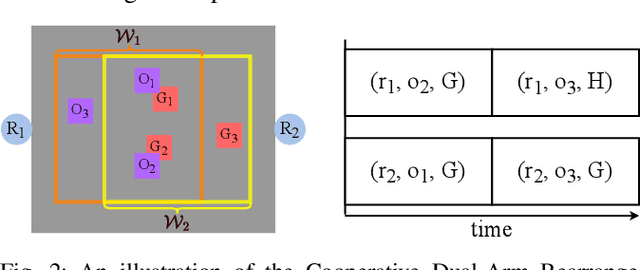
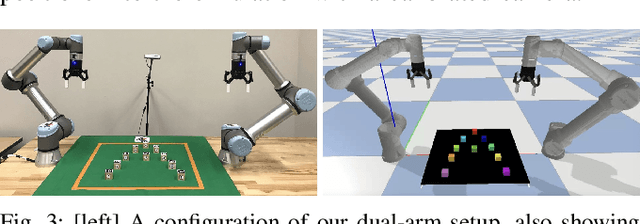
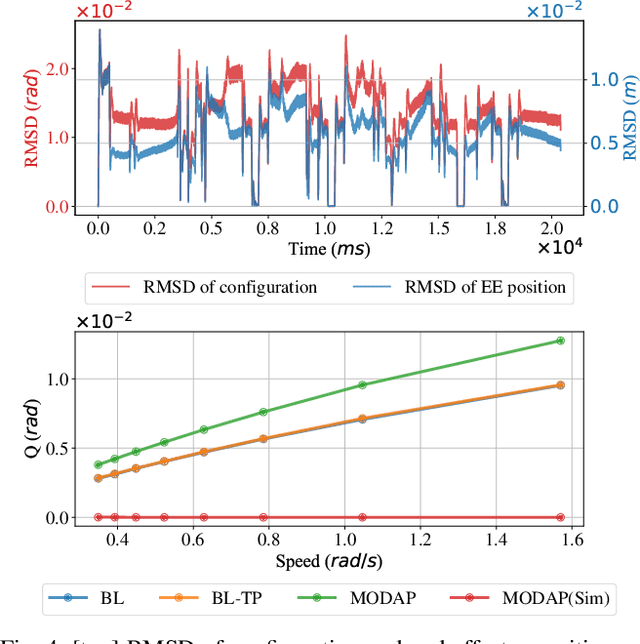
Long-horizon task and motion planning (TAMP) is notoriously difficult to solve, let alone optimally, due to the tight coupling between the interleaved (discrete) task and (continuous) motion planning phases, where each phase on its own is frequently an NP-hard or even PSPACE-hard computational challenge. In this study, we tackle the even more challenging goal of jointly optimizing task and motion plans for a real dual-arm system in which the two arms operate in close vicinity to solve highly constrained tabletop multi-object rearrangement problems. Toward that, we construct a tightly integrated planning and control optimization pipeline, Makespan-Optimized Dual-Arm Planner (MODAP) that combines novel sampling techniques for task planning with state-of-the-art trajectory optimization techniques. Compared to previous state-of-the-art, MODAP produces task and motion plans that better coordinate a dual-arm system, delivering significantly improved execution time improvements while simultaneously ensuring that the resulting time-parameterized trajectory conforms to specified acceleration and jerk limits.
MIntRec2.0: A Large-scale Benchmark Dataset for Multimodal Intent Recognition and Out-of-scope Detection in Conversations
Mar 20, 2024



Multimodal intent recognition poses significant challenges, requiring the incorporation of non-verbal modalities from real-world contexts to enhance the comprehension of human intentions. Existing benchmark datasets are limited in scale and suffer from difficulties in handling out-of-scope samples that arise in multi-turn conversational interactions. We introduce MIntRec2.0, a large-scale benchmark dataset for multimodal intent recognition in multi-party conversations. It contains 1,245 dialogues with 15,040 samples, each annotated within a new intent taxonomy of 30 fine-grained classes. Besides 9,304 in-scope samples, it also includes 5,736 out-of-scope samples appearing in multi-turn contexts, which naturally occur in real-world scenarios. Furthermore, we provide comprehensive information on the speakers in each utterance, enriching its utility for multi-party conversational research. We establish a general framework supporting the organization of single-turn and multi-turn dialogue data, modality feature extraction, multimodal fusion, as well as in-scope classification and out-of-scope detection. Evaluation benchmarks are built using classic multimodal fusion methods, ChatGPT, and human evaluators. While existing methods incorporating nonverbal information yield improvements, effectively leveraging context information and detecting out-of-scope samples remains a substantial challenge. Notably, large language models exhibit a significant performance gap compared to humans, highlighting the limitations of machine learning methods in the cognitive intent understanding task. We believe that MIntRec2.0 will serve as a valuable resource, providing a pioneering foundation for research in human-machine conversational interactions, and significantly facilitating related applications. The full dataset and codes are available at https://github.com/thuiar/MIntRec2.0.
Token-Level Contrastive Learning with Modality-Aware Prompting for Multimodal Intent Recognition
Dec 22, 2023


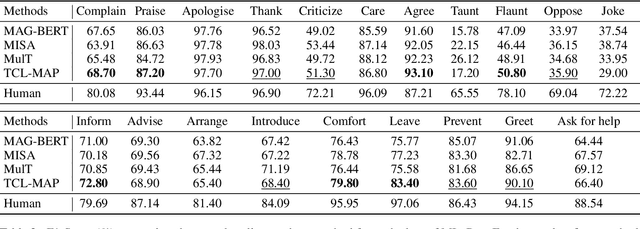
Multimodal intent recognition aims to leverage diverse modalities such as expressions, body movements and tone of speech to comprehend user's intent, constituting a critical task for understanding human language and behavior in real-world multimodal scenarios. Nevertheless, the majority of existing methods ignore potential correlations among different modalities and own limitations in effectively learning semantic features from nonverbal modalities. In this paper, we introduce a token-level contrastive learning method with modality-aware prompting (TCL-MAP) to address the above challenges. To establish an optimal multimodal semantic environment for text modality, we develop a modality-aware prompting module (MAP), which effectively aligns and fuses features from text, video and audio modalities with similarity-based modality alignment and cross-modality attention mechanism. Based on the modality-aware prompt and ground truth labels, the proposed token-level contrastive learning framework (TCL) constructs augmented samples and employs NT-Xent loss on the label token. Specifically, TCL capitalizes on the optimal textual semantic insights derived from intent labels to guide the learning processes of other modalities in return. Extensive experiments show that our method achieves remarkable improvements compared to state-of-the-art methods. Additionally, ablation analyses demonstrate the superiority of the modality-aware prompt over the handcrafted prompt, which holds substantial significance for multimodal prompt learning. The codes are released at https://github.com/thuiar/TCL-MAP.