 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Effects: Shared Heuristic Reliance in Trust Assessment by Humans and LLM-as-a-Judge
Apr 07, 2026Large language models (LLMs) are increasingly used as automated evaluators (LLM-as-a-Judge). This work challenges its reliability by showing that trust judgments by LLMs are biased by disclosed source labels. Using a counterfactual design, we find that both humans and LLM judges assign higher trust to information labeled as human-authored than to the same content labeled as AI-generated. Eye-tracking data reveal that humans rely heavily on source labels as heuristic cues for judgments. We analyze LLM internal states during judgment. Across label conditions, models allocate denser attention to the label region than the content region, and this label dominance is stronger under Human labels than AI labels, consistent with the human gaze patterns. Besides, decision uncertainty measured by logits is higher under AI labels than Human labels. These results indicate that the source label is a salient heuristic cue for both humans and LLMs. It raises validity concerns for label-sensitive LLM-as-a-Judge evaluation, and we cautiously raise that aligning models with human preferences may propagate human heuristic reliance into models, motivating debiased evaluation and alignment.
Beyond Standard Benchmarks: A Systematic Audit of Vision-Language Model's Robustness to Natural Semantic Variation Across Diverse Tasks
Apr 06, 2026Recent advances in vision-language models (VLMs) trained on web-scale image-text pairs have enabled impressive zero-shot transfer across a diverse range of visual tasks. However, comprehensive and independent evaluation beyond standard benchmarks is essential to understand their robustness, limitations, and real-world applicability. This paper presents a systematic evaluation framework for VLMs under natural adversarial scenarios for diverse downstream tasks, which has been overlooked in previous evaluation works. We evaluate a wide range of VLMs (CLIP, robust CLIP, BLIP2, and SigLIP2) on curated adversarial datasets (typographic attacks, ImageNet-A, and natural language-induced adversarial examples). We measure the natural adversarial performance of selected VLMs for zero-shot image classification, semantic segmentation, and visual question answering. Our analysis reveals that robust CLIP models can amplify natural adversarial vulnerabilities, and CLIP models significantly reduce performance for natural language-induced adversarial examples. Additionally, we provide interpretable analyses to identify failure modes. We hope our findings inspire future research in robust and fair multimodal pattern recognition.
EvoGuard: An Extensible Agentic RL-based Framework for Practical and Evolving AI-Generated Image Detection
Mar 18, 2026The rapid proliferation of AI-Generated Images (AIGIs) has introduced severe risks of misinformation, making AIGI detection a critical yet challenging task. While traditional detection paradigms mainly rely on low-level features, recent research increasingly focuses on leveraging the general understanding ability of Multimodal Large Language Models (MLLMs) to achieve better generalization, but still suffer from limited extensibility and expensive training data annotations. To better address complex and dynamic real-world environments, we propose EvoGuard, a novel agentic framework for AIGI detection. It encapsulates various state-of-the-art (SOTA) off-the-shelf MLLM and non-MLLM detectors as callable tools, and coordinates them through a capability-aware dynamic orchestration mechanism. Empowered by the agent's capacities for autonomous planning and reflection, it intelligently selects suitable tools for given samples, reflects intermediate results, and decides the next action, reaching a final conclusion through multi-turn invocation and reasoning. This design effectively exploits the complementary strengths among heterogeneous detectors, transcending the limits of any single model. Furthermore, optimized by a GRPO-based Agentic Reinforcement Learning algorithm using only low-cost binary labels, it eliminates the reliance on fine-grained annotations. Extensive experiments demonstrate that EvoGuard achieves SOTA accuracy while mitigating the bias between positive and negative samples. More importantly, it allows the plug-and-play integration of new detectors to boost overall performance in a train-free manner, offering a highly practical, long-term solution to ever-evolving AIGI threats. Source code will be publicly available upon acceptance.
SciDef: Automating Definition Extraction from Academic Literature with Large Language Models
Feb 05, 2026Definitions are the foundation for any scientific work, but with a significant increase in publication numbers, gathering definitions relevant to any keyword has become challenging. We therefore introduce SciDef, an LLM-based pipeline for automated definition extraction. We test SciDef on DefExtra & DefSim, novel datasets of human-extracted definitions and definition-pairs' similarity, respectively. Evaluating 16 language models across prompting strategies, we demonstrate that multi-step and DSPy-optimized prompting improve extraction performance. To evaluate extraction, we test various metrics and show that an NLI-based method yields the most reliable results. We show that LLMs are largely able to extract definitions from scientific literature (86.4% of definitions from our test-set); yet future work should focus not just on finding definitions, but on identifying relevant ones, as models tend to over-generate them. Code & datasets are available at https://github.com/Media-Bias-Group/SciDef.
Gradient Structure Estimation under Label-Only Oracles via Spectral Sensitivity
Jan 17, 2026Hard-label black-box settings, where only top-1 predicted labels are observable, pose a fundamentally constrained yet practically important feedback model for understanding model behavior. A central challenge in this regime is whether meaningful gradient information can be recovered from such discrete responses. In this work, we develop a unified theoretical perspective showing that a wide range of existing sign-flipping hard-label attacks can be interpreted as implicitly approximating the sign of the true loss gradient. This observation reframes hard-label attacks from heuristic search procedures into instances of gradient sign recovery under extremely limited feedback. Motivated by this first-principles understanding, we propose a new attack framework that combines a zero-query frequency-domain initialization with a Pattern-Driven Optimization (PDO) strategy. We establish theoretical guarantees demonstrating that, under mild assumptions, our initialization achieves higher expected cosine similarity to the true gradient sign compared to random baselines, while the proposed PDO procedure attains substantially lower query complexity than existing structured search approaches. We empirically validate our framework through extensive experiments on CIFAR-10, ImageNet, and ObjectNet, covering standard and adversarially trained models, commercial APIs, and CLIP-based models. The results show that our method consistently surpasses SOTA hard-label attacks in both attack success rate and query efficiency, particularly in low-query regimes. Beyond image classification, our approach generalizes effectively to corrupted data, biomedical datasets, and dense prediction tasks. Notably, it also successfully circumvents Blacklight, a SOTA stateful defense, resulting in a $0\%$ detection rate. Our code will be released publicly soon at https://github.com/csjunjun/DPAttack.git.
SGM: Safety Glasses for Multimodal Large Language Models via Neuron-Level Detoxification
Dec 17, 2025Disclaimer: Samples in this paper may be harmful and cause discomfort. Multimodal large language models (MLLMs) enable multimodal generation but inherit toxic, biased, and NSFW signals from weakly curated pretraining corpora, causing safety risks, especially under adversarial triggers that late, opaque training-free detoxification methods struggle to handle. We propose SGM, a white-box neuron-level multimodal intervention that acts like safety glasses for toxic neurons: it selectively recalibrates a small set of toxic expert neurons via expertise-weighted soft suppression, neutralizing harmful cross-modal activations without any parameter updates. We establish MM-TOXIC-QA, a multimodal toxicity evaluation framework, and compare SGM with existing detoxification techniques. Experiments on open-source MLLMs show that SGM mitigates toxicity in standard and adversarial conditions, cutting harmful rates from 48.2\% to 2.5\% while preserving fluency and multimodal reasoning. SGM is extensible, and its combined defenses, denoted as SGM*, integrate with existing detoxification methods for stronger safety performance, providing an interpretable, low-cost solution for toxicity-controlled multimodal generation.
DRAGON: A Large-Scale Dataset of Realistic Images Generated by Diffusion Models
May 16, 2025The remarkable ease of use of diffusion models for image generation has led to a proliferation of synthetic content online. While these models are often employed for legitimate purposes, they are also used to generate fake images that support misinformation and hate speech. Consequently, it is crucial to develop robust tools capable of detecting whether an image has been generated by such models. Many current detection methods, however, require large volumes of sample images for training. Unfortunately, due to the rapid evolution of the field, existing datasets often cover only a limited range of models and quickly become outdated. In this work, we introduce DRAGON, a comprehensive dataset comprising images from 25 diffusion models, spanning both recent advancements and older, well-established architectures. The dataset contains a broad variety of images representing diverse subjects. To enhance image realism, we propose a simple yet effective pipeline that leverages a large language model to expand input prompts, thereby generating more diverse and higher-quality outputs, as evidenced by improvements in standard quality metrics. The dataset is provided in multiple sizes (ranging from extra-small to extra-large) to accomodate different research scenarios. DRAGON is designed to support the forensic community in developing and evaluating detection and attribution techniques for synthetic content. Additionally, the dataset is accompanied by a dedicated test set, intended to serve as a benchmark for assessing the performance of newly developed methods.
Diffusion-Driven Universal Model Inversion Attack for Face Recognition
Apr 25, 2025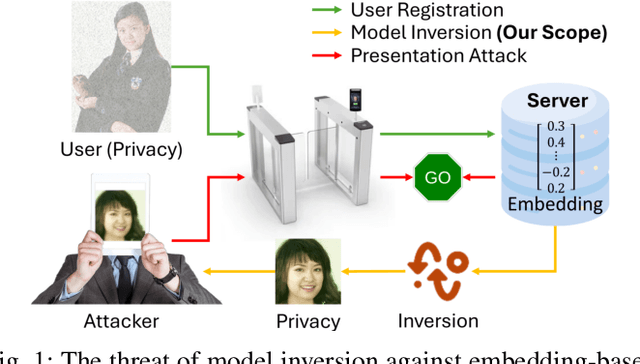
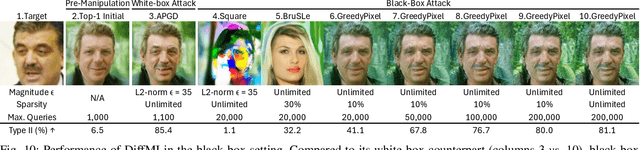
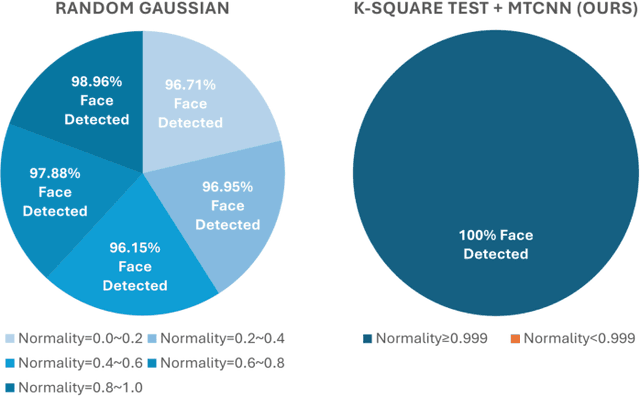
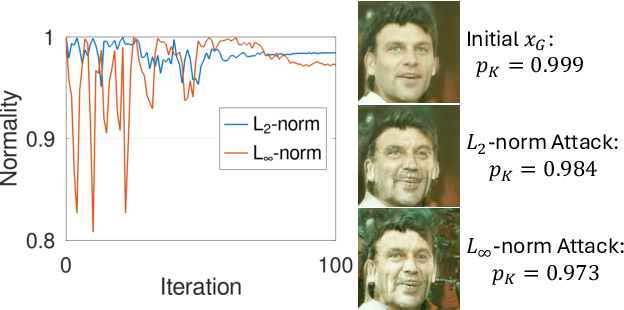
Facial recognition technology poses significant privacy risks, as it relies on biometric data that is inherently sensitive and immutable if compromised. To mitigate these concerns, face recognition systems convert raw images into embeddings, traditionally considered privacy-preserving. However, model inversion attacks pose a significant privacy threat by reconstructing these private facial images, making them a crucial tool for evaluating the privacy risks of face recognition systems. Existing methods usually require training individual generators for each target model, a computationally expensive process. In this paper, we propose DiffUMI, a training-free diffusion-driven universal model inversion attack for face recognition systems. DiffUMI is the first approach to apply a diffusion model for unconditional image generation in model inversion. Unlike other methods, DiffUMI is universal, eliminating the need for training target-specific generators. It operates within a fixed framework and pretrained diffusion model while seamlessly adapting to diverse target identities and models. DiffUMI breaches privacy-preserving face recognition systems with state-of-the-art success, demonstrating that an unconditional diffusion model, coupled with optimized adversarial search, enables efficient and high-fidelity facial reconstruction. Additionally, we introduce a novel application of out-of-domain detection (OODD), marking the first use of model inversion to distinguish non-face inputs from face inputs based solely on embeddings.
The Chronicles of Foundation AI for Forensics of Multi-Agent Provenance
Apr 17, 2025Provenance is the chronology of things, resonating with the fundamental pursuit to uncover origins, trace connections, and situate entities within the flow of space and time. As artificial intelligence advances towards autonomous agents capable of interactive collaboration on complex tasks, the provenance of generated content becomes entangled in the interplay of collective creation, where contributions are continuously revised, extended or overwritten. In a multi-agent generative chain, content undergoes successive transformations, often leaving little, if any, trace of prior contributions. In this study, we investigates the problem of tracking multi-agent provenance across the temporal dimension of generation. We propose a chronological system for post hoc attribution of generative history from content alone, without reliance on internal memory states or external meta-information. At its core lies the notion of symbolic chronicles, representing signed and time-stamped records, in a form analogous to the chain of custody in forensic science. The system operates through a feedback loop, whereby each generative timestep updates the chronicle of prior interactions and synchronises it with the synthetic content in the very act of generation. This research seeks to develop an accountable form of collaborative artificial intelligence within evolving cyber ecosystems.
AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era
Apr 15, 2025



Recent advances in image generation, particularly diffusion models, have significantly lowered the barrier for creating sophisticated forgeries, making image manipulation detection and localization (IMDL) increasingly challenging. While prior work in IMDL has focused largely on natural images, the anime domain remains underexplored-despite its growing vulnerability to AI-generated forgeries. Misrepresentations of AI-generated images as hand-drawn artwork, copyright violations, and inappropriate content modifications pose serious threats to the anime community and industry. To address this gap, we propose AnimeDL-2M, the first large-scale benchmark for anime IMDL with comprehensive annotations. It comprises over two million images including real, partially manipulated, and fully AI-generated samples. Experiments indicate that models trained on existing IMDL datasets of natural images perform poorly when applied to anime images, highlighting a clear domain gap between anime and natural images. To better handle IMDL tasks in anime domain, we further propose AniXplore, a novel model tailored to the visual characteristics of anime imagery. Extensive evaluations demonstrate that AniXplore achieves superior performance compared to existing methods. Dataset and code can be found in https://flytweety.github.io/AnimeDL2M/.