 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Detection: Multi-Scale Hidden-Code for Natural Image Deepfake Recovery and Factual Retrieval
Feb 26, 2026Recent advances in image authenticity have primarily focused on deepfake detection and localization, leaving recovery of tampered contents for factual retrieval relatively underexplored. We propose a unified hidden-code recovery framework that enables both retrieval and restoration from post-hoc and in-generation watermarking paradigms. Our method encodes semantic and perceptual information into a compact hidden-code representation, refined through multi-scale vector quantization, and enhances contextual reasoning via conditional Transformer modules. To enable systematic evaluation for natural images, we construct ImageNet-S, a benchmark that provides paired image-label factual retrieval tasks. Extensive experiments on ImageNet-S demonstrate that our method exhibits promising retrieval and reconstruction performance while remaining fully compatible with diverse watermarking pipelines. This framework establishes a foundation for general-purpose image recovery beyond detection and localization.
FedSDA: Federated Stain Distribution Alignment for Non-IID Histopathological Image Classification
Nov 15, 2025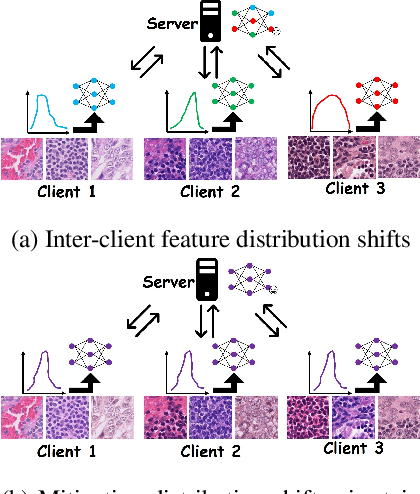

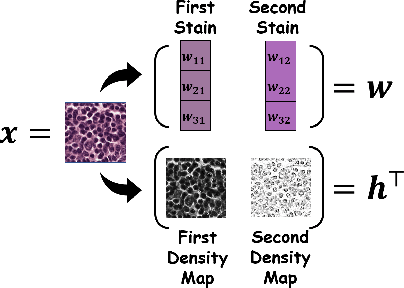
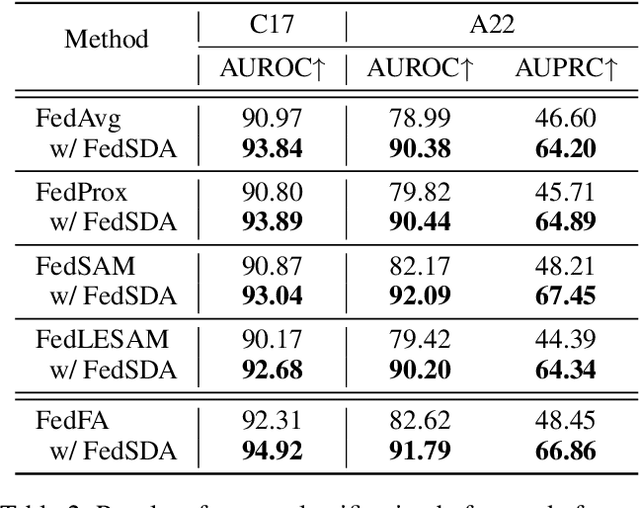
Federated learning (FL) has shown success in collaboratively training a model among decentralized data resources without directly sharing privacy-sensitive training data. Despite recent advances, non-IID (non-independent and identically distributed) data poses an inevitable challenge that hinders the use of FL. In this work, we address the issue of non-IID histopathological images with feature distribution shifts from an intuitive perspective that has only received limited attention. Specifically, we address this issue from the perspective of data distribution by solely adjusting the data distributions of all clients. Building on the success of diffusion models in fitting data distributions and leveraging stain separation to extract the pivotal features that are closely related to the non-IID properties of histopathological images, we propose a Federated Stain Distribution Alignment (FedSDA) method. FedSDA aligns the stain distribution of each client with a target distribution in an FL framework to mitigate distribution shifts among clients. Furthermore, considering that training diffusion models on raw data in FL has been shown to be susceptible to privacy leakage risks, we circumvent this problem while still effectively achieving alignment. Extensive experimental results show that FedSDA is not only effective in improving baselines that focus on mitigating disparities across clients' model updates but also outperforms baselines that address the non-IID data issues from the perspective of data distribution. We show that FedSDA provides valuable and practical insights for the computational pathology community.
Diffusion-Driven Universal Model Inversion Attack for Face Recognition
Apr 25, 2025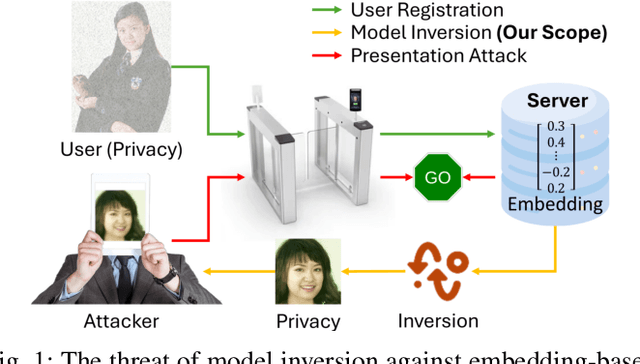
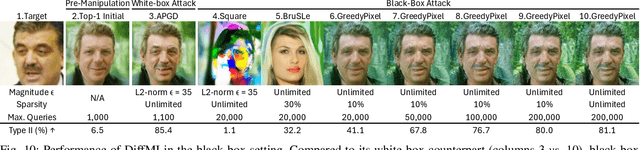
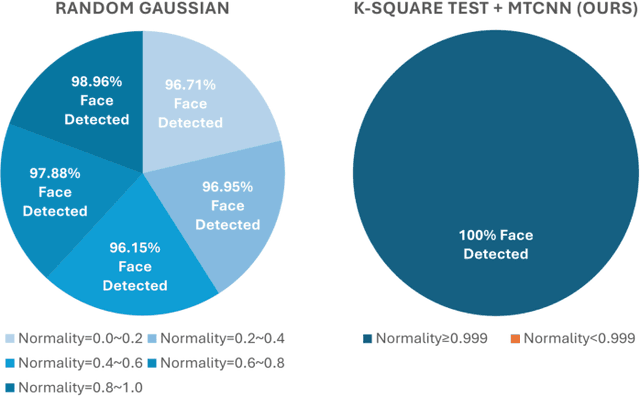
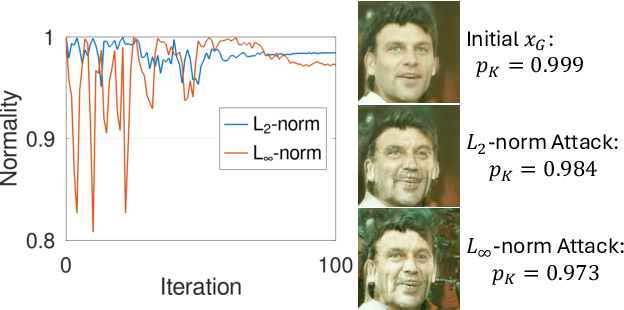
Facial recognition technology poses significant privacy risks, as it relies on biometric data that is inherently sensitive and immutable if compromised. To mitigate these concerns, face recognition systems convert raw images into embeddings, traditionally considered privacy-preserving. However, model inversion attacks pose a significant privacy threat by reconstructing these private facial images, making them a crucial tool for evaluating the privacy risks of face recognition systems. Existing methods usually require training individual generators for each target model, a computationally expensive process. In this paper, we propose DiffUMI, a training-free diffusion-driven universal model inversion attack for face recognition systems. DiffUMI is the first approach to apply a diffusion model for unconditional image generation in model inversion. Unlike other methods, DiffUMI is universal, eliminating the need for training target-specific generators. It operates within a fixed framework and pretrained diffusion model while seamlessly adapting to diverse target identities and models. DiffUMI breaches privacy-preserving face recognition systems with state-of-the-art success, demonstrating that an unconditional diffusion model, coupled with optimized adversarial search, enables efficient and high-fidelity facial reconstruction. Additionally, we introduce a novel application of out-of-domain detection (OODD), marking the first use of model inversion to distinguish non-face inputs from face inputs based solely on embeddings.
Adversarial Masked Autoencoder Purifier with Defense Transferability
Jan 28, 2025



The study of adversarial defense still struggles to combat with advanced adversarial attacks. In contrast to most prior studies that rely on the diffusion model for test-time defense to remarkably increase the inference time, we propose Masked AutoEncoder Purifier (MAEP), which integrates Masked AutoEncoder (MAE) into an adversarial purifier framework for test-time purification. While MAEP achieves promising adversarial robustness, it particularly features model defense transferability and attack generalization without relying on using additional data that is different from the training dataset. To our knowledge, MAEP is the first study of adversarial purifier based on MAE. Extensive experimental results demonstrate that our method can not only maintain clear accuracy with only a slight drop but also exhibit a close gap between the clean and robust accuracy. Notably, MAEP trained on CIFAR10 achieves state-of-the-art performance even when tested directly on ImageNet, outperforming existing diffusion-based models trained specifically on ImageNet.
GreedyPixel: Fine-Grained Black-Box Adversarial Attack Via Greedy Algorithm
Jan 24, 2025A critical requirement for deep learning models is ensuring their robustness against adversarial attacks. These attacks commonly introduce noticeable perturbations, compromising the visual fidelity of adversarial examples. Another key challenge is that while white-box algorithms can generate effective adversarial perturbations, they require access to the model gradients, limiting their practicality in many real-world scenarios. Existing attack mechanisms struggle to achieve similar efficacy without access to these gradients. In this paper, we introduce GreedyPixel, a novel pixel-wise greedy algorithm designed to generate high-quality adversarial examples using only query-based feedback from the target model. GreedyPixel improves computational efficiency in what is typically a brute-force process by perturbing individual pixels in sequence, guided by a pixel-wise priority map. This priority map is constructed by ranking gradients obtained from a surrogate model, providing a structured path for perturbation. Our results demonstrate that GreedyPixel achieves attack success rates comparable to white-box methods without the need for gradient information, and surpasses existing algorithms in black-box settings, offering higher success rates, reduced computational time, and imperceptible perturbations. These findings underscore the advantages of GreedyPixel in terms of attack efficacy, time efficiency, and visual quality.
Test-time Adversarial Defense with Opposite Adversarial Path and High Attack Time Cost
Oct 22, 2024



Deep learning models are known to be vulnerable to adversarial attacks by injecting sophisticated designed perturbations to input data. Training-time defenses still exhibit a significant performance gap between natural accuracy and robust accuracy. In this paper, we investigate a new test-time adversarial defense method via diffusion-based recovery along opposite adversarial paths (OAPs). We present a purifier that can be plugged into a pre-trained model to resist adversarial attacks. Different from prior arts, the key idea is excessive denoising or purification by integrating the opposite adversarial direction with reverse diffusion to push the input image further toward the opposite adversarial direction. For the first time, we also exemplify the pitfall of conducting AutoAttack (Rand) for diffusion-based defense methods. Through the lens of time complexity, we examine the trade-off between the effectiveness of adaptive attack and its computation complexity against our defense. Experimental evaluation along with time cost analysis verifies the effectiveness of the proposed method.
Adversarial Robustness Overestimation and Instability in TRADES
Oct 10, 2024



This paper examines the phenomenon of probabilistic robustness overestimation in TRADES, a prominent adversarial training method. Our study reveals that TRADES sometimes yields disproportionately high PGD validation accuracy compared to the AutoAttack testing accuracy in the multiclass classification task. This discrepancy highlights a significant overestimation of robustness for these instances, potentially linked to gradient masking. We further analyze the parameters contributing to unstable models that lead to overestimation. Our findings indicate that smaller batch sizes, lower beta values (which control the weight of the robust loss term in TRADES), larger learning rates, and higher class complexity (e.g., CIFAR-100 versus CIFAR-10) are associated with an increased likelihood of robustness overestimation. By examining metrics such as the First-Order Stationary Condition (FOSC), inner-maximization, and gradient information, we identify the underlying cause of this phenomenon as gradient masking and provide insights into it. Furthermore, our experiments show that certain unstable training instances may return to a state without robust overestimation, inspiring our attempts at a solution. In addition to adjusting parameter settings to reduce instability or retraining when overestimation occurs, we recommend incorporating Gaussian noise in inputs when the FOSC score exceed the threshold. This method aims to mitigate robustness overestimation of TRADES and other similar methods at its source, ensuring more reliable representation of adversarial robustness during evaluation.
Information-Theoretical Principled Trade-off between Jailbreakability and Stealthiness on Vision Language Models
Oct 02, 2024



In recent years, Vision-Language Models (VLMs) have demonstrated significant advancements in artificial intelligence, transforming tasks across various domains. Despite their capabilities, these models are susceptible to jailbreak attacks, which can compromise their safety and reliability. This paper explores the trade-off between jailbreakability and stealthiness in VLMs, presenting a novel algorithm to detect non-stealthy jailbreak attacks and enhance model robustness. We introduce a stealthiness-aware jailbreak attack using diffusion models, highlighting the challenge of detecting AI-generated content. Our approach leverages Fano's inequality to elucidate the relationship between attack success rates and stealthiness scores, providing an explainable framework for evaluating these threats. Our contributions aim to fortify AI systems against sophisticated attacks, ensuring their outputs remain aligned with ethical standards and user expectations.
Exploring Robustness of Visual State Space model against Backdoor Attacks
Aug 22, 2024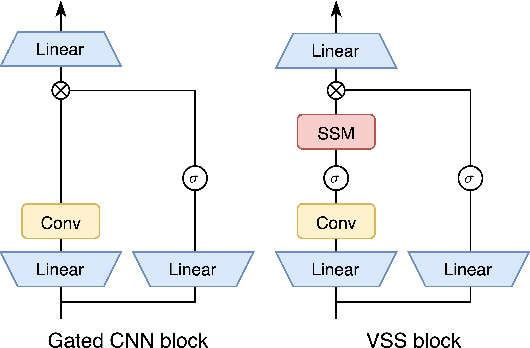
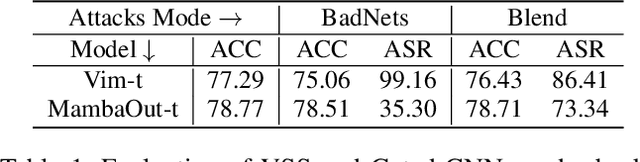

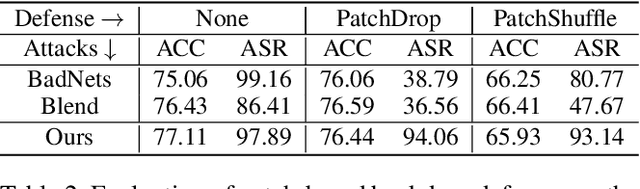
Visual State Space Model (VSS) has demonstrated remarkable performance in various computer vision tasks. However, in the process of development, backdoor attacks have brought severe challenges to security. Such attacks cause an infected model to predict target labels when a specific trigger is activated, while the model behaves normally on benign samples. In this paper, we conduct systematic experiments to comprehend on robustness of VSS through the lens of backdoor attacks, specifically how the state space model (SSM) mechanism affects robustness. We first investigate the vulnerability of VSS to different backdoor triggers and reveal that the SSM mechanism, which captures contextual information within patches, makes the VSS model more susceptible to backdoor triggers compared to models without SSM. Furthermore, we analyze the sensitivity of the VSS model to patch processing techniques and discover that these triggers are effectively disrupted. Based on these observations, we consider an effective backdoor for the VSS model that recurs in each patch to resist patch perturbations. Extensive experiments across three datasets and various backdoor attacks reveal that the VSS model performs comparably to Transformers (ViTs) but is less robust than the Gated CNNs, which comprise only stacked Gated CNN blocks without SSM.
LookupForensics: A Large-Scale Multi-Task Dataset for Multi-Phase Image-Based Fact Verification
Jul 26, 2024



Amid the proliferation of forged images, notably the tsunami of deepfake content, extensive research has been conducted on using artificial intelligence (AI) to identify forged content in the face of continuing advancements in counterfeiting technologies. We have investigated the use of AI to provide the original authentic image after deepfake detection, which we believe is a reliable and persuasive solution. We call this "image-based automated fact verification," a name that originated from a text-based fact-checking system used by journalists. We have developed a two-phase open framework that integrates detection and retrieval components. Additionally, inspired by a dataset proposed by Meta Fundamental AI Research, we further constructed a large-scale dataset that is specifically designed for this task. This dataset simulates real-world conditions and includes both content-preserving and content-aware manipulations that present a range of difficulty levels and have potential for ongoing research. This multi-task dataset is fully annotated, enabling it to be utilized for sub-tasks within the forgery identification and fact retrieval domains. This paper makes two main contributions: (1) We introduce a new task, "image-based automated fact verification," and present a novel two-phase open framework combining "forgery identification" and "fact retrieval." (2) We present a large-scale dataset tailored for this new task that features various hand-crafted image edits and machine learning-driven manipulations, with extensive annotations suitable for various sub-tasks. Extensive experimental results validate its practicality for fact verification research and clarify its difficulty levels for various sub-tasks.