 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Theoretical Principled Trade-off between Jailbreakability and Stealthiness on Vision Language Models
Oct 02, 2024



In recent years, Vision-Language Models (VLMs) have demonstrated significant advancements in artificial intelligence, transforming tasks across various domains. Despite their capabilities, these models are susceptible to jailbreak attacks, which can compromise their safety and reliability. This paper explores the trade-off between jailbreakability and stealthiness in VLMs, presenting a novel algorithm to detect non-stealthy jailbreak attacks and enhance model robustness. We introduce a stealthiness-aware jailbreak attack using diffusion models, highlighting the challenge of detecting AI-generated content. Our approach leverages Fano's inequality to elucidate the relationship between attack success rates and stealthiness scores, providing an explainable framework for evaluating these threats. Our contributions aim to fortify AI systems against sophisticated attacks, ensuring their outputs remain aligned with ethical standards and user expectations.
Defending Against Repetitive-based Backdoor Attacks on Semi-supervised Learning through Lens of Rate-Distortion-Perception Trade-off
Jul 14, 2024Semi-supervised learning (SSL) has achieved remarkable performance with a small fraction of labeled data by leveraging vast amounts of unlabeled data from the Internet. However, this large pool of untrusted data is extremely vulnerable to data poisoning, leading to potential backdoor attacks. Current backdoor defenses are not yet effective against such a vulnerability in SSL. In this study, we propose a novel method, Unlabeled Data Purification (UPure), to disrupt the association between trigger patterns and target classes by introducing perturbations in the frequency domain. By leveraging the Rate- Distortion-Perception (RDP) trade-off, we further identify the frequency band, where the perturbations are added, and justify this selection. Notably, UPure purifies poisoned unlabeled data without the need of extra clean labeled data. Extensive experiments on four benchmark datasets and five SSL algorithms demonstrate that UPure effectively reduces the attack success rate from 99.78% to 0% while maintaining model accuracy
Deterministic Certification to Adversarial Attacks via Bernstein Polynomial Approximation
Nov 28, 2020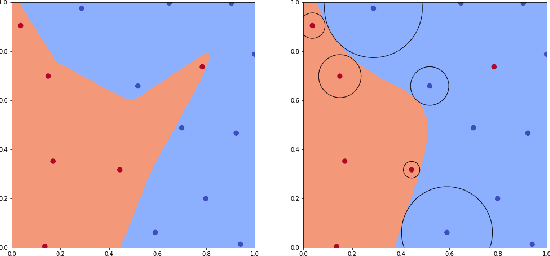



Randomized smoothing has established state-of-the-art provable robustness against $\ell_2$ norm adversarial attacks with high probability. However, the introduced Gaussian data augmentation causes a severe decrease in natural accuracy. We come up with a question, "Is it possible to construct a smoothed classifier without randomization while maintaining natural accuracy?". We find the answer is definitely yes. We study how to transform any classifier into a certified robust classifier based on a popular and elegant mathematical tool, Bernstein polynomial. Our method provides a deterministic algorithm for decision boundary smoothing. We also introduce a distinctive approach of norm-independent certified robustness via numerical solutions of nonlinear systems of equations. Theoretical analyses and experimental results indicate that our method is promising for classifier smoothing and robustness certification.